Private RAG with Connected Data Sources using Mistral, Ollama, and Pathway

Retrieval-Augmented Generation (RAG) is a powerful way to answer questions based on your own, private, knowledge database. However, data security is key: sensitive information like trade secrets, confidential IP, GDPR-protected data, and internal documents that cannot be entrusted to third parties.
Most of the existing RAG solutions rely on LLM APIs that send your data, or at least a part of it, to the LLM provider. For example, if your RAG solution uses ChatGPT, you will have to send your data to OpenAI through OpenAI API.
Fortunately, there is a solution to keep your data private: deploying a local LLM. By deploying everything locally, your data remains secure within your own infrastructure. This eliminates the risk of sensitive information ever leaving your control.
While this seems quite an engineering feat, don't worry. Pathway and Ollama provide you with everything you need to make this as easy as possible.
In this showcase, you will learn how to set up a private RAG pipeline with adaptive retrieval using Pathway, Mistral, and Ollama. The pipeline answers questions from the Stanford Question Answering Dataset (SQUAD) using a selection of Wikipedia pages from the same dataset as the context, split into paragraphs. This RAG pipeline runs without any API access or any data leaving the local machine with Pathway.
The architecture consists of two connected technology bricks, which will run as services on your machine:
- Pathway brings support for real-time data synchronization pipelines out of the box, and the possibility of secure private document handling with enterprise connectors for synchronizing Sharepoint and Google Drive incrementally. The Pathway service we run will perform our live document indexing pipeline, and will use Pathway’s built-in vector store.
- The language model we use will be a Mistral 7B, which we will locally deploy as an Ollama service. This model was chosen for its performance and compact size.
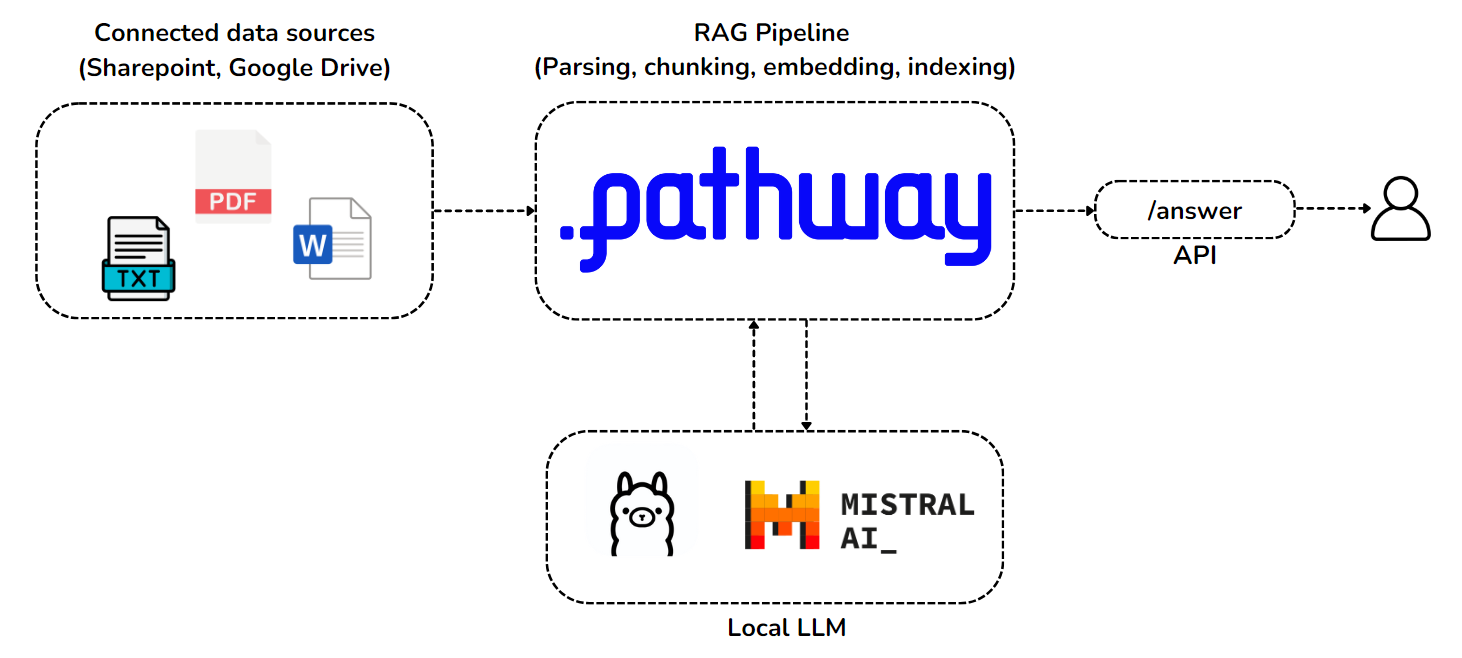
You will explore how to use Pathway to:
- connect a document source
- perform document indexing
- connect to our local LLM
- prompt our LLM with relevant context, and adaptively add more documents as needed
- combine everything, and orchestrate the RAG pipeline with Pathway.
If you are not familiar with the Pathway yet, you can refer to the overview of Pathway's LLM xpack and its documentation.
What is Private RAG and Why Do You Need It?
Most of the RAG applications require you to send your documents & data to propriety APIs. This is a concern for most organizations as data privacy with sensitive documents becomes an issue. Generally, you need to send your documents during the indexing and LLM question-answering stages.
To tackle this, you can use a private RAG: locally deployed LLMs and embedders in your RAG pipeline.
Why use Local LLMs?
There are several advantages to using local LLMs (Large Language Models) over cloud-based APIs:
- Data Privacy: Local LLMs keep your sensitive data on your machines.
- Accuracy: Cloud-based LLM accuracy is not always optimal and can also sometimes regress during upgrades, whereas local models provide predictable performance and can also be fine-tuned for better accuracy.
- Customization: Local LLMs fine-tuning allows you to achieve specific behaviors or domain adaptation.
Mistral and Ollama for privacy
Mistral 7B is publicly available LLM model release by Mistral AI. Its (relative) small size of 7.3B parameters and impressive performances make Mistral 7B a perfect candidate for a local deployment.
The pipeline relies on Ollama to deploy the Mistral 7B model. Ollama is a tool to create, manage, and run LLM models. Ollama is used to download and configure locally the Mistral 7B model.
Private RAG with Pathway
This section provides a step-by-step guide on how to set up Private RAG with Adaptive Retrieval using Pathway, a framework for building LLM applications. The guide covers:
- Installation: Installing Pathway and required libraries.
- Data Loading: Loading documents for which answer retrieval will be performed.
- Embedding Model Selection: Choosing an open-source embedding model from Hugging Face.
- Local LLM Deployment: Instructions on deploying a local LLM using Ollama, a lightweight container runtime.
- LLM Initialization: Setting up the LLM instance to interact with the local model.
- Vector Document Index Creation: Building an index for efficient document retrieval using the embedding model.
- Retriever setup: Defining the parameters for the context retrieval strategy for queries made to the RAG system.
- Pipeline Execution: Running the Private RAG pipeline with your data.
1. Installation
You install Pathway into a Python 3.10+ Linux runtime with a simple pip command:
!pip install -U --prefer-binary pathway
We also install LiteLLM - a library of helpful Python wrappers for calling into our LLM. With it, we can later easily change our LLM without rewriting a lot of code.
!pip install "litellm>=1.35"
Lastly, we install Sentence-Transformers for embedding the chunked texts.
!pip install sentence-transformers
2. Data Loading
We will start by testing our solution with a static sample of knowledge data. We have prepared a sample for download for use in the adaptive-rag-contexts.jsonl file, with ~1000 contexts from the SQUAD dataset, taken from Wikipedia texts.
!wget -q -nc https://public-pathway-releases.s3.eu-central-1.amazonaws.com/data/adaptive-rag-contexts.jsonl
Next, let’s do the necessary imports.
import pandas as pd
import pathway as pw
from pathway.stdlib.indexing import default_vector_document_index
from pathway.xpacks.llm import embedders
from pathway.xpacks.llm.llms import LiteLLMChat
from pathway.xpacks.llm.question_answering import (
answer_with_geometric_rag_strategy_from_index,
)
class InputSchema(pw.Schema):
doc: str
documents = pw.io.fs.read(
"adaptive-rag-contexts.jsonl",
format="json",
schema=InputSchema,
json_field_paths={"doc": "/context"},
mode="static",
)
When testing during development, we can run this code in a "static" way and check if all the sources are correctly loaded. Later, in production, the Pathway service running our code will know how to refresh the loaded documents when new data arrives.
df = pd.DataFrame(
{
"query": [
"When it is burned what does hydrogen make?",
"What was undertaken in 2010 to determine where dogs originated from?",
# "What did Arnold's journey into politics look like?",
]
}
)
query = pw.debug.table_from_pandas(df)
3. Embedding Model Selection
We use pathway.xpacks.llm.embedders module to load open-source embedding models from the HuggingFace model library. For our showcase, we pick the avsolatorio/GIST-small-Embedding-v0 model which has a dimension of 384.
embedding_model = "avsolatorio/GIST-small-Embedding-v0"
embedder = embedders.SentenceTransformerEmbedder(
embedding_model, call_kwargs={"show_progress_bar": False}
) # disable verbose logs
embedding_dimension: int = embedder.get_embedding_dimension()
print("Embedding dimension:", embedding_dimension)
Embedding dimension: 384
We have picked the avsolatorio/GIST-small-Embedding-v0 model as it is compact and performed well in our tests. If you would like to use a higher-dimensional model, here are some possible alternatives you could use instead:
mixedbread-ai/mxbai-embed-large-v1avsolatorio/GIST-Embedding-v0
For other possible choices, take a look at the MTEB Leaderboard managed by HuggingFace.
Model embedding can take some CPU power. In case you have access to limited computation on your development machines, for tests, you can also start by using an embedder service over public API. For example, Mistral offers such a service - to use it, instead of the local embedding code above, you would uncomment the following API code.
4. Local LLM Deployement
Due to its size and performance we decided to run the Mistral 7B Local Language Model. We deploy it as a service running on GPU, using Ollama.
In order to run local LLM, refer to these steps:
- Download Ollama from ollama.com/download
- In your terminal, run
ollama serve - In another terminal, run
ollama run mistral
You can now test it with the following:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt":"Here is a story about llamas eating grass"
}'
Notice that here we are working on localhost. You could potentially run the Ollama and Pathway services on different machines as the RAG pipeline and LLM will communicate over API. We will not do it in this showcase, but you may consider such a possibility, for example, to run just one LLM service on a single GPU, and then connect multiple RAG pipelines running on different virtual machines to it.
5. LLM Initialization
We now initialize the LLM instance that will call our local model.
model = LiteLLMChat(
model="ollama/mistral",
temperature=0,
top_p=1,
api_base="http://localhost:11434", # local deployment
format="json", # only available in Ollama local deploy, do not use in Mistral API
)
In the above, by putting format="json" we specifically instructed LLM to return outputs in json format. In this format, the LLM follows instructions more strictly. This is only needed for some LLM's; for example, we would not need it if we used mistral-large, or GPT-4.
6. Vector Document Index Creation
We continue our pipeline code to specify the index with documents and embedding model to use when processing documents.
index = default_vector_document_index(
documents.doc, documents, embedder=embedder, dimensions=embedding_dimension
)
7. Retriever setup
Here, we specify to our Pathway service how to retrieve relevant context from the vector index for a user query. Pathway offers several retrieval strategies to choose from, which offer a lot of flexibility in configuring e.g. how many of the relevant chunks to retrieve into the LLM’s context, and in what order to rank them.
A simple choice could be to pick the top-k retriever, which retrieves the top k chunks most relevant to a query, like this (for example, we could ask to retrieve k=10 chunks) and answer questions based on these chunks.
Here, let’s take full advantage of what Pathway has to offer, and take a smarter top-k retriever called Adaptive RAG which adapts the number of chunks k as needed, by asking the LLM if it has received enough context already or still needs more. It’s just a single line to set up the hyperparameters, and in practice, this will often make your local LLM reply faster, sometimes consuming even 4x less tokens.
result = query.select(
question=query.query,
result=answer_with_geometric_rag_strategy_from_index(
query.query,
index,
documents.doc,
model,
n_starting_documents=2,
factor=2,
max_iterations=4,
strict_prompt=True, # needed for open source models, instructs LLM to give JSON output strictly
),
)
8. Pipeline Execution
When testing locally, you can run the pipeline once and print the results table with pw.debug.compute_and_print. Remember the questions we put originally in the query table? (They were: “When it is burned what does hydrogen make?", "What was undertaken in 2010 to determine where dogs originated from?"). Now, we are ready to get the answers based on all the knowledge in our current dataset:
pw.debug.compute_and_print(result)
Hydrogen makes water when burned [2].
Extensive genetic studies were conducted during the 2010s which indicated that dogs diverged from an extinct wolf-like canid in Eurasia around 40,000 years ago.
Now you have a fully private RAG set up with Pathway and Ollama. All your data remains safe on your system. Moreover, the set-up is optimized for speed, thanks to how Ollama runs the LLM, and how Pathway’s adaptive retrieval mechanism reduces token consumption while preserving the accuracy of the RAG.
We can now go further by building and deploying your RAG application in production with Pathway, including updating data in constant connection with data sources and serving the endpoints 24/7. All the code logic we have built so far can be used directly!
For a full production-ready set-up, we have built a slightly larger RAG application demonstrator which also includes reading your data sources, parsing the data, and serving the endpoint. To get started, check it out here. You will find easy-to-follow setup instructions in our question answering demo.
Enjoy your fully private RAG application!
In this showcase, you have learned how to design a fully local and private RAG setup, including a local embedder and LLM. We built our RAG pipeline as Python code using Pathway ensuring that the necessary privacy is maintained at every step of the RAG pipeline. We finally showed how to use Pathway to orchestrate our Python code, running a service that incrementally updates our knowledge base as it changes, and answers questions with the LLM.
This private RAG setup can be run entirely locally with open-source LLMs, making it ideal for organizations with sensitive data and eXplainable AI needs. We believe Mistral 7B with Ollama to be a good choice for the local LLM service. Still, in organizations that have already deployed local LLMs differently, the Pathway RAG pipeline may also be used with other models.