Interaction with a Feedback Loop.
 Pathway Team
Pathway TeamFuzzy Join - reconciliation with audit: when the computer is not enough
In this article, we are going to show you how Pathway interacts with incremental data flows with a feedback loop.
In the another showcase we explained how smart_fuzzy_join may be helpful in bookkeeping.
Previously, we had a simple pipeline that matched entries of two different tables, such as two logs of bank transfers, in two different formats.
Many matchings can be inferred automatically, but some can be really tricky without help: while the fans of Harry Potter can instantaneously make the connection between 'You-Know-Who' and 'Voldemort', it is impossible for a computer to do so, at least without help.
Human audit is unavoidable in many areas such as accounting or banking. As such, we extend our pipeline with an auditor that supervises the process of reconciliation. The auditor may help the system by providing some hints, i.e. suggesting difficult matchings by hand.
Feedback loop in Pathway
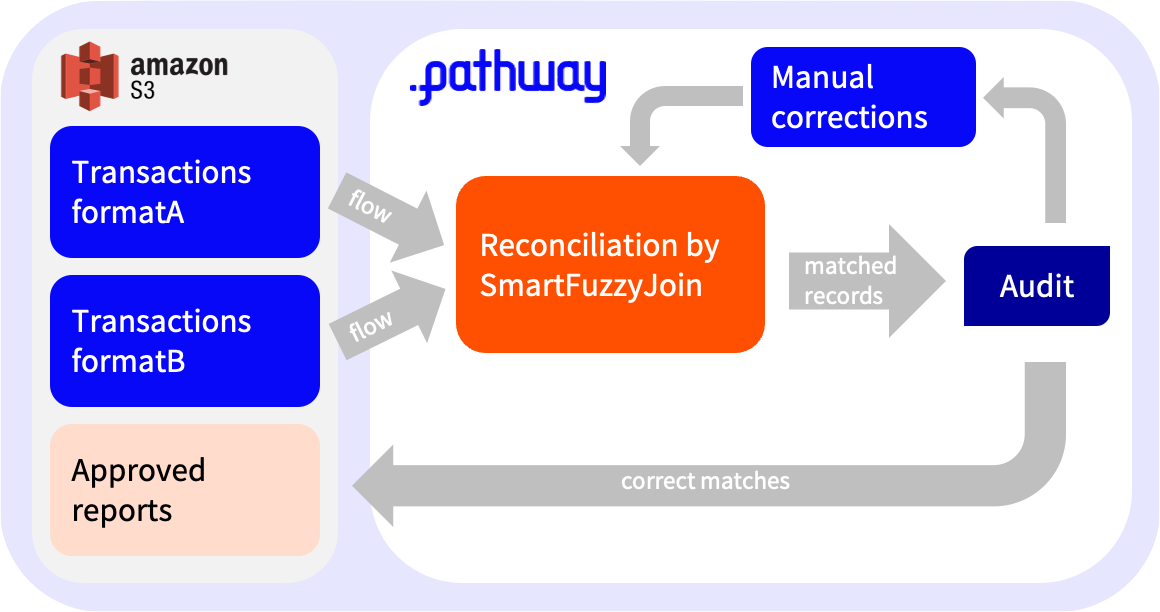
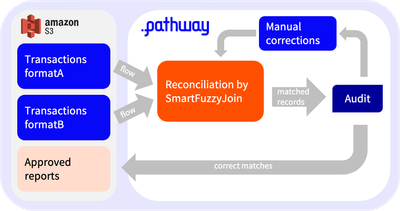
This figure represents an architecture with a feedback loop to understand how the pieces work together.
Reconciliation by SmartFuzzyJoin lies at the heart of the architecture:
- it consumes inputs from 3 sources:
- two tables with transactions in different formats;
- a table with manual corrections provided by the auditor;
- it outputs one table with matched records.
You might think of the auditor as a simple automaton. Either they are satisfied with presented results and simply save them in some storage, or they provide some hints for the algorithm to find a better matching.
Note: Although the architecture contains a feedback loop, all tables here are either inputs or outputs of the system.
The data
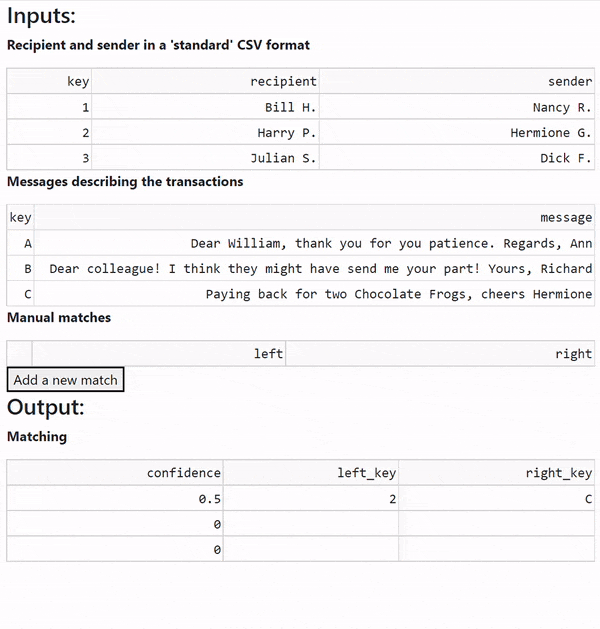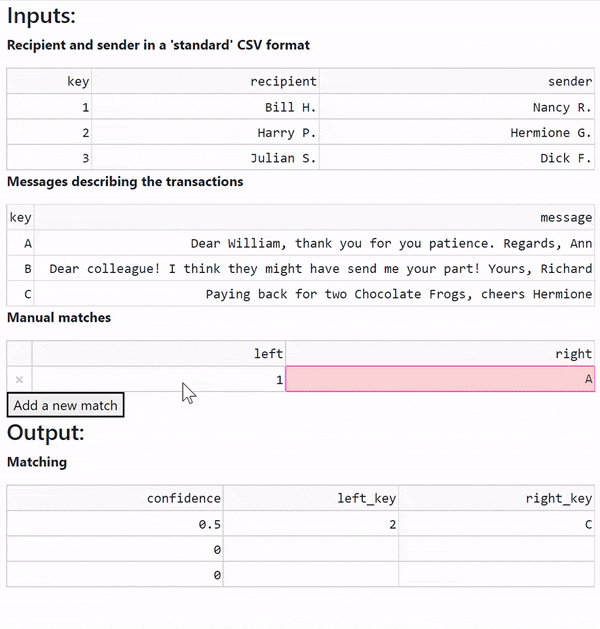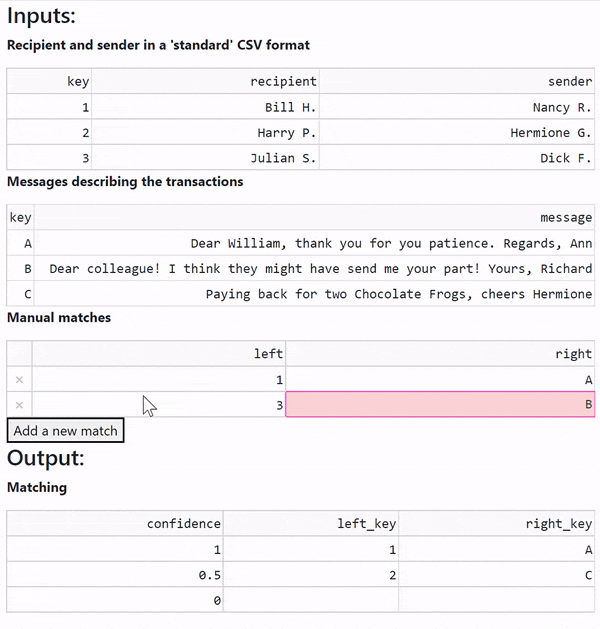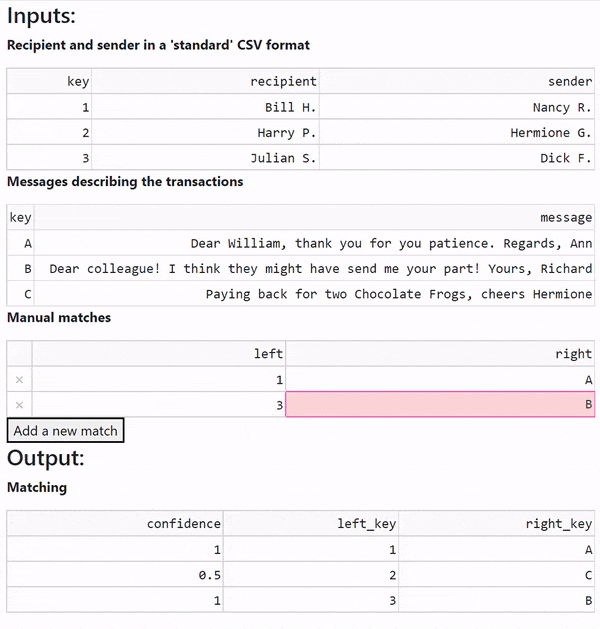
Human audit is certainly needed to handle the sample dataset below.
Recipient and sender in a 'standard' CSV format
| id | recipient | sender |
|---|---|---|
| 1 | Bill H. | Nancy R. |
| 2 | Harry P. | Hermione G. |
| 3 | Julian S. | Dick F. |
Messages describing the transactions
| id | message |
|---|---|
| A | Dear William, thank you for your patience. Regards, Ann |
| B | Dear Colleague! I think they might have sent me your particle! Yours, Richard |
| C | Paying back for two Chocolate Frogs, cheers Hermione! |
Automatic reconciliation
Let's see how many records we can match without any human help. We reuse code from Part 1 of this showcase.
import pandas as pd
import pathway as pw
We need to read the csv files:
# Uncomment to download the required files.
# %%capture --no-display
# !wget https://public-pathway-releases.s3.eu-central-1.amazonaws.com/data/fuzzy_join_part_2_transactionsA.csv -O transactionsA.csv
# !wget https://public-pathway-releases.s3.eu-central-1.amazonaws.com/data/fuzzy_join_part_2_transactionsB.csv -O transactionsB.csv
# !wget https://public-pathway-releases.s3.eu-central-1.amazonaws.com/data/fuzzy_join_part_2_audit1-v2.csv -O audit1.csv
# !wget https://public-pathway-releases.s3.eu-central-1.amazonaws.com/data/fuzzy_join_part_2_audit2-v2.csv -O audit2.csv
class TransactionsA(pw.Schema):
key: int = pw.column_definition(primary_key=True)
recipient: str
sender: str
class TransactionsB(pw.Schema):
key: str = pw.column_definition(primary_key=True)
message: str
transactionsA = pw.io.csv.read(
"./transactionsA.csv",
schema=TransactionsA,
mode="static",
)
transactionsB = pw.io.csv.read(
"./transactionsB.csv",
schema=TransactionsB,
mode="static",
)
pw.debug.compute_and_print(transactionsA)
pw.debug.compute_and_print(transactionsB)
| key | recipient | sender
^YYY4HAB... | 1 | Bill H. | Nancy R.
^Z3QWT29... | 2 | Harry P. | Hermione G.
^3CZ78B4... | 3 | Julian S. | Dick F.
| key | message
^KHNET5G... | A | Dear William, thank you for you patience. Regards, Ann
^FFN4QBS... | B | Dear colleague! I think they might have send me your part! Yours, Richard
^0K14V55... | C | Paying back for two Chocolate Frogs, cheers Hermione
We use the provided column key as indexes: Pathway will generate indexes based on those.
We add a wrapper reconcile_transactions to replace the generated indexes by the corresponding key.
def match_transactions(transactionsA, transactionsB, by_hand_matching):
matching = pw.ml.smart_table_ops.fuzzy_match_tables(
transactionsA, transactionsB, by_hand_match=by_hand_matching
)
transactionsA_reconciled = transactionsA.select(
left=None, right=None, confidence=0.0
).update_rows(
matching.select(pw.this.left, pw.this.right, confidence=pw.this.weight).with_id(
pw.this.left
)
)
return transactionsA_reconciled
def reconcile_transactions(
transactionsA,
transactionsB,
audit=None,
):
by_hand_matching = pw.Table.empty(left=pw.Pointer, right=pw.Pointer, weight=float)
if audit is not None:
by_hand_matching = audit
by_hand_matching = by_hand_matching.select(
left=transactionsA.pointer_from(pw.this.left),
right=transactionsB.pointer_from(pw.this.right),
weight=pw.this.weight,
)
transactionsA_reconciled = match_transactions(
transactionsA, transactionsB, by_hand_matching
)
transactionsA_reconciled = transactionsA_reconciled.join_left(
transactionsA, pw.left.left == pw.right.id
).select(pw.left.right, pw.left.confidence, left_key=pw.right.key)
transactionsA_reconciled = transactionsA_reconciled.join_left(
transactionsB, pw.left.right == pw.right.id
).select(pw.left.left_key, pw.left.confidence, right_key=pw.right.key)
return transactionsA_reconciled, by_hand_matching
matching, _ = reconcile_transactions(transactionsA, transactionsB)
pw.debug.compute_and_print(matching)
| left_key | confidence | right_key
^VFPBYAD... | | 0.0 |
^VFPEVKP... | | 0.0 |
^QFWX2FF... | 2 | 0.5 | C
Not a perfect matching. It seems that the help of an auditor is needed.
Incremental reconciliation with an auditor
The correct matching is 1 - A, 2 - C and 3 - B. Why? Tip 1, Tip 2.
Previously, the algorithm identified matching 2 - C correctly but failed to find the connections between the other pairs. Now, we run it with a hint - feedback from an auditor.
To include the hint (nothing complicated), we just need to launch our function with the parameter audit:
class AuditSchema(pw.Schema):
left: int
right: str
weight: float
audit = pw.io.csv.read("./audit1.csv", schema=AuditSchema, mode="static")
matching, suggested_matchings = reconcile_transactions(
transactionsA, transactionsB, audit
)
Here is the author's feedback, the pair 1 - A:
pw.debug.compute_and_print(suggested_matchings)
| left | right | weight
^E4J9BTQ... | ^YYY4HAB... | ^KHNET5G... | 1.0
Given this feedback, we check that the new matching took into account this pair:
pw.debug.compute_and_print(matching)
| left_key | confidence | right_key
^VFPBYAD... | | 0.0 |
^G1GM5SW... | 1 | 1.0 | A
^QFWX2FF... | 2 | 0.5 | C
Still not perfect but better. It seems that more help from the auditor is needed. Now, with one more extra hint the algorithm matches all the records correctly.
audit = pw.io.csv.read("./audit2.csv", schema=AuditSchema, mode="static")
pw.debug.compute_and_print(audit)
| left | right | weight
^T5Q1HY0... | 1 | A | 1.0
^9MF722E... | 3 | B | 1.0
matching, suggested_matchings = reconcile_transactions(
transactionsA, transactionsB, audit
)
This time we provide the last pair, 3 - B:
pw.debug.compute_and_print(suggested_matchings)
| left | right | weight
^T5Q1HY0... | ^YYY4HAB... | ^KHNET5G... | 1.0
^9MF722E... | ^3CZ78B4... | ^FFN4QBS... | 1.0
Given those, we should obtain a full --and hopefully correct -- matching.
pw.debug.compute_and_print(matching)
| left_key | confidence | right_key
^G1GM5SW... | 1 | 1.0 | A
^QFWX2FF... | 2 | 0.5 | C
^1SQNPMP... | 3 | 1.0 | B
Bingo!
It may sound long and tedious but in practice most of the matchings should have been done automatically. This process is only performed for the few remaining cases, where the linkages are hard to make.
Conclusion
In conclusion, writing pipelines with a feedback loop is as easy as can be. When writing such a data processing algorithm, a tip is to always clearly separate inputs from outputs. It is important because the Pathway engine observes inputs for any changes and recalculates parts of the computation when needed.
In the next chapter, we will show you how to make a Pathway installation which provides a full Fuzzy-Matching application, complete with frontend. (Coming soon!)

Pathway Team

 Olivier Ruas
Olivier Ruas tutorial · machine-learningOct 26, 2022Realtime Classification with Nearest Neighbors
tutorial · machine-learningOct 26, 2022Realtime Classification with Nearest Neighbors Saksham Goel
Saksham Goel blog · tutorialFeb 5, 2025Real-Time AI Pipeline with DeepSeek, Ollama and Pathway
blog · tutorialFeb 5, 2025Real-Time AI Pipeline with DeepSeek, Ollama and Pathway Pathway Team
Pathway Team tutorial · engineering · case-studyAug 27, 2024Achieve Sub-Second Latency with your S3 Storage without Kafka
tutorial · engineering · case-studyAug 27, 2024Achieve Sub-Second Latency with your S3 Storage without Kafka