Adaptive RAG: cut your LLM costs without sacrificing accuracy
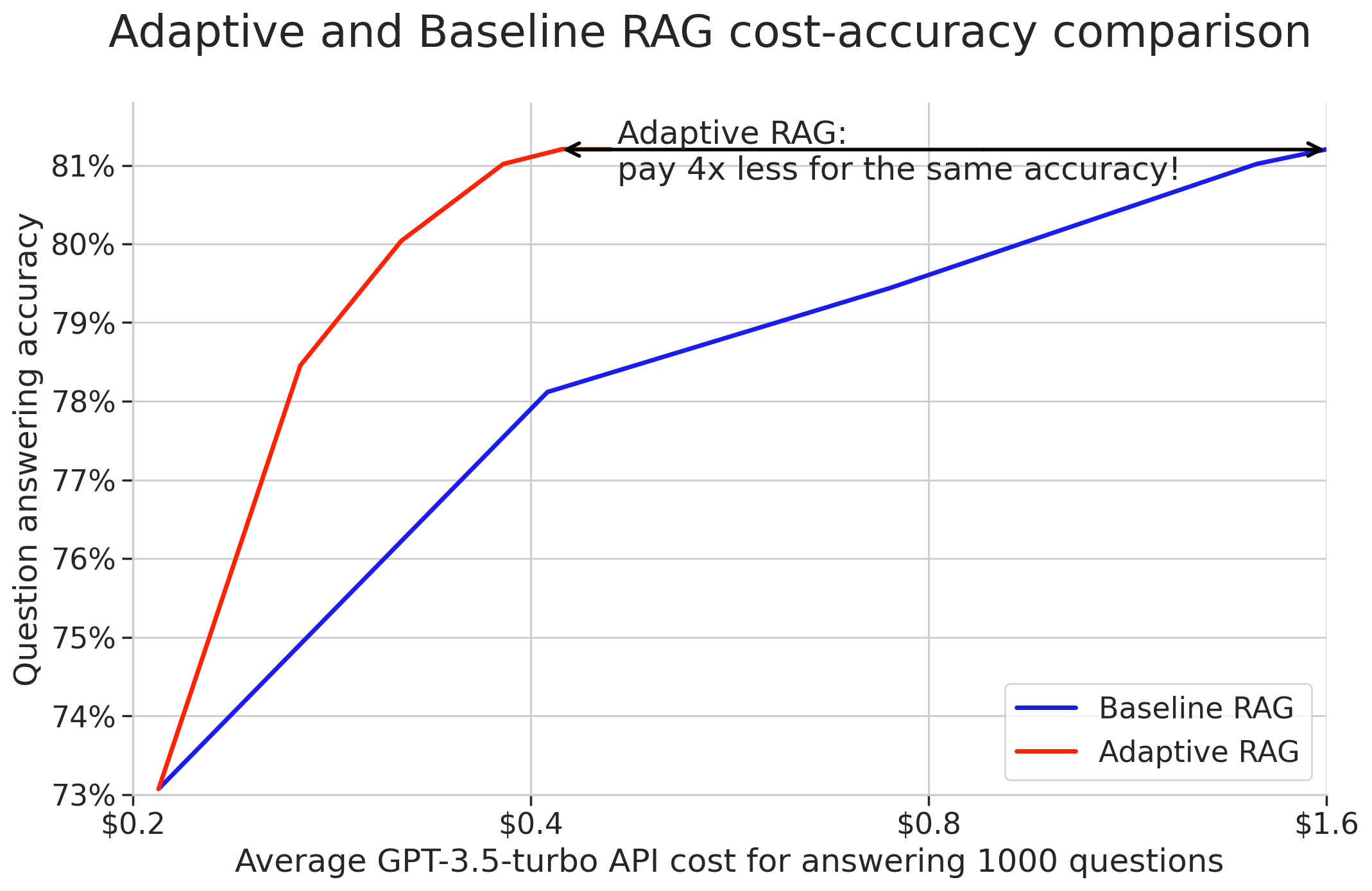
TLDR: We demonstrate how to dynamically adapt the number of documents in a RAG prompt using feedback from the LLM. This allows a 4x cost reduction of RAG LLM question answering while maintaining good accuracy. We also show that the method helps explain the lineage of LLM outputs. We provide runnable code examples implemented in the Pathway LLM expansion pack, feel free to skip directly to the code.
What are blue boxes?
Blue boxes, such as this one, provide additional insights which can be skipped. However all are eager to be read!.Introduction
Retrieval Augmented Generation (RAG) allows Large Language Models (LLMs) to answer questions based on knowledge not present in the original training set. At Pathway we use RAG to build document intelligence solutions that answer questions based on private document collections, such as a repository of legal contracts. We are constantly working on improving the accuracy and explainability of our models while keeping the costs low. In this blog post, we share a trick that helped us reach those goals.
A typical RAG Question Answering procedure works in two steps. First the question is analyzed and a number of relevant documents are retrieved from a database, typically using a similarity search inside a vector space created by a neural embedding model. Second, retrieved documents are pasted, along with the original question, into a prompt which is sent to the LLM. Thus, the LLM answers the question within a relevant context.
Practical implementations of the RAG procedure need to specify the number of documents put into the prompt. A large number of documents increases the ability of the LLM to provide a correct answer, but also increases LLM costs, which typically grow linearly with the length of the provided prompt. The prompt size also influences model explainability: retrieved context documents explain and justify the answer of the LLM and the fewer context documents are needed, the easier it is to verify and trust model outputs.
Thus the context size, given by the number of considered documents in a RAG setup, must be chosen to balance costs, desired answer quality, and explainability. However, can we do better than using the same context size regardless of the question to be answered? Intuitively, not all questions are equally hard and some can be answered using a small number of supporting documents, while some may require the LLM to consult a larger prompt. We can confirm this by running a question answering experiment.
Experiment details and prompt
We base our evaluation on the Stanford Question Answering Dataset (SQUAD) which we convert into a RAG open-domain question answering task. We take the first 50 Wikipedia articles that form the SQUAD dataset. As in SQUAD, each article is split into paragraphs and we select for testing one SQUAD question for each paragraph, which yields nearly 2500 tuples containing a paragraph, a query, and a ground-truth answer.
We form a document knowledge base from all wikipedia paragraphs indexed using their vector representations computed using OpenAI ADA-002 neural embedding model. To answer a question we vectorize the question using ADA-002 embedder, then select closest paragraphs according to the cosine distance. We use the retrieved paragraphs to construct the following prompt inspired by LlamaIndex QueryCitationEngine:
Use the below articles to answer the subsequent question.
If the answer cannot be found in the articles, write
"I could not find an answer." Do not answer in full sentences.
When referencing information from a source, cite the appropriate
source(s) using their corresponding numbers. Every answer should
include at least one source citation.
Only cite a source when you are explicitly referencing it. For example:
"Source 1:
The sky is red in the evening and blue in the morning.
Source 2:
Water is wet when the sky is red.
Query: When is water wet?
Answer: When the sky is red [2], which occurs in the evening [1]."
Now it's your turn.
Unless stated otherwise, all results use gpt-3.5-turbo in the gpt-3.5-turbo-0613 variant.
The LLM can respond using a paraphrase of the ground-truth answer. To properly score paraphrases we canonicalize answers by removing using nltk all stopwords and stemming all remaining words. We then count an answer as correct if all remaining stemmed words in the ground truth are found in the LLM RAG response. While this method yields some false negatives, we found it to be simple and robust enough to tune RAG question answering systems.
The chart below shows a typical relation between accuracy and supporting context size for a RAG question answering system using a budget friendly LLM (e.g. gpt-3.5-turbo):
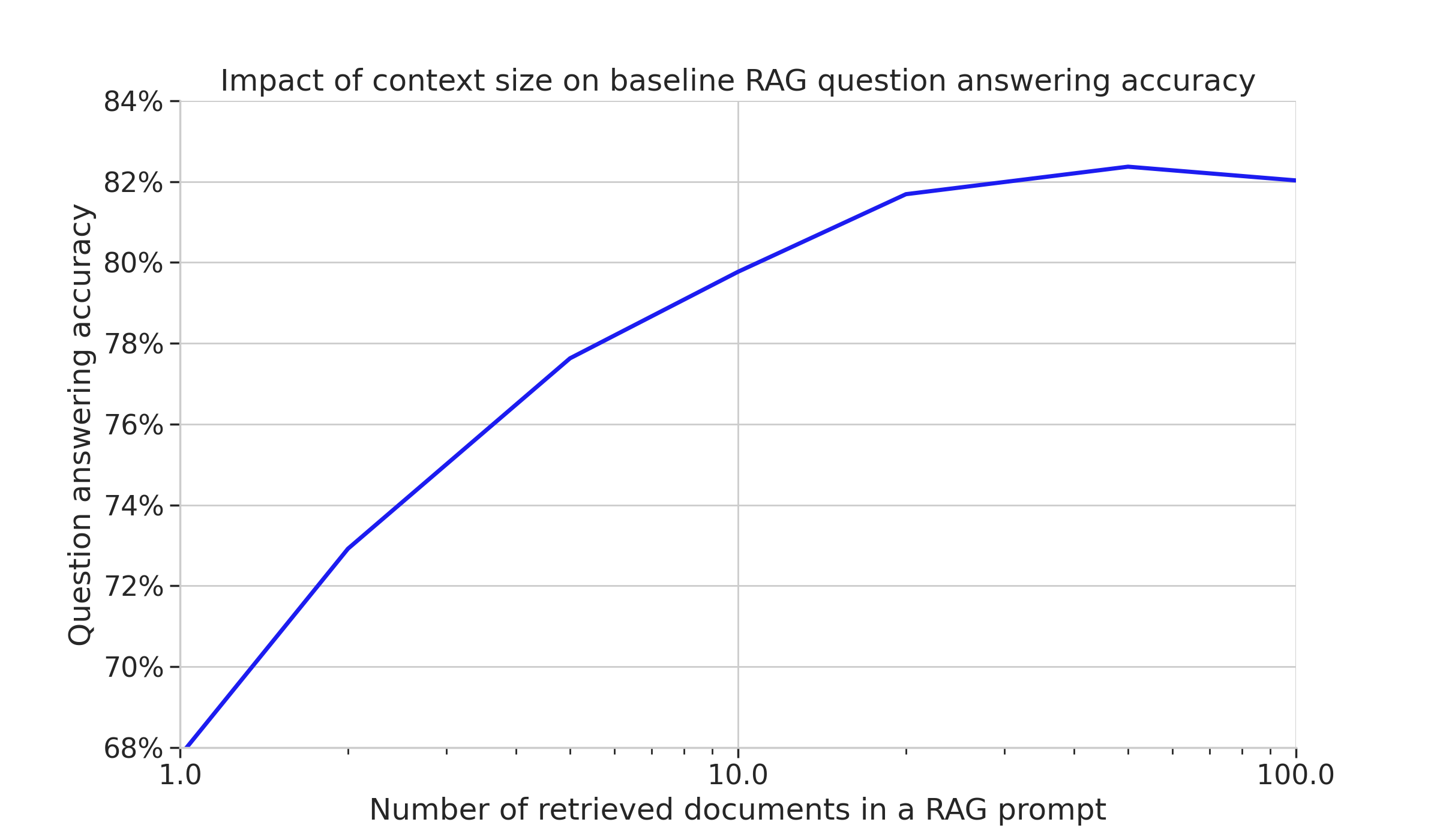
We can notice a few things. First, even with one supporting document the model is right 68% of the time. The accuracy rises by more than 10 percentage points to nearly 80% when we provide it with 10 context documents. We then see diminishing returns: increasing the prompt size to 50 documents brings the accuracy just above 82%. With 100 context documents the model is getting slightly worse. The LLM has trouble finding the correct information in the large prompt provided to it, this phenomenon has been widely observed and LLM providers are actively working on expanding both supported context sizes and the accuracy of information retrieval from context.
We can get further insights into the operation of the RAG LLM by performing error analysis: categorizing each error as a do not know if the LLM refuses to provide an answer, or a hallucination if the LLM provides a wrong answer:
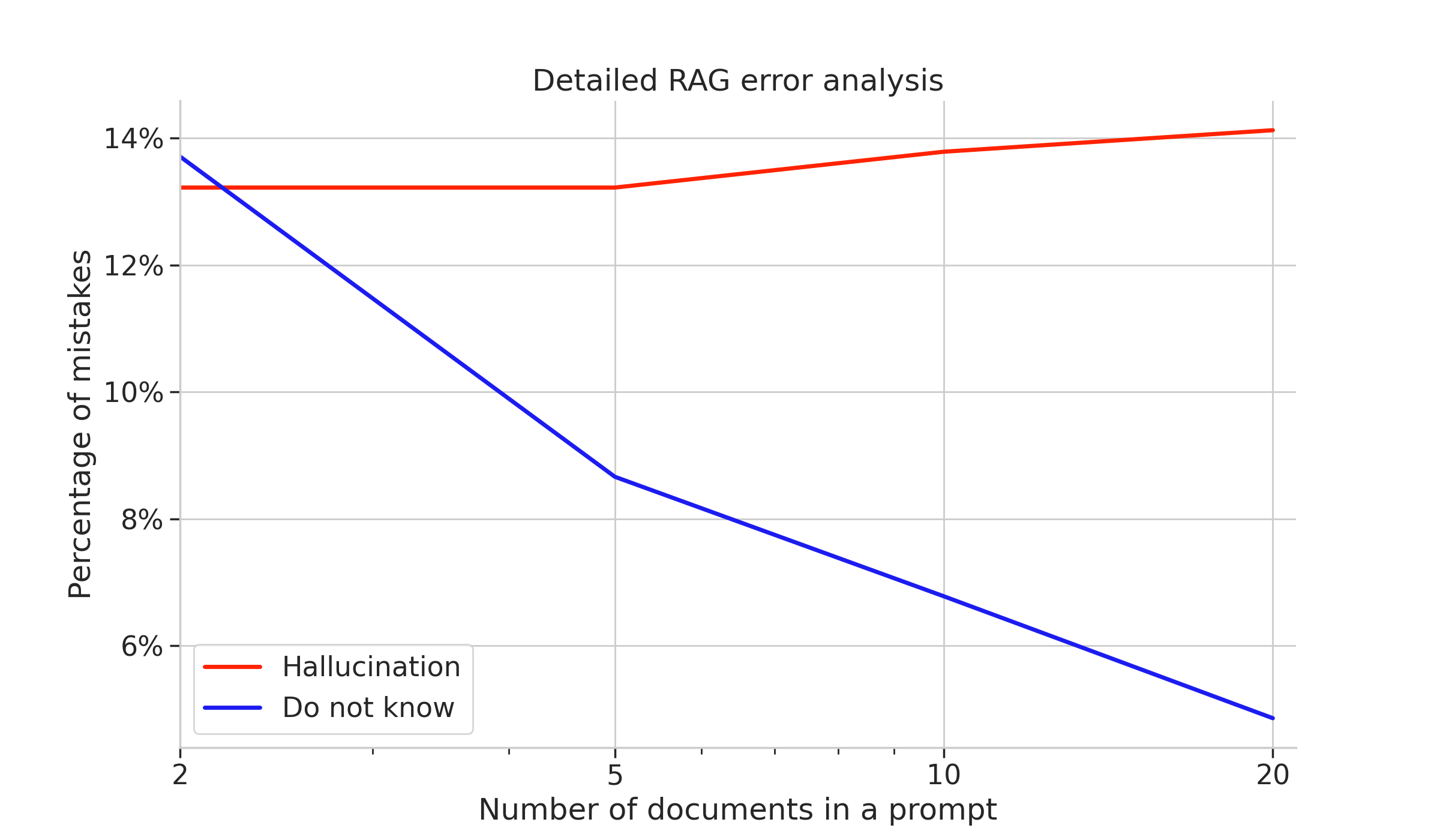
We can see two opposite trends: as the number of supporting documents grows, we get fewer Do not knows. However, at the same time, the number of hallucinated answers slightly raises. Those trends can be explained with the following hypothesis: The more context we provide to the LLM, the higher chances there are that the model will retrieve some information (instead of answering with a Do not know), but a larger prompt may also confuse the model and promote wrong answers (hallucinations).
Examples of model behavior
Further insight may be gained from analyzing model errors on a few concrete examples. We will look at the answers when the LLM is provided with a varying number of context documents: two (documents 0-1), five (documents 0-4), ten, and twenty. The table is not a representative sample of model behavior: we only list questions on which the model answered wrong with 2 context documents.We see that for many questions the LLM knows the correct response after seeing sufficiently many context documents. Moreover, it indicates that the smaller context is insufficient. We will use this to formulate an Adaptive RAG strategy next.
Question | Ground truth SQUAD answer | Answer for 2 context docs | Answer for 5 context docs | Answer for 10 context docs | Answer for 20 context docs |
|---|---|---|---|---|---|
What was undertaken in 2010 to determine where dogs originated from? | extensive genetic studies | Genetic studies were undertaken in 2010 to determine where dogs originated from [0]. | Genetic studies were undertaken in 2010 to determine where dogs originated from [0]. | Genetic studies were undertaken in 2010 to determine where dogs originated from [1]. | Extensive genetic studies were undertaken in 2010 to determine where dogs originated from [0]. |
When it is burned what does hydrogen make? | water | I could not find an answer. | Water [4] | Water [2] | Water [2]. |
What fraction of New Yorkers in the private sector are employed by foreign companies? | One out of ten | I could not find an answer. | One out of ten private sector jobs in New York City is with a foreign company [0]. | One out of ten private sector jobs in New York City is with a foreign company [0]. | One out of ten private sector jobs in New York City is with a foreign company [0]. |
Deshin Shekpa was the head of what school? | the Karma Kagyu school | I could not find an answer. | I could not find an answer. | Karma Kagyu [3] | I could not find an answer. |
Middle Devonian limestone exists between Plymstock and what location? | Cremyll | I could not find an answer. | West Hoe [0] | West Hoe [0] | I could not find an answer. |
How much precipitation on average falls within the city? | 35.9 inches | The city receives 49.9 inches (1,270 mm) of precipitation annually [0]. | The city receives about 35.9 inches (91.2 cm) of precipitation annually [2]. | The city receives about 35.9 inches (91.2 cm) of precipitation annually [2] | The city receives about 35.9 inches (91.2 cm) of precipitation annually [2]. |
Who was added to the tour in season 12? | a semi-finalist who won a sing-off | I could not find an answer. | I could not find an answer. | A semi-finalist who won a sing-off [6]. | A semi-finalist who won a sing-off was added to the tour in season 12 [6]. |
What is the name of the Buddhist doctrine that states that phenomena arise together in a mutually interdependent web of cause and effect? | pratītyasamutpāda, (Sanskrit; Pali: paticcasamuppāda; Tibetan Wylie: rten cing 'brel bar 'byung ba; Chinese: 緣起) | The Buddhist doctrine that states that phenomena arise together in a mutually interdependent web of cause and effect is called pratītyasamutpāda [0]. | The doctrine is called pratītyasamutpāda [0]. | The doctrine is called pratītyasamutpāda [0] | The doctrine is called pratītyasamutpāda [0]. |
Which actress carried the torch for part of the route? | Sulaf Fawakherji | Gabriela Sabatini [1] | I could not find an answer. | Sulaf Fawakherji [8] | Maria Nafpliotou [10] |
Who provides a virtual server service? | Internet hosting services | I could not find an answer. | A virtual server service is provided by internet hosting services [0] | A virtual server service is provided by internet hosting services [0]. | I could not find an answer. |
Adaptive RAG
We can use the model’s refusal to answer questions as a form of model introspection which enables an adaptive RAG question answering strategy:
This RAG scheme adapts to the hardness of the question and the quality of the retrieved supporting documents using the feedback from the LLM - for most documents a single LLM call with a small prompt is sufficient, and there is no need for auxiliary LLM calls to e.g. guess an initial supporting document count for a question. However, a fraction of questions will require re-asking or rere-asking the LLM.
How to expand the prompt? Linearly? Exponentially?
To turn the adaptive RAG intuition into a practical system we need to specify some vital details. For starters, a good prompt expansions scheme must balance:
- low typical question cost: more than 60% of questions need only one supporting document
- low hard question cost: the LLM will be called multiple times to answer a hard question. The whole cost of handling the question should be low
- acceptable latency on hard questions: the number of LLM answer retires should grow slowly with question difficulty
These design criteria can be met by expanding the prompt according to a geometric series, such as doubling the number of documents in the prompt on each retry. It has the following advantages:
- We can start with just one supporting document: easy questions are answered fast and cheap
- The number of sequential LLM calls (latency) grows logarithmically (read slowly) with final supporting context size. With a prompt doubling strategy only 6 rounds are needed to reach the accuracy plateau in Figure 1 with supporting documents.
- The total cost of repeated calls to the LLM with expanding prompts only grows linearly. The summed count of documents in the 6 prompts needed to reach 64 supporting documents is . Form math nerds, recall that for an expansion factor the total cost of geometric LLM retries is . In other words, the total cost is only than the cost of doing the last LMM query on the large context needed to answer the question.
Of course, the cost-vs-latency tradeoff can be further tuned by choosing a different prompt expansion factor. In contrast, a linear prompt expansion strategy which grows the prompt by a constant number of documents (e.g. first use 5, then 10, then 15, then 20, ...) will result in the latency growing linearly (read much faster than logarithmically) and the LLM cost growing quadratically (again much faster than linearly) with final prompt size!
How subsequent subsequent prompts relate?
This design question is less intuitive. Suppose LLM didn’t find an answer when provided with K most relevant documents from the knowledge. The next prompt could:
- include the K documents which were not sufficient along with next documents (overlapping prompts strategy), or
- ignore the K insufficient documents and instead try the next documents (non-overlapping prompts strategy).
The overlapping prompts strategy is closer to the original experiment with RAG performance over different context sizes. With a doubling expansion strategy, -th call to the LLM sees most relevant documents. The non-overlapping prompts strategy at first sight is cheaper: -th call to the LLM sees documents . However, this means that the LLM sees more and more irrelevant documents.
To answer this question we experimentally compare the two adaptive strategies along with the base RAG. Both adaptive RAG strategies were tested up to 100 retrieved documents.
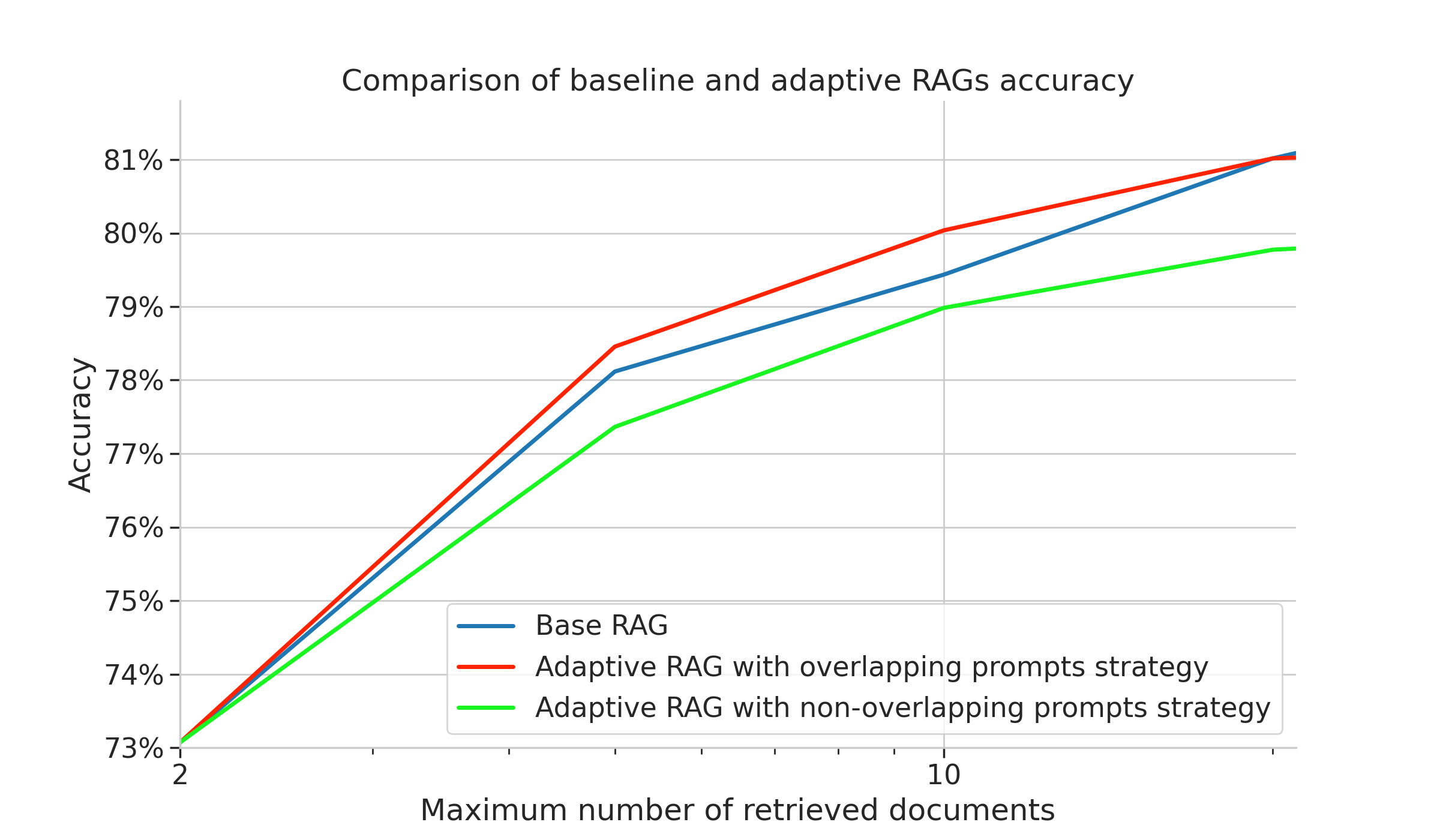
We see that the accuracy of base RAG and the overlapping expanding prompt strategy is very similar up to about 20 retrieved documents, (at 50 consulted articles the baseline RAG gets 1 percentage point better). However, the cost versus accuracy plot below clearly indicates that adaptive RAG is significantly cheaper which in our opinion makes up for the slightly lower accuracy, similarly to the wide preference for using smaller or turbo models to save on running costs.
In contrast, the non-overlapping prompt creation strategy is clearly less accurate. This shows that the LLM needs the most relevant documents even if they are not sufficient by themselves to formulate a confident answer.
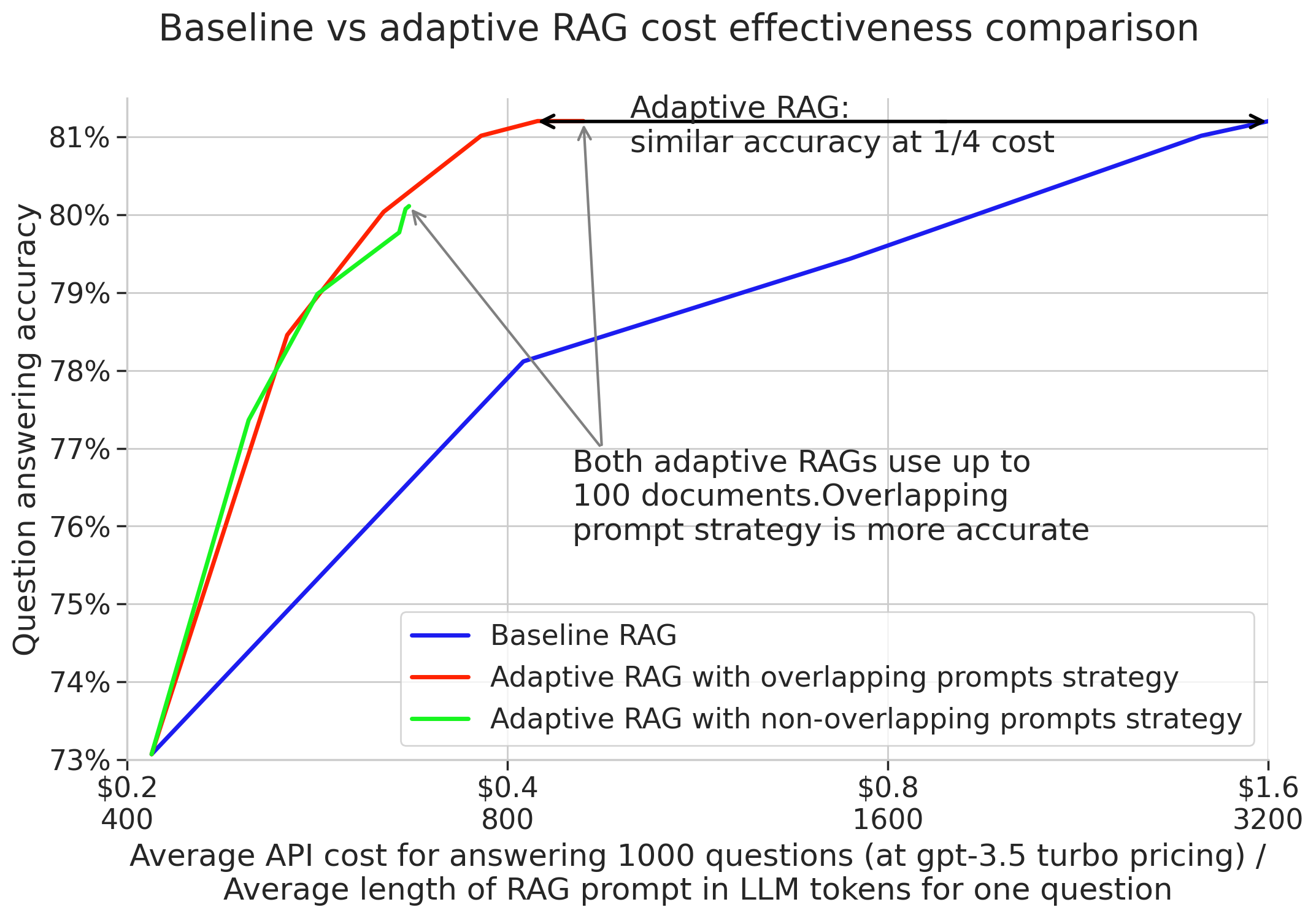
The costs vs accuracy plot clearly indicates that the two adaptive RAGs are significantly more efficient than the basic variant, despite being able to consult more articles if needed. The non-overlapping adaptive RAG strategy is less accurate: even after using all 100 retrieved context documents, it cannot reach the peak performance of the overlap prompt creation strategy. This settles the second design decision :).
Side-note: how repeatable are the ratios of hallucinations vs do not knows across different models
While the do not knows and hallucinations both count as errors, their severity is very different: a do not know is merely not useful to the user, it just indicates further actions are needed to answer a question. On the other hand a hallucination is directly harmful: it propagates false knowledge. We thus believe that scoring models based on their accuracy alone is insufficient and it is beneficial to separately count refusals to answer and hallucinations.
While doing experiments for this article we have found that different models in the same family, e.g. the gpt-3.5-turbo variants offer widely different performance, with newer models seemingly tuned to more confidently return hallucinated answers.
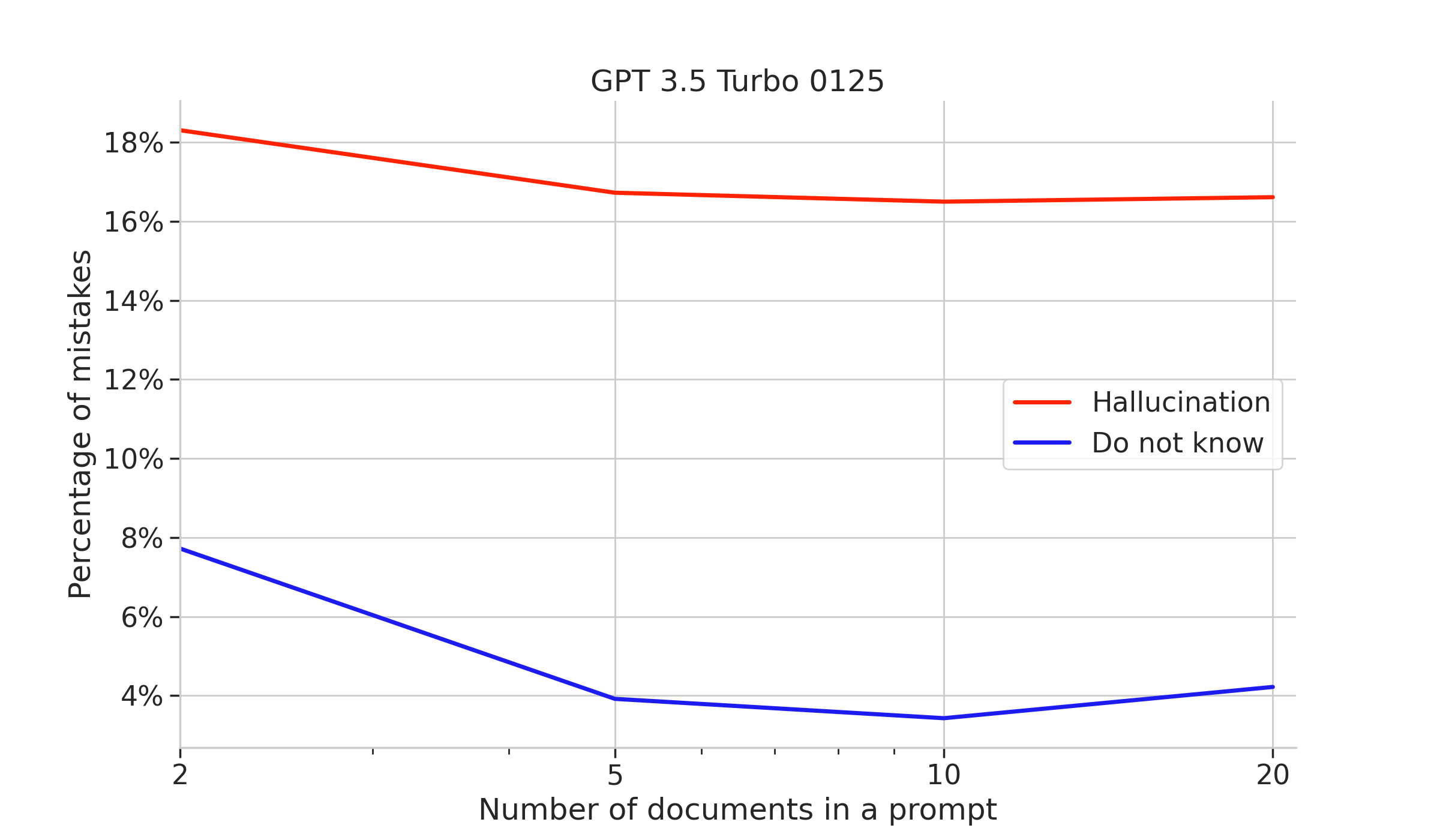
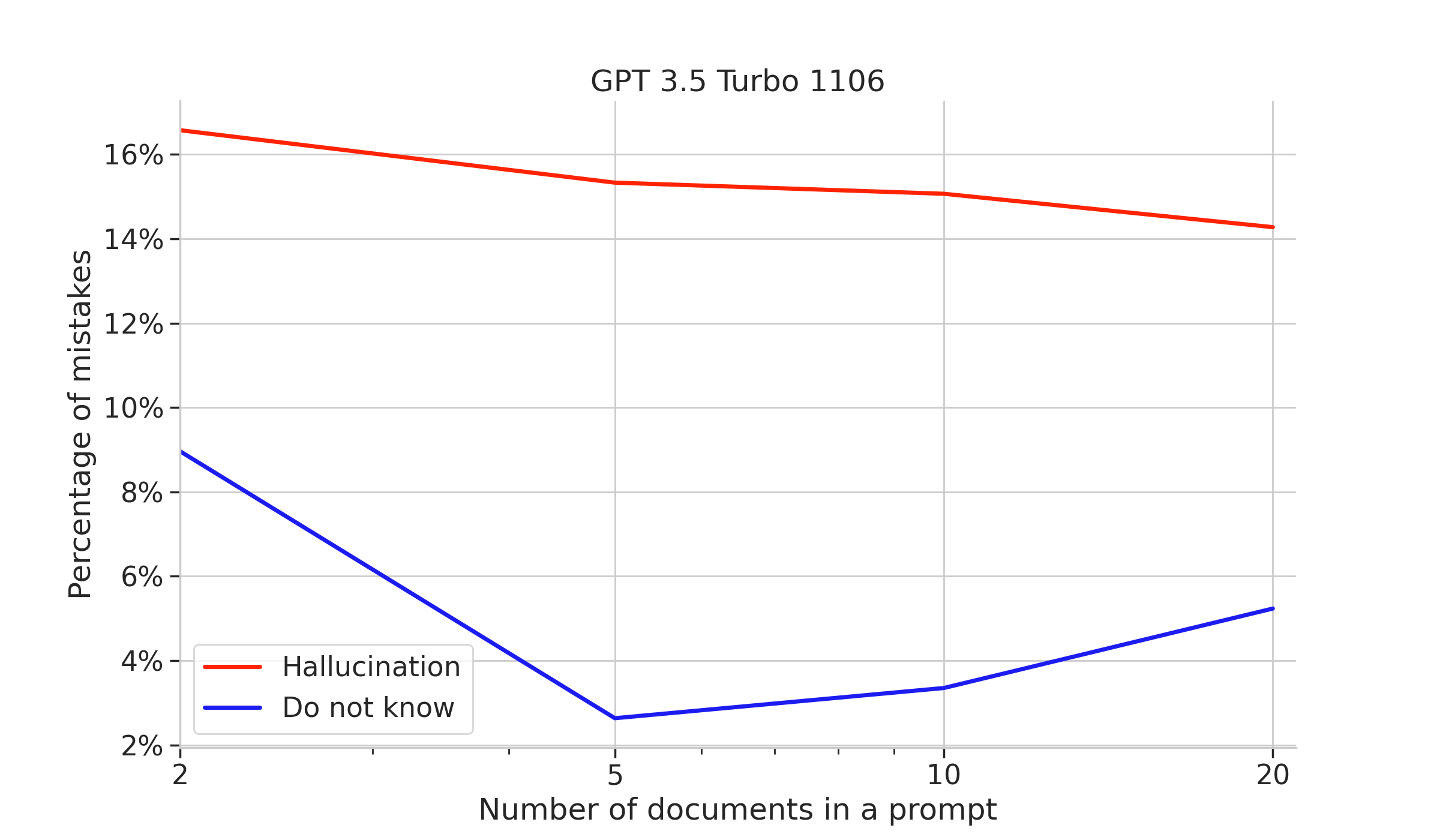
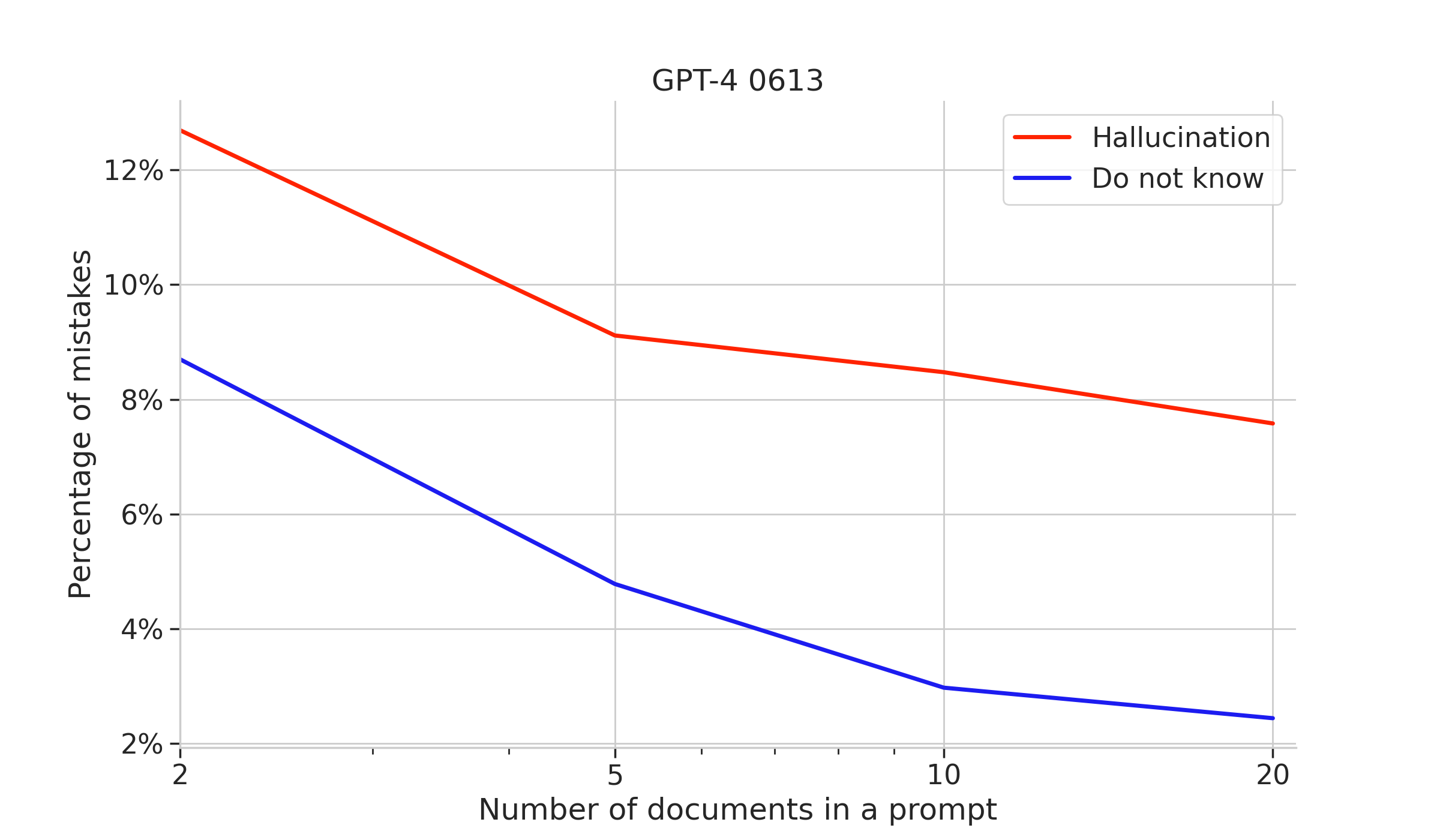
From the do not know vs hallucinations plots we see that new models maintain or improve answer accuracy, however they are differently calibrated: there is a visible preference to answer wrong, but answer nevertheless. This breaks the self-introspection of models, which indicates if the question should be retried with a larger prompt or terminated.
Proper LLM calibration is an important topic for us at Pathway and we are actively working on the topic. Stay tuned for a follow-up blog post concentrating on calibration.
Trying it out
We provide an implementation of the Adaptive RAG in the Pathway data processing framework. Pathway is your one-stop-shop for building realtime data processing pipelines, from simple ETL to synchronizing and indexing document collections into knowledge bases. The Pathway LLM Xpack is a set of pipeline components that are useful in working with LLMs: auto-updating vector stores, RAGs and many more LLM examples. If you are interested in how Adaptive RAG is implemented inside Pathway, you can dive into the internals directly here.
As a prerequisite to run the code, install necessary packages and download sample data which will be used.
# Uncomment, if you need to install Pathway and OpenAI packages
# !pip install pathway
# !pip install openai
# Download `adaptive-rag-contexts.jsonl` with ~1000 contexts from SQUAD dataset
!wget -q -nc https://public-pathway-releases.s3.eu-central-1.amazonaws.com/data/adaptive-rag-contexts.jsonl
# If you want to use cache, set `PATHWAY_PERSISTENT_STORAGE environmental variable
# !export PATHWAY_PERSISTENT_STORAGE=".cache"
import getpass
import os
import pandas as pd
import pathway as pw
from pathway.stdlib.indexing import default_vector_document_index
from pathway.xpacks.llm.embedders import OpenAIEmbedder
from pathway.xpacks.llm.llms import OpenAIChat
from pathway.xpacks.llm.question_answering import (
answer_with_geometric_rag_strategy_from_index,
)
# Set OpenAI API Key
if "OPENAI_API_KEY" in os.environ:
api_key = os.environ["OPENAI_API_KEY"]
else:
api_key = getpass.getpass("OpenAI API Key:")
# Parameters for OpenAI models
embedder_locator: str = "text-embedding-ada-002"
embedding_dimension: int = 1536
chat_locator: str = "gpt-3.5-turbo-16k-0613"
max_tokens: int = 120
temperature: float = 0.0
# Set up OpenAI Embedder and Chat
embedder = OpenAIEmbedder(
api_key=api_key,
model=embedder_locator,
retry_strategy=pw.udfs.FixedDelayRetryStrategy(),
cache_strategy=pw.udfs.DefaultCache(),
)
model = OpenAIChat(
api_key=api_key,
model=chat_locator,
temperature=temperature,
max_tokens=max_tokens,
retry_strategy=pw.udfs.FixedDelayRetryStrategy(),
cache_strategy=pw.udfs.DefaultCache(),
)
# Change logging configuration. Uncomment this if you want to see requests to OpenAI in the logs
# import logging
# import sys
# logging.basicConfig(stream=sys.stderr, level=logging.INFO, force=True)
# Load documents in which answers will be searched
class InputSchema(pw.Schema):
doc: str
documents = pw.io.fs.read(
"adaptive-rag-contexts.jsonl",
format="json",
schema=InputSchema,
json_field_paths={"doc": "/context"},
mode="static",
)
# Create table with questions
df = pd.DataFrame(
{
"query": [
"When it is burned what does hydrogen make?",
"What was undertaken in 2010 to determine where dogs originated from?",
],
"__time__": [ # Queries need to be processed after documents, this sets arbitrarily high processing time
2723124827240,
2723124827240,
],
}
)
query = pw.debug.table_from_pandas(df)
# Main part of the code - creating index of documents and running adaptive RAG!
# Index for finding closest documents
index = default_vector_document_index(
documents.doc, documents, embedder=embedder, dimensions=embedding_dimension
)
# Run Adaptive RAG
result = query.select(
question=query.query,
result=answer_with_geometric_rag_strategy_from_index(
query.query,
index,
documents.doc,
model,
n_starting_documents=2,
factor=2,
max_iterations=5,
),
)
# uncomment this line if you want to run the calculations and print the result
# pw.debug.compute_and_print(result)
The result is a table with an answer to each question. If you want to see how many documents were needed to obtain the answer, you can check that in the logs. To print the logs with requests uncomment the cell which sets logging.basicConfig(stream=sys.stderr, level=logging.INFO, force=True).
Then, when you run the code, you would see entries like this in the logs:
INFO:pathway.xpacks.llm.llms:{"_type": "openai_chat_request", "kwargs": {"temperature": 0.0, "max_tokens": 120, "model": "gpt-3.5-turbo-16k-0613"}, "id": "a7556bb5", "messages": [{"content": "\n Use the below articles to answer the subsequent question. If the answer cannot be found in the articles, write \"I could not find an answer.\" Do not answer in full sentences.\n When referencing information from a source, cite the appropriate source(s) using their corresponding numbers. Every answer should include at least one source citation.\n Only cite a source when you are explicitly referencing it. For example:\n\"Source 1:\nThe sky is red in the evening and blue in the morning.\nSource 2:\nWater is wet when the sky is red.\n\n Query: When is water wet?\nAnswer: When the sky is red [2], which occurs in the evening [1].\"\n Now it's your turn.\n------\nSource 1: One of the first quantum effects to be explicitly noticed (but not understood at the time) was a Maxwell observation involving hydrogen, half a century before full quantum mechanical theory arrived. Maxwell observed that the specific heat capacity of H2 unaccountably departs from that of a diatomic gas below room temperature and begins to increasingly resemble that of a monatomic gas at cryogenic temperatures. According to quantum theory, this behavior arises from the spacing of the (quantized) rotational energy levels, which are particularly wide-spaced in H2 because of its low mass. These widely spaced levels inhibit equal partition of heat energy into rotational motion in hydrogen at low temperatures. Diatomic gases composed of heavier atoms do not have such widely spaced levels and do not exhibit the same effect.\n\nSource 2: In 1671, Robert Boyle discovered and described the reaction between iron filings and dilute acids, which results in the production of hydrogen gas. In 1766, Henry Cavendish was the first to recognize hydrogen gas as a discrete substance, by naming the gas from a metal-acid reaction \"flammable air\". He speculated that \"flammable air\" was in fact identical to the hypothetical substance called \"phlogiston\" and further finding in 1781 that the gas produces water when burned. He is usually given credit for its discovery as an element. In 1783, Antoine Lavoisier gave the element the name hydrogen (from the Greek \u1f51\u03b4\u03c1\u03bf- hydro meaning \"water\" and -\u03b3\u03b5\u03bd\u03ae\u03c2 genes meaning \"creator\") when he and Laplace reproduced Cavendish's finding that water is produced when hydrogen is burned.\n------\nQuery: When it is burned what does hydrogen make?\nAnswer:", "role": "system"}]}
INFO:pathway.xpacks.llm.llms:{"_type": "openai_chat_response", "response": "When hydrogen is burned, it produces water [2].", "id": "a7556bb5"}
This shows that question about water used only 2 sources. On the other hand, for the question about dogs, you will see multiple requests to openai, with the final one being:
INFO:pathway.xpacks.llm.llms:{"_type": "openai_chat_request", "kwargs": {"temperature": 0.0, "max_tokens": 120, "model": "gpt-3.5-turbo-16k-0613"}, "id": "3f61fa40", "messages": [{"content": "\n Use the below articles to answer the subsequent question. If the answer cannot be found in the articles, write \"I could not find an answer.\" Do not answer in full sentences.\n When referencing information from a source, cite the appropriate source(s) using their corresponding numbers. Every answer should include at least one source citation.\n Only cite a source when you are explicitly referencing it. For example:\n\"Source 1:\nThe sky is red in the evening and blue in the morning.\nSource 2:\nWater is wet when the sky is red.\n\n Query: When is water wet?\nAnswer: When the sky is red [2], which occurs in the evening [1].\"\n Now it's your turn.\n------\nSource 1: The coats of domestic dogs are of two varieties: \"double\" being common with dogs (as well as wolves) originating from colder climates, made up of a coarse guard hair and a soft down hair, or \"single\", with the topcoat only.\n\nSource 2: Dogs have lived and worked with humans in so many roles that they have earned the unique nickname, \"man's best friend\", a phrase used in other languages as well. They have been bred for herding livestock, hunting (e.g. pointers and hounds), rodent control, guarding, helping fishermen with nets, detection dogs, and pulling loads, in addition to their roles as companions. In 1957, a husky-terrier mix named Laika became the first animal to orbit the Earth.\n\nSource 3: In 1758, the taxonomist Linnaeus published in Systema Naturae a categorization of species which included the Canis species. Canis is a Latin word meaning dog, and the list included the dog-like carnivores: the domestic dog, wolves, foxes and jackals. The dog was classified as Canis familiaris, which means \"Dog-family\" or the family dog. On the next page he recorded the wolf as Canis lupus, which means \"Dog-wolf\". In 1978, a review aimed at reducing the number of recognized Canis species proposed that \"Canis dingo is now generally regarded as a distinctive feral domestic dog. Canis familiaris is used for domestic dogs, although taxonomically it should probably be synonymous with Canis lupus.\" In 1982, the first edition of Mammal Species of the World listed Canis familiaris under Canis lupus with the comment: \"Probably ancestor of and conspecific with the domestic dog, familiaris. Canis familiaris has page priority over Canis lupus, but both were published simultaneously in Linnaeus (1758), and Canis lupus has been universally used for this species\", which avoided classifying the wolf as the family dog. The dog is now listed among the many other Latin-named subspecies of Canis lupus as Canis lupus familiaris.\n\nSource 4: There have been two major trends in the changing status of pet dogs. The first has been the 'commodification' of the dog, shaping it to conform to human expectations of personality and behaviour. The second has been the broadening of the concept of the family and the home to include dogs-as-dogs within everyday routines and practices.\n\nSource 5: Domestic dogs have been selectively bred for millennia for various behaviors, sensory capabilities, and physical attributes. Modern dog breeds show more variation in size, appearance, and behavior than any other domestic animal. Dogs are predators and scavengers, and like many other predatory mammals, the dog has powerful muscles, fused wrist bones, a cardiovascular system that supports both sprinting and endurance, and teeth for catching and tearing.\n\nSource 6: In 14th-century England, hound (from Old English: hund) was the general word for all domestic canines, and dog referred to a subtype of hound, a group including the mastiff. It is believed this \"dog\" type was so common, it eventually became the prototype of the category \"hound\". By the 16th century, dog had become the general word, and hound had begun to refer only to types used for hunting. The word \"hound\" is ultimately derived from the Proto-Indo-European word *kwon- \"dog\".\n\nSource 7: The cohabitation of dogs and humans would have greatly improved the chances of survival for early human groups, and the domestication of dogs may have been one of the key forces that led to human success.\n\nSource 8: Medical detection dogs are capable of detecting diseases by sniffing a person directly or samples of urine or other specimens. Dogs can detect odour in one part per trillion, as their brain's olfactory cortex is (relative to total brain size) 40 times larger than humans. Dogs may have as many as 300 million odour receptors in their nose, while humans may have only 5 million. Each dog is trained specifically for the detection of single disease from the blood glucose level indicative to diabetes to cancer. To train a cancer dog requires 6 months. A Labrador Retriever called Daisy has detected 551 cancer patients with an accuracy of 93 percent and received the Blue Cross (for pets) Medal for her life-saving skills.\n------\nQuery: What was undertaken in 2010 to determine where dogs originated from?\nAnswer:", "role": "system"}]}
which contains 8 sources.
Join our Discord community and dive into discussions on tricks and tips for mastering Retrieval Augmented Generation
Summary
We have shown a simple and effective strategy to reduce RAG costs by adapting the number of supporting documents to LLM behavior on a given question. The approach builds on the ability of LLMs to know when they don’t know how to answer. With proper LLM confidence calibration the adaptive RAG is as accurate as a large context base RAG, while being much cheaper to run.
Beyond cost savings, the adaptive RAG offers better model explainability - questions are answered using a small number of supporting documents, helping to see which documents are truly relevant to the answers and allowing better tracing of LLM answer lineages.
At Pathway we are very excited about inventing new improvements to foundational LLM techniques and we are actively working on providing an integrated RAG pipeline in which the document index and LLMs collaborate to return the best answers, complete with self-tuning indexes to better rank documents for the needs of the LLM. Connect with me or drop me a line if you are interested! And share your cost-cutting strategies with me.