Real-Time AI Pipeline with DeepSeek, Ollama and Pathway

 Saksham Goel
Saksham GoelReal-Time AI Pipeline with DeepSeek, Ollama and Pathway
Retrieval-Augmented Generation (RAG) lets you build question-answering systems that rely on your own private documents rather than generic web data. The challenge is that most RAG/AI pipelines rely on LLM APIs that send your data, or at least a part of it, to the LLM provider which can be a non-starter if you handle sensitive data (trade secrets, confidential IP, or GDPR-protected information). Fortunately, there is a solution to keep your data private: deploying a local LLM. A private RAG pipeline keeps your data on-premise: no external services, no data leaves your control.
In this guide, you'll learn how to use the Pathway Live Data Framework to create a real-time RAG pipeline on top of DeepSeek R1, an open-source reasoning tool running locally with Ollama, a lightweight framework for running local AI models.
1. Why Local Deployment & Why DeepSeek R1?
- Complete Data Privacy: By running a local LLM, none of your data ever leaves your servers. This is crucial for protecting trade secrets, GDPR-sensitive information, and other confidential materials.
- Strong Reasoning: DeepSeek-R1 is a first-generation reasoning model offering performance on par with OpenAI-o1 across math, code, and complex reasoning tasks, including six dense models distilled from DeepSeek-R1 based on Llama and Qwen.
- Flexibility in Model Size: DeepSeek R1 provides multiple variants ranging from 1.5B parameters (lightweight) to significantly larger sizes (for more complex tasks). You can pick a sweet spot based on your hardware and performance needs.
- Pathway Live Data Framework for Real-Time RAG: Pathway Live Data Framework syncs and indexes your data dynamically (including documents from local folders, SharePoint, or Google Drive) and features an integrated vector store. It orchestrates the entire pipeline: from reading documents, embedding them for similarity search, retrieving relevant paragraphs, and feeding them into DeepSeek R1—all in a single framework.
- Predictable, Adaptable Performance: With DeepSeek R1 on-prem, you aren’t subject to changing API performance or model updates from a third party. You can also potentially fine-tune or customize the model for your domain.
- Ollama for Local Inference: Ollama lets you run open-source models (including all DeepSeek R1 variants) on your machine (CPU or GPU), with a simple
ollama servecommand. This means your data never leaves your server.
All together, this stack offers a fully private, real-time question-answering/RAG pipeline that is easy to configure and scale.
2. Cloning the Private RAG Example
Let's get started with setting up your private RAG pipeline. The easiest way is to use the example configuration, which you can find in the llm-app repository. First, clone the Pathway llm-app repository:
git clone https://github.com/pathwaycom/llm-app.git
cd llm-app/templates/private_rag
Inside this folder, you’ll see:
app.py, the application code written in Python using Pathway Live Data Framework;app.yaml, the file containing configuration of the pipeline, like LLM models, sources or server address;requirements.txt, the dependencies for the pipeline. It can be passed topip install -r ...to install everything that is needed to launch the pipeline locally;Dockerfile, the Docker configuration for running the pipeline in the container;data/, a sample folder containing a PDF (a content license agreement) that you'll use in this demonstration
3. What You’ll Need to Build a Local RAG System
- Pathway Live Data Framework
- Docker (if you’d like to run the final pipeline in a container)
- Ollama installed on your machine: https://ollama.com/download
- The DeepSeek R1 model pulled locally
4. Modifying the app.yaml
Open app.yaml and replace the default Mistral references with DeepSeek R1. Here’s the exact code snippet:
$llm_model: "ollama/deepseek-r1:1.5b" # Switch to DeepSeek R1
$llm: !pw.xpacks.llm.llms.LiteLLMChat
model: $llm_model
retry_strategy: !pw.udfs.ExponentialBackoffRetryStrategy
max_retries: 6
cache_strategy: !pw.udfs.DefaultCache {}
temperature: 0
api_base: "http://host.docker.internal:11434" # if running inside Docker
question_answerer: !pw.xpacks.llm.question_answering.BaseRAGQuestionAnswerer
llm: $llm
indexer: $document_store
search_topk: 8 # number of retrieved chunks
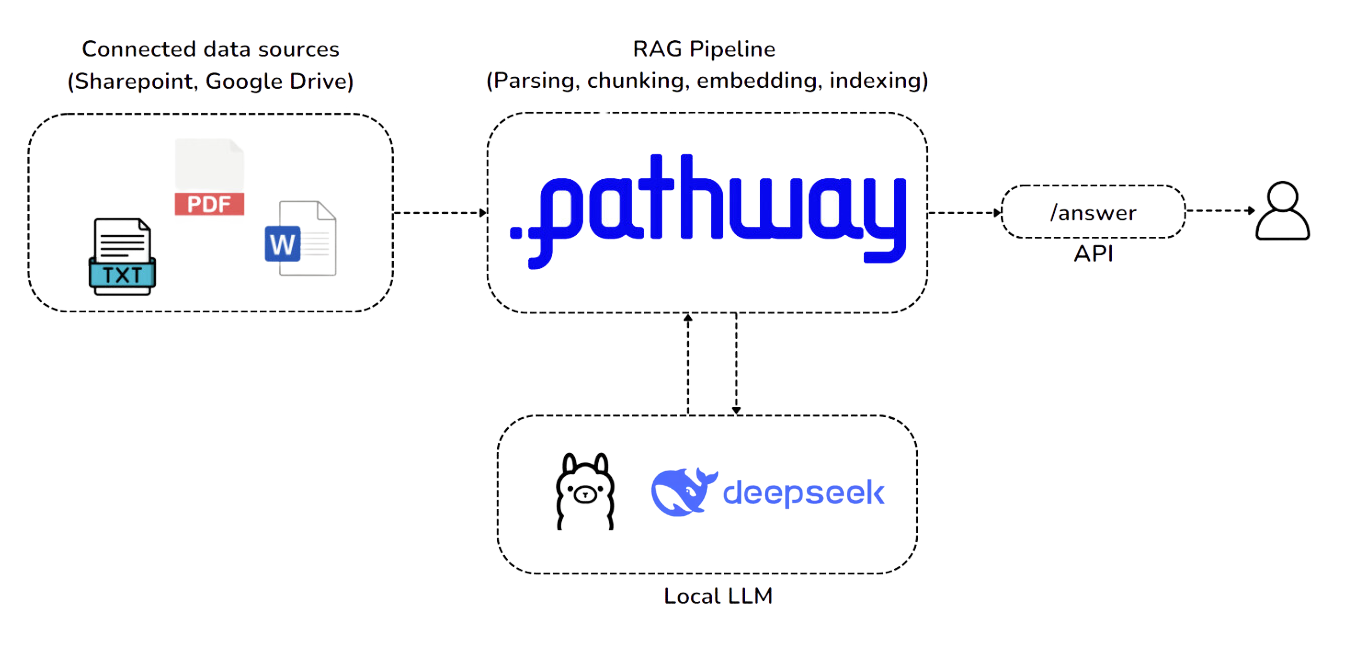
Architecture Diagram showcasing a Real-Time AI pipeline powered by DeepSeek R1 and Pathway Live Data Framework
5. Running DeepSeek R1 Model via Ollama
Download and install Ollama from https://ollama.com/download. Then, open two terminal windows:
- First Terminal — run the Ollama server:
ollama serve
- Second Terminal — pull and run DeepSeek R1:
ollama run deepseek-r1:1.5b
Note that ollama serves models with 2k context length by default, this may cause low quality responses. To change the default context length, run the following:
/set parameter num_ctx 8192. You may set the number up to 128K, however, model should best perform with max context length lower than 32K.
Pro Tip: If you want to try a bigger DeepSeek R1 variant—such as deepseek-r1:7b—simply replace the :1.5b tag above. Note that larger models often require additional system resources (RAM/GPU), so pick the size that fits your hardware.
Ollama will serve on http://localhost:11434. To verify your setup, you can open a third terminal and test it by sending a POST request to that endpoint:
curl -X POST http://localhost:11434/api/generate -d '{"model":"deepseek-r1:1.5b","prompt":"Hello"}'
If it responds with a greeting, your local LLM is working correctly.
6. Building & Running the RAG App
If you are on Windows, please refer to running with docker section below.
Option A: Run in Docker
- Build the Docker image from the private-rag folder (where the Dockerfile resides):
docker build -t privaterag .
- Run the container, mounting your local
datafolder (so it can index your documents):
docker run -v ./data:/app/data -p 8000:8000 privaterag
- The app will start on port
8000(i.e.,http://0.0.0.0:8000).
Option B: Run Locally (No Docker)
- Install dependencies:
pip install -r requirements.txt
- Launch the pipeline:
python app.py
- The REST endpoint defaults to
http://0.0.0.0:8000/v2/answer.
7. Querying the Pipeline
We’ve included a sample PDF file under data/ named:
IdeanomicsInc_20160330_10-K_EX-10.26_9512211_EX-10.26_Content License Agreement.pdf
It’s a content license agreement, which you’ll use as the knowledge base for demonstration.
Send a POST request to the pipeline to see how the framework retrieves from this PDF and generates an answer with DeepSeek R1:
curl -X 'POST' \
'http://0.0.0.0:8000/v2/answer' \
-H 'accept: */*' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "What are the terms and conditions of the contract?"
}'
Pathway’s vector store will retrieve the relevant documents from the data/ folder, pass them as context to DeepSeek R1, and return an answer—fully on-premise, with no external calls.
8. Conclusion: Why Pathway Live Data Framework for Private RAG?
By combining DeepSeek R1, Ollama, and Pathway Live Data Framework:
- 100% On-Prem Deployment: No third-party calls; data never leaves your local environment.
- Real-time updates: If you add or change documents in the
data/folder (or connected sources like SharePoint/Google Drive), the framework can incrementally re-index them—keeping your knowledge base fresh. - Flexible & Scalable: Because Pathway Live Data Framework orchestrates everything in a unified pipeline, you can easily swap in new LLMs, embedder models, indexing strategy or data connectors by customizing the YAML file.
This setup is ideal for organizations dealing with confidential or regulated content, or anyone who wants full control over their LLM environment. With local inference, you have a fully private LLM-based solution with predictable performance and real-time updates.
If you’d like a deeper dive into adaptive retrieval techniques or see another example of Private RAG, check out our previous Private Adaptive RAG guide.
Are you looking to build an enterprise-grade RAG app?
Pathway is trusted by industry leaders such as NATO and Intel, and is natively available on both AWS and Azure Marketplaces. If you’d like to explore how Pathway Live Data Framework can support your RAG and Generative AI initiatives, we invite you to schedule a discovery session with our team.
If you found this guide helpful, be sure to check out the full GitHub repository for more examples, or drop by the documentation to explore advanced connectors, dynamic pipelines, and more. We’d love to hear your feedback—join the Pathway Discord community or open an issue on GitHub.
Happy experimenting with your fully private RAG pipeline!

 Olivier Ruas
Olivier Ruas blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework
blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework Bobur Umurzokov
Bobur Umurzokov blog · tutorial · engineeringAug 28, 2023How to use ChatGPT API in Python for your real-time data
blog · tutorial · engineeringAug 28, 2023How to use ChatGPT API in Python for your real-time data Saksham Goelblog · engineeringJan 16, 2025Power and Deploy RAG Agent Tools with Pathway
Saksham Goelblog · engineeringJan 16, 2025Power and Deploy RAG Agent Tools with Pathway