Word Vector Relationships
Navigating the landscape of text representation, it's essential to grasp how words relate to each other in vector form. In the upcoming video, Anup Surendran dives into the history of word vectors and takes a closer look at Google's groundbreaking Word2Vec project. Why are vector relationships so critical, and what biases do they bring?
Let's find out!
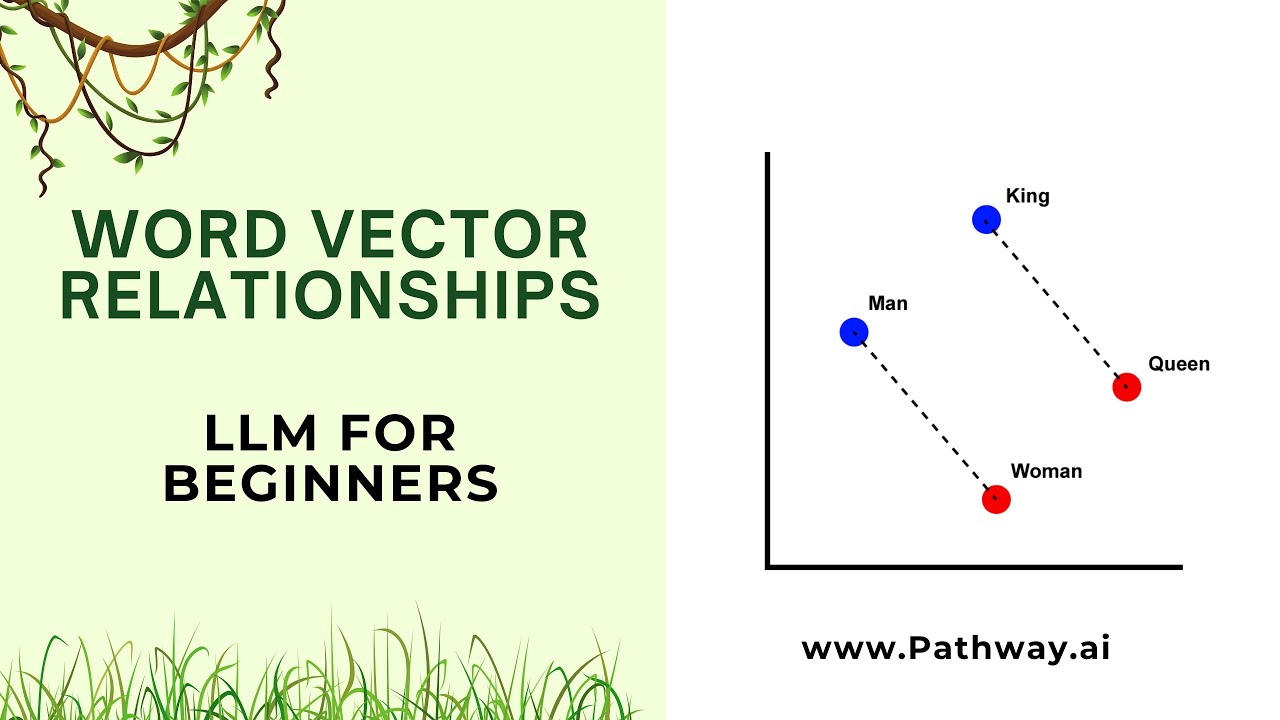
In this segment, Anup delves into the development of word vectors, highlighting the significant advancement made by Google's Word2Vec project. A remarkable aspect of Word2Vec is its ability to perform vector arithmetic, enabling mathematical operations with words. A classic example illustrating this feature is the equation "King - Man + Woman = Queen," demonstrating the intuitive understanding of relationships between words.
The video further examines how word vector relationships contribute to similarity searches, a crucial function in large language models. Additionally, Anup addresses an essential topic: the biases present in these technological advancements. Recognizing and understanding these biases is vital, not only for a deeper comprehension of Large Language Models but also for their ethical application. 🌐
💡 A practical insight
The terms "vector embeddings" and "word vectors" are often used interchangeably when discussing LLMs. These embeddings are stored in vector indexes, which are sophisticated data structures designed for fast and accurate retrieval of information based on these embeddings.
The rise of LLMs has spurred the development of specialized 'databases' focused on managing vector indexes. Platforms like Pinecone, Weaviate, ChromaDB, Mills etc., are prime examples of such databases.
However, these databases are not mandatory in every production-grade application of LLMs. We'll delve into this later in the course. For the moment, being familiar with these terms and their relevance to LLMs is a great starting point.
How to Choose the Right Vector Embeddings Model
Selecting the appropriate model for generating embeddings is an intriguing topic on its own. It's essential to recognize that there isn't a one-size-fits-all solution in this domain. A glance at this MTEB Leaderboard on Hugging Face reveals a variety of embedding models, each tailored for specific applications. Currently, OpenAI's
text-embedding-ada-002 is a commonly used ago-to model for producing efficient vector embeddings from diverse data, whether structured or unstructured. But like we've moved from GPT-2 to GPT-3, and now GPT-4, these embedding models are also bound to evolve and become more efficient. We'll delve deeper into its utilization in our tutorials by the end of this course.