Multi-Head Attention and Transformer Architecture
Building on the foundation of self-attention, Transformers use a more refined approach using the concept of Multi-Head Attention. This mechanism enhances the model's ability to focus on different parts of the input for various reasons.
Let's understand Multi-Head Attention
The basic idea of multi-head attention is simple. Think of Multi-Head Attention as having several pairs of eyes (or "heads") looking at the same sentence. Each pair of eyes focuses on different parts of the sentence, capturing various details.
- How it makes a difference: Normally, in attention mechanisms, we use one set of Q (query), K (key), and V (value) to understand the sentence. In Multi-Head Attention, we split this process into several smaller parts, with each part having its own Q, K, and V. This means we can pay attention to different parts of the sentence simultaneously.
- This method allows us to get a richer understanding of the sentence. Each head might notice different things - some might focus on grammar, while others might look for emotion or specific keywords.
Example in Simple Code: Suppose we decide to have two heads. Here's a simple way to visualize this in code:
# Let's say we have 2 heads
number_of_heads = 2
# We divide Q, K, and V for each head
divided_Q = np.split(Q, number_of_heads)
divided_K = np.split(K, number_of_heads)
divided_V = np.split(V, number_of_heads)
# Now, each head does its own attention
attention_results = []
for q, k, v in zip(divided_Q, divided_K, divided_V):
attention_results.append(calculate_attention(q, k, v))
# Finally, we combine the results from each head
combined_attention = np.concatenate(attention_results)
In summary, Multi-Head Attention allows Transformers to process information in parallel, significantly enhancing their ability to understand and interpret complex language data by examining it from multiple perspectives simultaneously.
Sample Implementation
- Creating Multiple Heads: You create several sets of weight matrices (for Q, K, V) corresponding to the number of heads.
- Applying Attention Independently: Each head performs the attention mechanism independently, as we did with single-head attention.
- Combining Outputs: Finally, the outputs from all heads are concatenated and possibly linearly transformed to produce the final output.
Role of Positional Encodings
Transformers, in addition to Multi-Head Attention, employ Positional Encodings to understand word order, which is vital for processing sentences. This technique assigns a sequence number to each word, such as ("Building", 1), ("LLM", 2), ("Apps", 3), enabling the Transformer to identify the order of words even when processing them all at once. This is crucial because, unlike sequential models like RNNs that naturally read words one by one, Transformers work on entire sentences simultaneously using parallel processing, making them fast but initially unaware of word order – a gap filled by Positional Encodings.
Positional Encodings aren’t limited to simple integer incremental sequences like in the case of ("Building", 1), ("LLM", 2), ("Apps", 3). There are various methods to calculate them. The authors of the Transformer model used a more complex approach. Their method uses sinusoidal waves of different frequencies, allowing the model to attend to relative positions in the input sequence effectively.
and
The first formula here is for calculating PE (Positional Encodings) for even indices (2i) and the second one is for odd indices. In these formulas, pos refers to the position in the sequence, i is the dimension, and is the dimension of the model.
Putting it together: Transformers Architecture
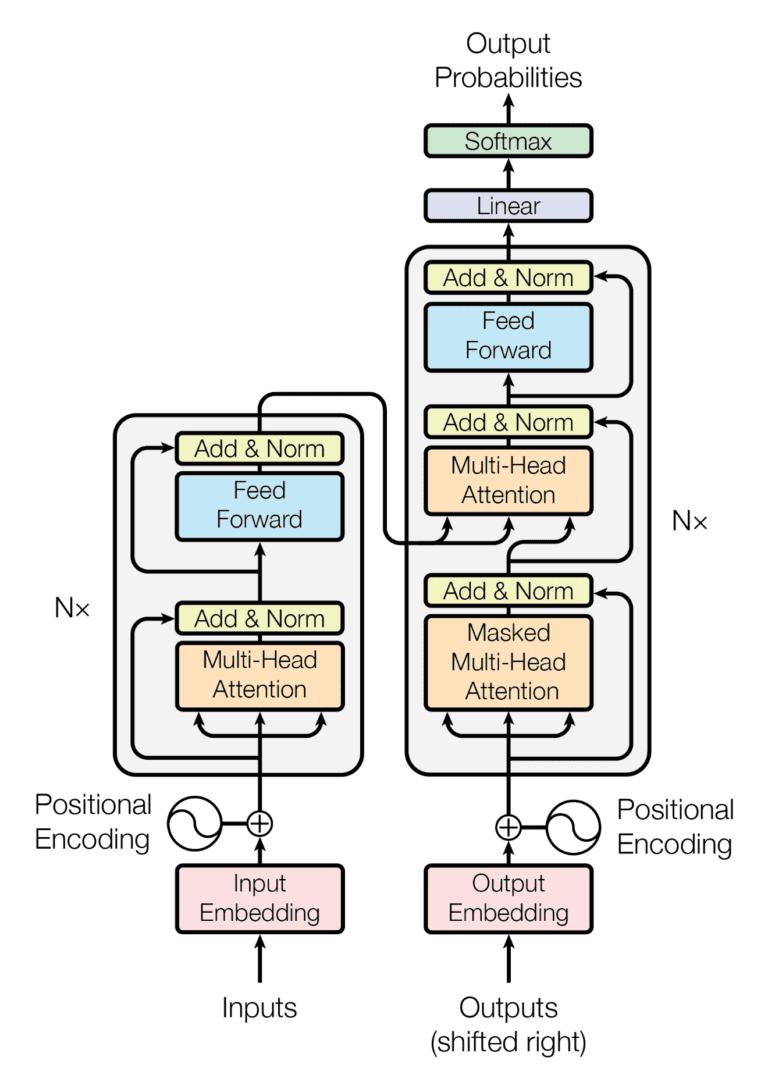
Source: "Attention Is All You Need" by Vaswani et al. 2017
The Transformer model's architecture, prominently featuring an Encoder and a Decoder, is a marvel of design in language processing. The left side of the diagram is the Encoder: This part of the model processes the input data. And the right side is the Decoder, which is responsible for generating the output, based on the processed input from the Encoder.
By now, you can already recognize a few of the components in this diagram. Before we quickly summarize how it works, let's cover some key components we haven't discussed yet.
- Feed Forward Neural Network: Present in each layer of both the Encoder and Decoder, these neural networks perform additional transformations on the data. It's crucial for capturing complex patterns in data, making the model better at handling language nuances.
- Add & Norm: It's a bit like double-checking work. This step, included in every layer, involves adding the original input back into the output (residual connection) and then normalizing it. This is vital for addressing a common issue in training deep networks known as the vanishing gradient problem. In simpler terms, as a network learns, updates to its weights can become very small, almost "vanishing." This makes learning very slow or even stops it. The residual connections help by ensuring that there’s always a flow of gradients, keeping the learning process alive and effective.
- Linear Layer and Softmax in Decoder: The Decoder ends with a Linear layer and a Softmax function. Hence these components are key to generating the output sequence. The Linear layer predicts the next word, and Softmax turns these predictions into probabilities. This combination ensures the model selects the most appropriate next word, building the output sequence one word at a time.
Bringing It All Together
- Processing the Input: In the Encoder, the input sentence is processed with attention mechanisms and positional encodings, capturing its full context in parallel.
- Generating the Output: The Decoder, using the processed data from the Encoder, attentively constructs the output, ensuring each word fits accurately in the sequence.
- Parallel Efficiency: This parallel processing approach marks a significant advancement over older sequential models, making the Transformer faster and more adept at understanding and generating language.
Video Lecture on Transformers by Andrej Karpathy
To enhance your understanding of this topic further, we recommend watching a detailed video by Andrej Karpathy, who previously led the AI team at Tesla. His session at Stanford University can provide a deeper and more nuanced perspective on the subject.
Resources for Further Study
To delve deeper into the intricacies of Transformers and Multi-Head Attention, here are some resources you can explore:
- Original Paper: "Attention Is All You Need" by Vaswani et al. - This seminal paper introduced the Transformer model. It's a must-read for understanding the theoretical foundations.
- The Illustrated Transformer: An accessible and visually-oriented explanation of how Transformers work, including Multi-Head Attention.
- Jan Chorowski's Course Materials: This is a compilation of resources for Jan Chorowski's Deep Learning and Neural Networks course at the University of Wrocław. Interestingly, Jan has co-authored several papers with Yoshua Bengio, the very same Bengio renowned for his pivotal work in introducing neural networks to the global scientific community.
- BERT Explained: Since the introduction of BERT (Bidirectional Encoder Representations from Transformers), the landscape of language understanding and generation has undergone a significant transformation. BERT’s architecture, powered by multi-head attention, allowed models to understand the context of words in a sentence more effectively than ever before. This was a pivotal moment leading to the development of more sophisticated models such as GPT (Generative Pre-trained Transformer), T5 (Text-to-Text Transfer Transformer), and others. These modern architectures have built upon and evolved from BERT's foundational principles, incorporating improvements in training efficiency, model scaling, and the ability to handle a broader range of tasks.
These resources will guide you through the theoretical concepts, practical implementations, and the broader impact of Transformers and Multi-Head Attention in the field of natural language processing.