Pathway Live Data Framework Templates
Pathway Live Data Framework's Application templates allow you to quickly put into production AI and ETL applications which offer high-accuracy RAG at scale using the most up-to-date knowledge available in your data sources.
The Pathway Live Data Framework Templates are ready-to-deploy ETL and RAG pipelines built on the Pathway Live Data Framework, offering scalable, real-time data processing and AI-driven search capabilities through YAML and Python templates. They are designed for easy deployment and customization by both developers and non-developers. Get started by picking a template or visiting the Run a Template page.
Pick one and run the app with your own data, in minutes.
RAG Templates



YAML
Question-Answering RAG App
Basic end-to-end RAG app. A question-answering pipeline that uses the GPT model of choice to provide answers to queries to your documents (PDF, DOCX,...) on a live connected data source (files, Google Drive, Sharepoint,...).
Basic end-to-end RAG app. A question-answering pipeline that uses the GPT model of choice to provide answers to queries to your documents (PDF, DOCX,...) on a live connected data source (files, Google Drive, Sharepoint,...).
Featured
YAML
Adaptive RAG App
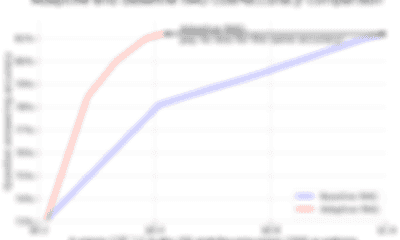
A RAG application using Adaptive RAG, a technique developed by Pathway to reduce token cost in RAG up to 4x while maintaining accuracy.
A RAG application using Adaptive RAG, a technique developed by Pathway to reduce token cost in RAG up to 4x while maintaining accuracy.
YAML
Private RAG App with Mistral and Ollama
A fully private (local) version of the Question-Answering RAG pipeline using Pathway, Mistral, and Ollama.
A fully private (local) version of the Question-Answering RAG pipeline using Pathway, Mistral, and Ollama.
YAML
Multimodal RAG pipeline with GPT4o
Multimodal RAG using GPT-4o in the parsing stage to index PDFs and other documents from a connected data source files, Google Drive, Sharepoint,...). It is perfect for extracting information from unstructured financial documents in your folders (including charts and tables), updating results as documents change or new ones arrive.
Multimodal RAG using GPT-4o in the parsing stage to index PDFs and other documents from a connected data source files, Google Drive, Sharepoint,...). It is perfect for extracting information from unstructured financial documents in your folders (including charts and tables), updating results as documents change or new ones arrive.
Featured
YAML
Live Document Indexing (Vector Store / Retriever)
A real-time document indexing pipeline for RAG that acts as a vector store service. It performs live indexing on your documents (PDF, DOCX,...) from a connected data source (files, Google Drive, Sharepoint,...). It can be used with any frontend, or integrated as a retriever backend for a Langchain or Llamaindex application.
A real-time document indexing pipeline for RAG that acts as a vector store service. It performs live indexing on your documents (PDF, DOCX,...) from a connected data source (files, Google Drive, Sharepoint,...). It can be used with any frontend, or integrated as a retriever backend for a Langchain or Llamaindex application.
YAML
Slides AI Search App
An indexing pipeline for retrieving slides. It performs multi-modal of PowerPoint and PDF and maintains live index of your slides.
An indexing pipeline for retrieving slides. It performs multi-modal of PowerPoint and PDF and maintains live index of your slides.
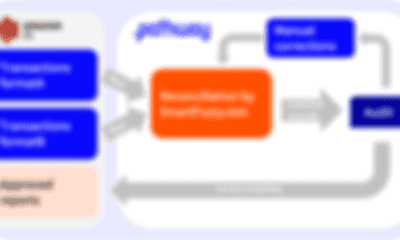
Pathway Live Data Framework + PostgreSQL + LLM: app for querying financial reports with live document structuring pipeline.
A RAG example which connects to unstructured financial data sources (financial report PDFs), structures the data into SQL, and loads it into a PostgreSQL table. It also answers natural language user queries to these financial documents by translating them into SQL using an LLM and executing the query on the PostgreSQL table.
A RAG example which connects to unstructured financial data sources (financial report PDFs), structures the data into SQL, and loads it into a PostgreSQL table. It also answers natural language user queries to these financial documents by translating them into SQL using an LLM and executing the query on the PostgreSQL table.