Streaming ETL pipelines in Python with Airbyte and Pathway
 Sergey Kulik
Sergey KulikStreaming ETL pipelines in Python with Airbyte and Pathway
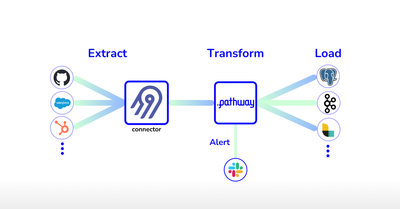
In the world of data management, the Extract, Transform, Load (ETL) process plays a crucial role in handling information effectively. ETL involves three key steps: first, extracting data from different sources; next, transforming it to fit specific needs and standards; and finally, loading it into a destination where it can be analyzed and used for decision-making. As businesses increasingly rely on data for insights, mastering the ETL process becomes essential for maximizing the value of information.
ETL is particularly useful when you don't want to store raw data directly in your warehouse. For example, the personally identifiable information (PII) and sensitive data need to be anonymized before being loaded and analyzed. ETL allows you to process your data, sanitize it, and anonymize it before sending it for further analysis.
In this article, you will see how to combine the Pathway Live Data Framework with Airbyte to do a streaming ETL pipeline.
Airbyte is an open-source data integration platform designed to simplify the process of moving and consolidating data from various sources to data warehouses or other destinations with 350+ input connectors. It is used for the extract step. On the other hand, the Pathway Live Data Framework is a fast and easy event-processing engine built for Python & ML/AI developers: it will transform and load the data.
This tutorial will show you how to process the data stream from an Airbyte source with the Pathway Live Data Framework. You will learn how to set up the extraction of an Airbyte data source with airbyte-serverless, how to transform it real-time with the Pathway Live Data Framework, and finally, how to load the transformed stream into the storage.

For the demonstration, imagine you have the following task: you need to fetch the commits from a given GitHub repository in real-time, with a lag of seconds. Then, you need to process this real-time stream of commits by removing all e-mails from the obtained payloads. Actually, with Pathway, you are not restricted to just filtering some of the data, but you can do joins, use machine learning models, and much more if your task is more complex.
Setting up Airbyte sources with airbyte-serverless
First of all, you need to start reading the stream of commits from the repository. Here you can pick Pathway source code. To read this repository, the GitHub connector provided by Airbyte can be used.
To configure it, you first need to install the airbyte-serverless tool from pip:
pip install airbyte-serverless
Note that the use of
airbyte-serverlessrequires to have Docker installed.
Configuration
Here, we provide two options, you can see the following instructions for the pre-configured template that reads the commits from the Pathway repository. Or, you can skip to the Manual Configuration section below to see how to modify the source config manually.
Predefined Configuration
Create a YAML file in the following path: /connections/github.yaml. Then, copy and paste the following template into the file.
You need to set the personal_access_token in this template. This can be obtained at the Tokens page in GitHub - please note that you need to be logged in. The scope you need in this token is public_repo (Access public repositories).
source:
docker_image: "airbyte/source-github" # Here the airbyte connector type is specified
config:
credentials:
option_title: "PAT Credentials" # The second authentication option you've uncommented
personal_access_token: <YOUR PERSONAL ACCESS TOKEN HERE> # Taken from https://github.com/settings/tokens
repositories:
- pathwaycom/pathway # Pathway repository
api_url: "https://api.github.com/"
streams: commits
This template is configured to read the commits in the pathway repository with your GitHub access token.
Manual Configuration (Optional)
The configuration of the Airbyte source depends on the source: each source requires its own set of parameters, tokens, and keys. So, the next step is to generate the template with the configuration for the GitHub source. It can be done with the following console command:
abs create github --source "airbyte/source-github"
The file ./connections/github.yaml now contains the created configuration template.
**You now need to fill in the template for the connector to read the repository. **
**If you don't modify the config and remove the unused fields, airbyte will raise an error. **
This configuration can be done as follows.
First, there are two authentication ways to select from. Let's configure the simpler one: PAT authorization. To do that, you need to remove the uncommented option_title, access_token, client_id, and client_secret fields in the config, and then uncomment the section "Another valid structure for credentials". It requires the PAT token, which can be obtained at the Tokens page in GitHub - please note that you need to be logged in. The scope you need in this token is public_repo (Access public repositories).
Then, you also need to set up the repository name in the repositories field. As decided before, it's the Pathway source code repository, located at pathwaycom/pathway. Finally, you need to remove the unused optional fields, and you're ready to go. For more information about configurations, check out Airbyte GitHub documentation.
Using Airbyte connectors from Pathway Live Data Framework to extract data
Having the source configuration in place, you can proceed with writing some pipeline code. First of all, you need to import Pathway:
import pathway as pw
Having it imported, you can configure the data source. It's done in the same way as you usually do with other data sources:
commits_table = pw.io.airbyte.read(
"./connections/github.yaml",
streams=["commits"],
)
Here, only two parameters need to be specified: the path to the configuration file and the list of Airbyte streams you want to read. In the GitHub connector, the commits data is provided in the stream named commits, as it's specified above.
Please note that this code will run indefinitely, fetching the new commits when they are made and appending them into the commits_table. There is also a way to run this code so that it reads the list of commits that exist at present and terminates, without waiting for the new ones. To do that, you need to set the keyword argument mode of the method pw.io.airbyte.read to "static".
In addition, you can control how frequently the read method polls the new data from the source. This frequency is denoted by the parameter refresh_interval_ms, defaulting at 1000, hence giving the poll frequency of one second.
Transforming data streams with Pathway Live Data Framework
Now you have the stream of commits in the form of a Pathway Live Data Framework table. Let's process it with the means the framework has.
As stated before, it's needed to remove the e-mails from the payload. Since the payload from the Airbyte Github connector is a JSON, one can come up with the following simple algorithm for personal data removal: traverse this JSON with a simple depth-first method, and any time there is an @ character within a group of non-whitespace characters, remove this non-empty group. We do it this way to keep the approach simple while having the goal of removing all e-mails with the maximum recall, so that there is absolutely no PII:
This way, the removal code would look as follows:
import json
def remove_emails_from_data(payload):
if isinstance(payload, str):
# The string case is obvious: it's getting split and then merged back after
# the email-like substrings are removed
return " ".join([item for item in payload.split(" ") if "@" not in item])
if isinstance(payload, list):
# If the payload is a list, one needs to remove emails from each of its
# elements and then return the result of the processing
result = []
for item in payload:
result.append(remove_emails_from_data(item))
return result
if isinstance(payload, dict):
# If the payload is a dict, one needs to remove emails from its keys and
# values and then return the clean dict
result = {}
for key, value in payload.items():
# There are no e-mails in the keys of the returned dict
# So, we only need to remove them from values
value = remove_emails_from_data(value)
result[key] = value
return result
# If the payload is neither str nor list or dict, it's a primitive type:
# namely, a boolean, a float, or an int. It can also be just null.
#
# But in any case, there is no data to remove from such an element.
return payload
The transformation is done entirely in Python, there are no calls to a framework function. To apply it to the table, you need to use pw.apply:
def remove_emails(raw_commit_data: pw.Json) -> pw.Json:
# First, parse pw.Json type into a Python dict
data = json.loads(raw_commit_data.as_str())
# Next, just apply the recursive method to delete e-mails
return remove_emails_from_data(data)
commits_table = commits_table.select(data=pw.apply(remove_emails, pw.this.data))
Now the commits_table contains the data without such personal information as e-mails.
Loading data with Pathway Live Data Framework connectors
Finally, you can output the data. To do so, you can pick any of the output connectors the Pathway Live Data Framework has.
There are plenty options available. Some of them are:
- A topic in Kafka;
- An endpoint in Logstash;
- A table in Postgres;
- And even a Python callback.
Of course, there is a simple disk storage option as well. For instance, you can use the jsonlines output connector to write to a local file:
pw.io.jsonlines.write(commits_table, "commits.jsonlines")
This would output the results in the file commits.jsonlines.
Finally, don't forget to run!
pw.run()
This is it! Now, your data is anonymized on the fly and stored in the file. This is only a simple example of what you can do with the variety of Airbyte sources and the freedom of real-time pipelines in the Pathway Live Data Framework. Note that it extends the number of sources you can use by virtually all available sources: there are 350+ to try!

 Sergey Kulik
Sergey Kulik showcase · data-pipelineMay 15, 2025How La Poste uses Pathway microservices to deliver high-quality ETAs
showcase · data-pipelineMay 15, 2025How La Poste uses Pathway microservices to deliver high-quality ETAs Szymon Dudycz
Szymon Dudycz showcase · llm · engineeringMay 18, 2024Langchain and Pathway: RAG Apps with always-up-to-date knowledge
showcase · llm · engineeringMay 18, 2024Langchain and Pathway: RAG Apps with always-up-to-date knowledge Pathway Teamshowcase · llm · case-study · engineeringJan 12, 2024LlamaIndex and Pathway: RAG Apps with always-up-to-date knowledge
Pathway Teamshowcase · llm · case-study · engineeringJan 12, 2024LlamaIndex and Pathway: RAG Apps with always-up-to-date knowledge