Performing Interval Joins in Pathway
This article offers a comprehensive tutorial on how to use the interval join function in Pathway to accurately compute the Estimated Time of Arrival (ETA) for vehicles.
The practice of temporal data analysis often invokes the use of interval joins, which diverge from the conventional join operation by virtue of a more adaptable matching strategy. Rather than linking records from two tables based purely on a precise key match, interval joins offer a compound inequality based linkage.
In essence, the interval join merges records by comparing the timestamp from each record of two tables and evaluates whether the difference falls within a specified time window or interval.
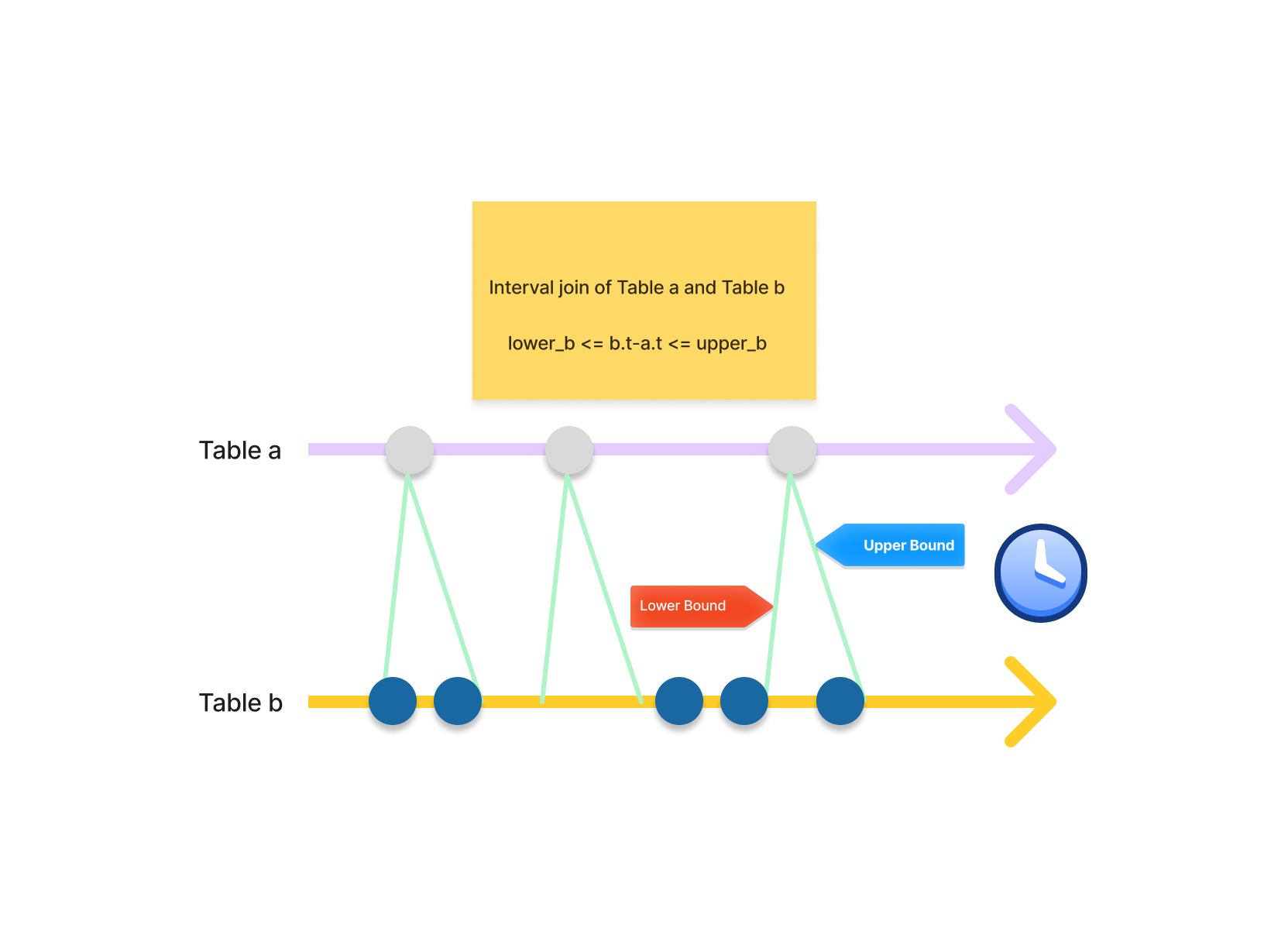
This operation is especially useful in time-series data processing scenarios. For instance, when processing streaming data, data points may not arrive at the system simultaneously due to differences in data production speed, network latency, or other factors. Interval join comes to the rescue by enabling the system to align data points that are closest in time, thus facilitating real-time data analysis and decision-making.
In this tutorial, you will calculate the estimated time of arrival (ETA) for each vehicle in a fleet given its current location, destination, the route it's taking, and any potential route maintenance delays.
1. Setting Up the Tables
Let's start by defining the tables: vehicle locations, routes, and maintenance schedules. For the sake of this tutorial, you could use pw.debug.table_from_markdown function to create tables from markdown formatted string. Please refer to our article about connectors in Pathway to find out more about data connectors. Be assured that this code is compatible with the streaming mode.
import pathway as pw
vehicle_locations = pw.debug.table_from_markdown(
"""
| timestamp | vehicle_id | route_id | current_lat | current_long | dest_lat | dest_long
1 | 1682884074 | 1 | h432af | 12.8716 | 77.5946 | 12.9800 | 77.5950
2 | 1682884300 | 1 | h432af | 12.8717 | 77.5946 | 12.9800 | 77.5950
3 | 1682884801 | 1 | h577dk | 12.8768 | 77.5947 | 12.9800 | 77.5950
4 | 1682885003 | 1 | h577dk | 12.8829 | 77.5947 | 12.9800 | 77.5950
5 | 1682992012 | 2 | h120cc | 10.4601 | 78.0937 | 10.4532 | 78.0987
6 | 1682992274 | 2 | h120cc | 10.4600 | 78.0948 | 10.4532 | 78.0987
7 | 1682992674 | 2 | h120cc | 10.4595 | 78.0959 | 10.4532 | 78.0987"""
)
routes = pw.debug.table_from_markdown(
"""
| route_id | traffic_speed_km_per_h
1 | h120cc | 60
2 | h432af | 40
3 | h577dk | 80
"""
)
# Create a maintenance data table
maintenance = pw.debug.table_from_markdown(
"""
| route_id | start_time | delay_minutes
1 | h120cc | 1682992274 | 30
2 | g392rt | 1682884441 | 20
3 | h577dk | 1682885777 | 10
"""
)
2. Calculating Distance
To compute the geodesic distance between the vehicle's current location and its destination, a function calculate_distance is defined.
If you don't have the geopy package, you can uncomment and execute the following cell:
%%capture --no-display
#!pip install geopy
from geopy.distance import geodesic
def calculate_distance(
current_lat: float, current_long: float, dest_lat: float, dest_long: float
) -> float:
current_location = (current_lat, current_long)
destination = (dest_lat, dest_long)
return geodesic(current_location, destination).km
Apply this function to the table:
vehicle_locations += vehicle_locations.select(
distance_km=pw.apply(
calculate_distance,
**vehicle_locations[["current_lat", "current_long", "dest_lat", "dest_long"]]
),
)
pw.debug.compute_and_print(vehicle_locations[["distance_km"]])
| distance_km
^6A0QZMJ... | 0.761296229289714
^A984WV0... | 0.8648988130993015
^3S2X6B2... | 0.9392333321427617
^3HN31E1... | 10.742213096795222
^3CZ78B4... | 11.417049942736774
^Z3QWT29... | 11.981292208928062
^YYY4HAB... | 11.992355076407808
3. Performing the Interval Join
Pathway has a function called interval_join (resp. interval_join_{outer/left/right}) which you can use to perform the interval join operation. As mentioned earlier, it is a temporal join operation that allows matching elements of a table right whose timestamps fall within a certain time interval relative to the timestamps of left's elements.
Using the left join variant interval_join_left retains records with and without delays, thereby perfectly addressing our current scenario.
For simplicity, we'll make the assumption that maintenance operations are delocalized throughout the routes and they last for a duration of . A delay is incurred only if maintenance event at time has already began and hasn't ended yet at time i.e. or equivalently .
It is possible to add exact conditions on top of the temporal join. Here, you need to also join on the route_id.
The arguments of the interval_join_left:
other: the right side table.self_time_expression: the time column/expression in the left table.other_time_expression: the time column/expression in the right table.interval: where other_time_expression-self_time_expression must be.*on: a list of equality conditions.
maintenance_period_sec = 30 * 60
records = vehicle_locations.interval_join_left(
maintenance,
pw.left.timestamp,
pw.right.start_time,
pw.temporal.interval(-maintenance_period_sec, 0),
pw.left.route_id == pw.right.route_id,
).select(
vehicle_locations.timestamp,
vehicle_locations.vehicle_id,
vehicle_locations.route_id,
vehicle_locations.distance_km,
delay_sec=60.0 * pw.coalesce(pw.right.delay_minutes, 0),
)
pw.debug.compute_and_print(records)
| timestamp | vehicle_id | route_id | distance_km | delay_sec
^FPHH8MS... | 1682884074 | 1 | h432af | 11.992355076407808 | 0.0
^D49HRW2... | 1682884300 | 1 | h432af | 11.981292208928062 | 0.0
^K6GXXRJ... | 1682884801 | 1 | h577dk | 11.417049942736774 | 0.0
^6VD1XEW... | 1682885003 | 1 | h577dk | 10.742213096795222 | 0.0
^3X8GQ9T... | 1682992012 | 2 | h120cc | 0.9392333321427617 | 0.0
^H8FD0SE... | 1682992274 | 2 | h120cc | 0.8648988130993015 | 1800.0
^ZC7D7NX... | 1682992674 | 2 | h120cc | 0.761296229289714 | 1800.0
After joining the tables, all the columns from the left table are kept and filling the missing values in the right table is accomplished using pw.coalesce.
To compute the total delay in seconds for each pair (timestamp, vehicle_id), we perform a groupby and apply the sum reducer on the column delay_sec.
records = records.groupby(records.timestamp, records.vehicle_id,).reduce(
records.timestamp,
records.vehicle_id,
pw.reducers.unique(records.route_id),
pw.reducers.unique(records.distance_km),
delay_sec=pw.reducers.sum(pw.this.delay_sec),
)
pw.debug.compute_and_print(records[["timestamp", "vehicle_id", "delay_sec"]])
| timestamp | vehicle_id | delay_sec
^9N4ZE91... | 1682884074 | 1 | 0.0
^Y4GS4SE... | 1682884300 | 1 | 0.0
^3RGVZ4V... | 1682884801 | 1 | 0.0
^HQFV2X2... | 1682885003 | 1 | 0.0
^0BVH8M7... | 1682992012 | 2 | 0.0
^VDGWA94... | 1682992274 | 2 | 1800.0
^ETV8ACZ... | 1682992674 | 2 | 1800.0
4. Calculating ETA
Next, you're set to do a standard join operation to combine the records and routes based on the common 'route_id' column. An inner join is used, implying that only records that have a match in both the records and routes data will be retained.
records = records.join(routes, pw.left.route_id == pw.right.route_id).select(
pw.left.timestamp,
pw.left.vehicle_id,
pw.left.delay_sec,
pw.left.distance_km,
pw.right.traffic_speed_km_per_h,
)
Let's add the delay in seconds to the timestamp and transform it to datetimes.
Finally, you can calculate ETA considering both the travel time (based on the distance to the destination and the speed of the route) and any maintenance delays:
records += records.select(
eta_sec=pw.this.delay_sec
+ pw.this.distance_km / (pw.this.traffic_speed_km_per_h / 60.0 / 60.0),
)
records += records.select(
eta=(pw.this.timestamp + pw.cast(int, pw.this.eta_sec)).dt.from_timestamp(unit="s"),
)
As your final step, you can clean the output table by keeping the most interesting columns.
output = records[["timestamp", "vehicle_id", "eta"]]
pw.debug.compute_and_print(output)
| timestamp | vehicle_id | eta
^TMZ20WA... | 1682884074 | 1 | 2023-04-30 20:05:53
^TMZ5TWZ... | 1682884300 | 1 | 2023-04-30 20:09:38
^3PTYR3N... | 1682884801 | 1 | 2023-04-30 20:08:34
^3PTYZ0J... | 1682885003 | 1 | 2023-04-30 20:11:26
^04NZ94J... | 1682992012 | 2 | 2023-05-02 01:47:48
^04NWFS5... | 1682992274 | 2 | 2023-05-02 02:22:05
^04NQJCC... | 1682992674 | 2 | 2023-05-02 02:28:39
Arrival estimates are computed for each record. The next logical step involves identifying the most recent estimates from each vehicle. This can be achieved by applying a filter to select the latest timestamps associated with each vehicle. We encourage you to explore this further as part of your learning journey with our tutorial.
Conclusion
In this tutorial, you have learned how to use interval joins in Pathway to handle scenarios where you'd need to join tables based on intervals or timestamps. You have seen how to use these methods to calculate the ETA for vehicles considering their current locations, routes, and any potential maintenance delays. This kind of processing is common in transportation and logistics, and Pathway makes it easy to handle in real time.