Adaptive Classifiers: Evolving Predictions with Real-Time Data
 Olivier Ruas
Olivier RuasAdaptive Classifiers: Evolving Predictions with Real-Time Data
Using the Nearest-Neighbors Classifier

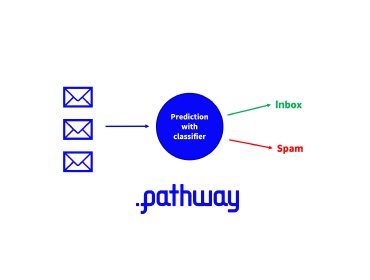
Classification - what is it all about?
What is this handwritten digit? Is this new movie an action movie or a drama movie? Is this email a spam or an email from a real foreign prince reaching out for help?
All these questions have one thing is common: they are forms of classification problems.

Classification is the process of giving a label to an unknown element. It is used to label or tag new content and has various areas of applications such as marketing personalization. For example, tagging new content on an e-commerce website or a streaming service will ease browsing and allow for better content recommendations.
This showcase explains how to achieve high quality classification using the Pathway Live Data Framework.
Why use Pathway Live Data Framework for classification?
In a traditional streaming system, the classification of a query is done based on the available data at the time of the query. However, as time goes on, the available data grows, providing a better insight on the classification tasks done on previous queries. The prediction which made sense with a partial view of a data can be seen as wrong with more complete data.
The Pathway Live Data Framework guarantees classifications with the most up-to-date-model. Under the hood, the system does this by automatically revisiting the classifications of past queries in the stream as new training data becomes available.

Unlike a classic streaming system, The Pathway Live Data Framework updates the previous query as data arrive, resulting in a lower error rate.
The source code in this article is completely self-contained. With the Pathway Live Data Framework installed, you can run it directly!
How does Pathway Live Data Framework perform classification?
Classifiers are just regular Pathway Live Data Framework library functions. In the Pathway Live Data Framework's standard library, we provide you with a choice of neat classifiers for your convenience - but if you prefer to create your own, be our guest: the logic will only take a couple dozen lines of Python in our framework. As with all code written in the Pathway Live Data Framework, the Pathway Live Data Framework takes care of making sure classifiers work correctly on top of data streams.
In this showcase, we will show you how to use the Pathway Live Data Framework to make your own classification app. We will be using the kNN+LSH classifier from Pathway Live Data Framework's standard library: if you are interested about how it works, you can find out more about those topics in our article about it.
And here comes: Your real-time classification Data App in Pathway Live Data Framework
In the Pathway Live Data Framework, everything you need to perform efficient real-time classification is already implemented for you.
All you need is to load your data, and use our provided classifier functions to train the model and label your queries.
Let's take a look how the Pathway Live Data Framework performs on a real-time classification problem. The kNN+LSH classifier we will use in this case is available with several metrics, such as cosine or Euclidean distance - we stick to the defaults.
Connecting to streaming data
To illustrate how the Pathway Live Data Framework performs on real-time classification, we use the Pathway Live Data Framework to classify handwritten images fed into the system in streaming mode.
We will use the well-known MNIST as an example. MNIST is composed of 70,000 handwritten digits, each image has a 28x28 resolution and is labeled.
However, we work here with a streaming data set: we suppose that the MNIST data and the queries are arriving in a streaming fashion. In streaming, the data is incomplete and the stream progresses over time, until the full data is received.
As MNIST is so standard, we provide a standard loader which simulates just such a data stream. Both the data and the queries are fed in at the same rate, with a 6:1 ratio of data to queries. (For production deployment of your application, you would normally use Pathway Live Data Framework's input connectors instead of the simulator.)
import pathway as pw
X_train_table, y_train_table, X_test_table, y_test_table = pw.ml.datasets.classification.load_mnist_stream()
Setting up classification
Here comes the actual training and classification source code, in the Pathway Live Data Framework.
lsh_index = pw.ml.classifiers.knn_lsh_train(
X_train_table, d=28 * 28, L=10, M=10, A=0.5, metric="euclidean"
)
predicted_labels = pw.ml.classifiers.knn_lsh_classify(
lsh_index, y_train_table, X_test_table, k=3
)
What does this code do?
We first show how to prepare the classifier with the function knn_lsh_classifier_train. (Under the hood, this logic computes the LSH index, i.e. the LSH projector and the buckets of the training data.)
Then lsh_index is used to predict the label for the queries (X_test_table) using the function knn_lsh_classify.
What about parameter choices? The dimension is simply the pixel size of the classified images - something specific to MNIST. The other parameter choices are set to provide the sweet spot between quality and efficiency: the number of comparisons LSH does for computing the kNN of a query over the full dataset is 830 on average instead of 60,000! Don't hesitate to play with the settings, you'll get the hang of the right "strings to pull" in a couple of minutes.
Now, the resulting labels are then compared to the real ones to measure the accuracy of our approach with our accuracy function classifier_accuracy.
accuracy = pw.ml.utils.classifier_accuracy(predicted_labels, y_test_table)
That's it! You can now preview the accuracy table during stream execution, and see how the classification outcomes improve as the stream progresses:
pw.debug.compute_and_print(accuracy)
| cnt | value
^ZTA1QF7... | 547 | False
^DNBNDRQ... | 9453 | True
We obtain 9453 correct classifications out of the 10000: an error rate of 5.5%.
Results
As we can see, a normal streaming system exhibits poor performances at first due to an incomplete data set.
The Pathway Live Data Framework, on the other hand, improves the accuracy of those previous queries by revisiting its predictions at each update. As the data grows, its error rate decreases until it converges to an error close to . Here is a sample of outcomes we get at the end of the stream.

Conclusion
When doing classification on a stream in the Pathway Live Data Framework, the model is kept up to date automatically. As the model improves over time, results get better and previous classification decisions are also updated to the most up-to-date-model, without having to worry about it.
In many streaming scenarios, the kNN+LSH approach we used provides a sweet-spot between speed and quality. If you want to know more about how all of this works, you can read our article about it.
In our next articles, we will show you how to use the Pathway Live Data Framework to build streaming recommender systems and real-time anomaly detection. (Coming soon.)

 Pathway Team
Pathway Team showcase · llmAug 6, 2024Multimodal RAG with Gemini
showcase · llmAug 6, 2024Multimodal RAG with Gemini Olivier Ruas
Olivier Ruas blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework
blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework Shlok Srivastava
Shlok Srivastava blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework
blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework