Pathway Architecture
Pathway uses Python to conveniently describe the computations to be performed. The computations are then optimized and converted into basic operations executed by the Rust dataflow engine.
Worker architecture
By design, each Pathway worker runs the same dataflow on different subsets (shards, partitions) of the data. This means that every worker (thread or process) runs precisely the same Python script that builds the dataflow and builds the same low-level dataflow to be executed. Workers know their identity, a unique sequential number (ID of the worker), and use it to determine which data shards are their responsibility. Workers selectively read only the data from their partition for supporting data sources, such as a partitioned Kafka topic. For non-partitioned data, a single worker is responsible for reading it and forwarding parts of it to other workers.
Workers communicate with each other as needed (using appropriate methods: shared memory for threads, sockets for processes, and workers on different machines).
Workers send each other data to be processed and exchange progress information. Every node in the dataflow tracks its progress and efficiently (using the topology of the dataflow) notifies its peers when a portion of input data is processed. This is important for consistency: every result produced by Pathway depends on a known prefix of the input data stream.
The basic dataflow design concepts for Pathway follow those laid out in the foundational work of Microsoft Naiad (SOSP 2013 paper). The communication primitives, concepts of time within the system, and in-memory state representation are based on those of Timely + Differential Dataflow.
A broader background on how Pathway relates to other distributed systems and dataflows is provided in the arXiv preprint introducing Pathway.
Architecture diagram
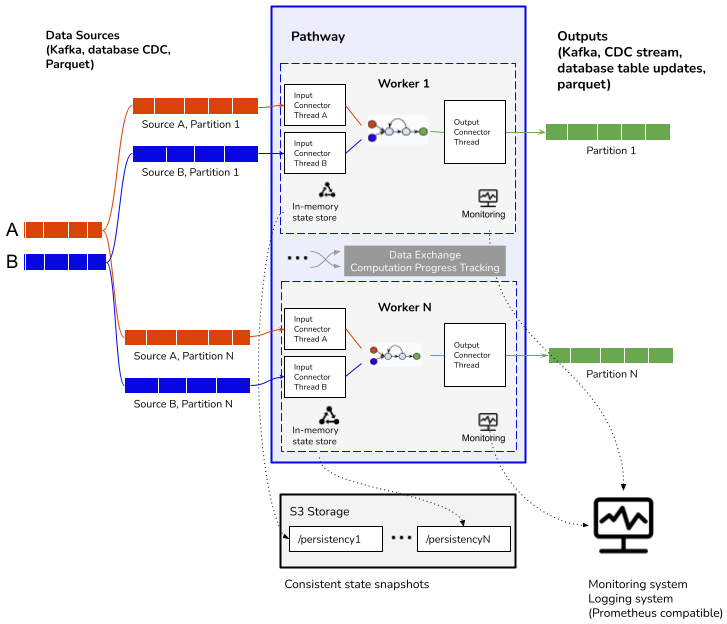
The following diagram sketches a multi-worker Pathway deployment. Each worker has a copy of the dataflow, a local state storage used by the stateful operators, and the input and output connectors for which it is responsible. Workers exchange data and computation progress. Each worker asynchronously saves the state to a permanent location (e.g., S3). Upon failure, all workers determine the last snapshot they wrote and then rewind their computations to this snapshot.
Distributed deployment
A multi-server (distributed) deployment can use Kubernetes and its cloud implementations (AKS, EKS). Pathway assumes a stateful set deployment with all pods present for a successful operation. Pathway enterprise offering covers distributed multi-server deployment for production use. Support with integration into existing helm charts and k8s tooling is provided.