How to use ChatGPT API in Python for your real-time data

 Bobur Umurzokov
Bobur Umurzokov![]()
How to use ChatGPT API in Python for your real-time data
OpenAI's GPT has emerged as the foremost AI tool globally and is proficient at addressing queries based on its training data. However, it can not answer questions about unknown topics:
- Recent events after Sep 2021.
- Your non-public documents.
- Information from past conversations.
This task gets even more complicated when you deal with real-time data that frequently changes. Moreover, you cannot feed extensive content to GPT, nor can it retain your data over extended periods. In this case, you need to build a custom LLM (Language Learning Model) app efficiently to give context to the answer process. This piece will walk you through the steps to develop such an application utilizing the open-source LLM App library in Python. The source code is provided as a showcase at GitHub.
Get started with Pathway Live Data Framework Realtime Document AI pipelines with our step-by-step guide, from setup to live document sync. Explore built-in features like Similarity Search, Vector Index, and more!
Learning objectives
You will learn the following throughout the article:
- The reason why you need to add custom data to ChatGPT.
- How to use embeddings, prompt engineering, and ChatGPT for better question answering.
- Build your own ChatGPT with custom data using LLM App.
- Create a ChatGPT Python API for finding real-time discounts or sales prices.
Why provide ChatGPT with a custom knowledge base?
Before jumping into the ways to enhance ChatGPT, let's first explore the manual methods of doing so and identify their challenges. Typically, ChatGPT is expanded through prompt engineering. Assume that you want to find real-time discounts/deals/coupons from various online markets.
For example, when you ask ChatGPT “Can you find me discounts this week for Adidas men's shoes?”, a standard response you can get from the ChatGPT UI interface without having custom knowledge is:
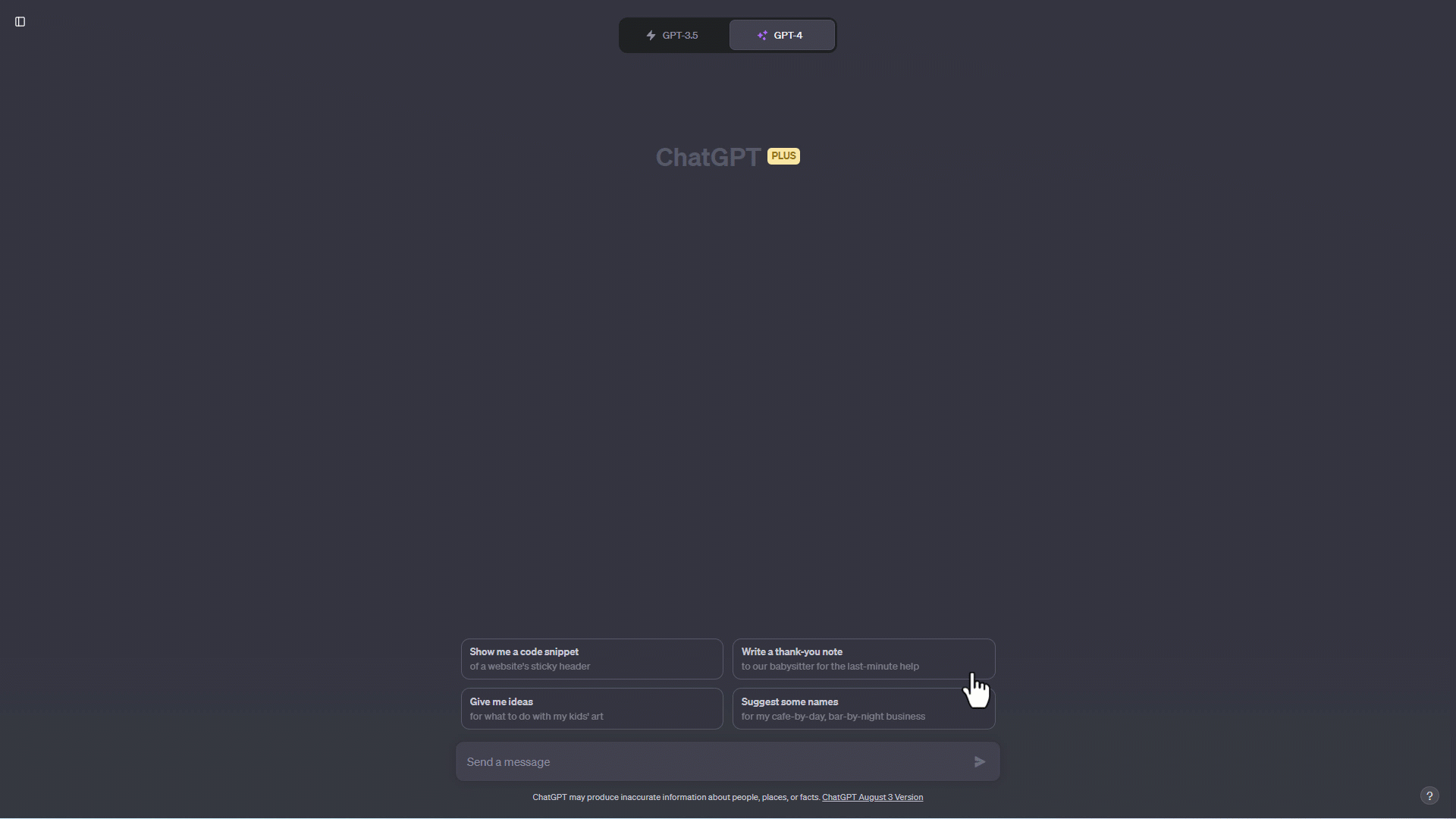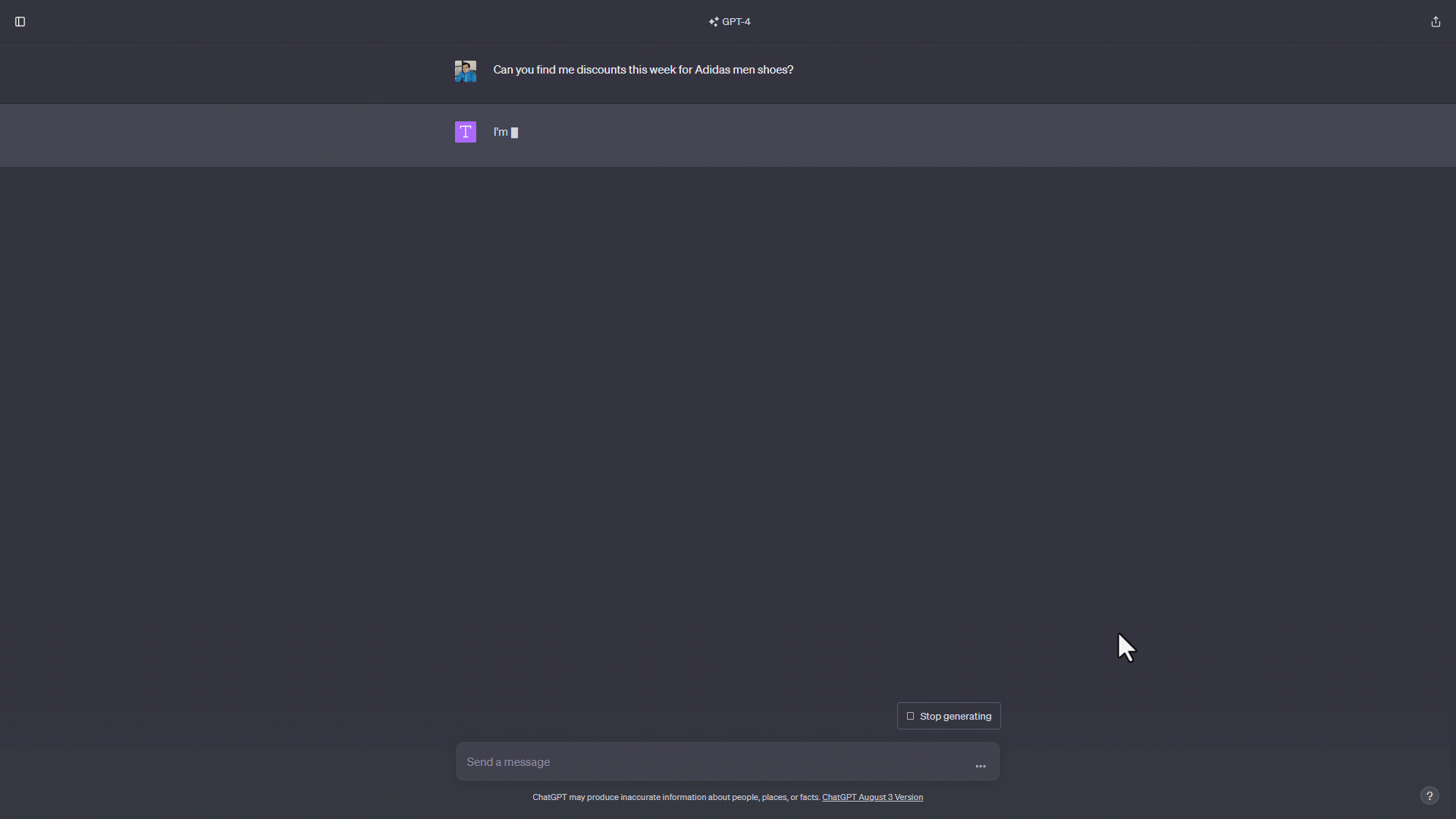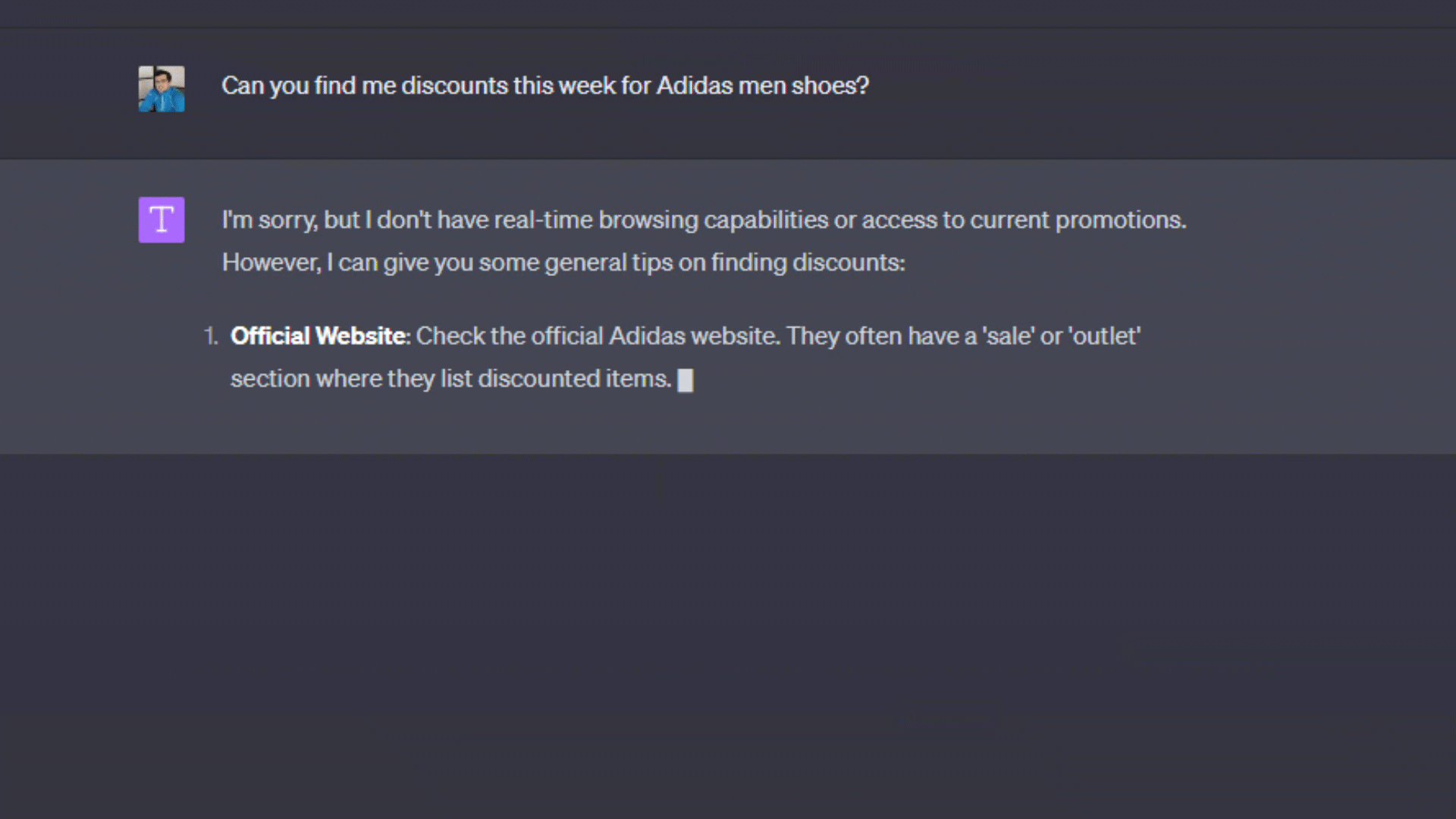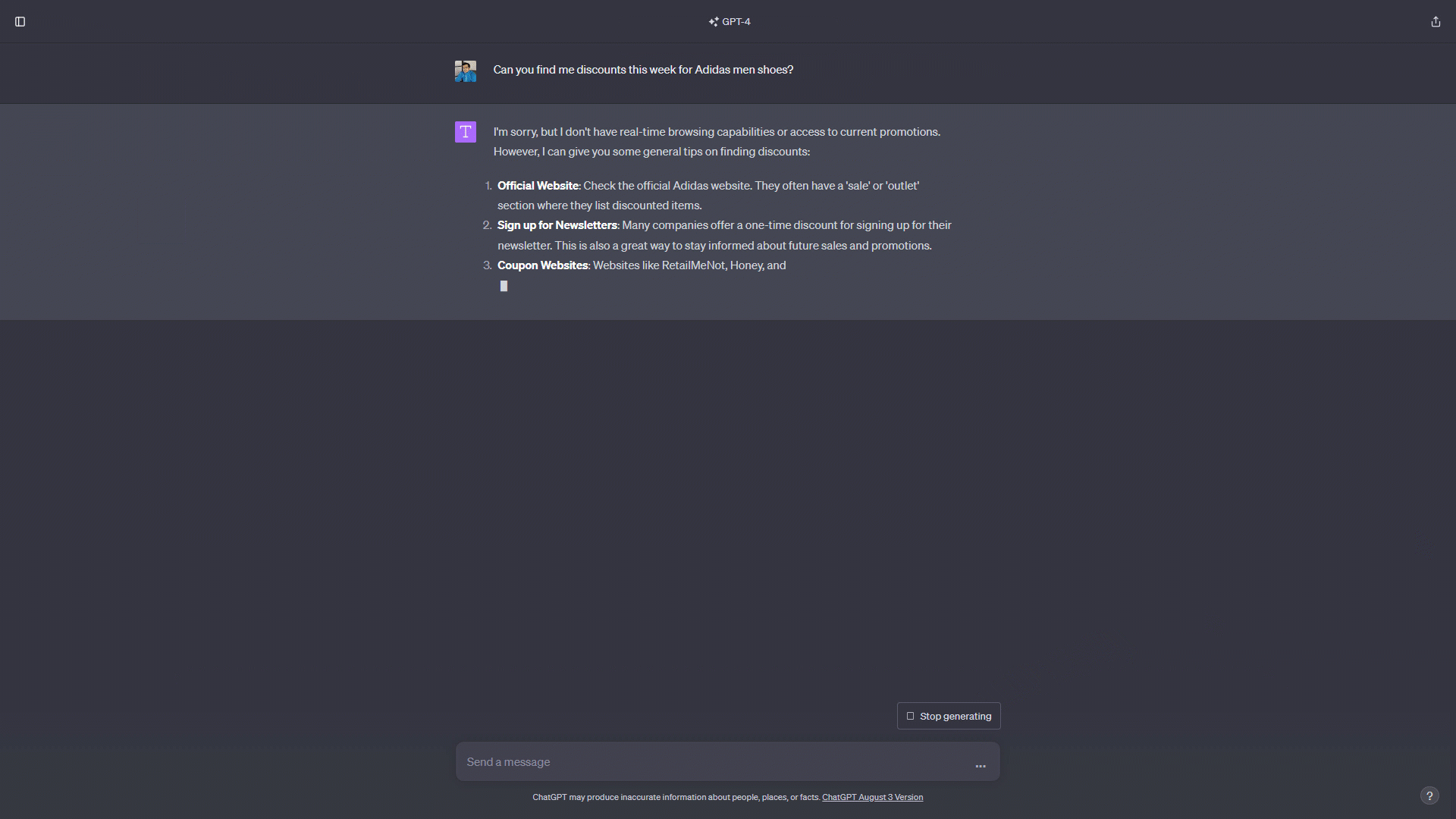
As evident, GPT offers general advice on locating discounts but lacks specificity regarding where or what type of discounts, among other details. Now to help the model, we supplement it with discount information from a trustworthy data source. You must engage with ChatGPT by adding the initial document content prior to posting the actual questions. We will collect this sample data from the Amazon products deal dataset and insert only a single JSON item we have into the prompt:
As you can see, you get the expected output and this is quite simple to achieve since ChatGPT is context aware now. However, the issue with this method is that the model's context is restricted; (gpt-4 maximum text length is 8,192 tokens). This strategy will quickly become problematic when input data is huge you may expect thousands of items discovered in sales and you can not provide this large amount of data as an input message. Also, once you have collected your data, you may want to clean, format, and preprocess data to ensure data quality and relevancy. If you utilize the OpenAI Chat Completion endpoint or build custom plugins for ChatGPT, it introduces other problems as followings:
- Cost - By providing more detailed information and examples, the model's performance might improve, though at a higher cost (For GPT-4 with an input of 10k tokens and an output of 200 tokens, the cost is $0.624 per prediction). Repeatedly sending identical requests can escalate costs unless a local cache system is utilized.
- Latency - A challenge with utilizing ChatGPT APIs for production, like those from OpenAI, is their unpredictability. There is no guarantee regarding the provision of consistent service.
- Security - When integrating custom plugins, every API endpoint must be specified in the OpenAPI spec for functionality. This means you're revealing your internal API setup to ChatGPT, a risk many enterprises are skeptical of.
- Offline Evaluation - Conducting offline tests on code and data output or replicating the data flow locally is challenging for developers. This is because each request to the system may yield varying responses.
Using embeddings, prompt engineering, and ChatGPT for question answering
A promising approach you find on the internet is utilizing LLMs to create embeddings and then constructing your applications using these embeddings, such as for search and ask systems. In other words, instead of querying ChatGPT using the Chat Completion endpoint, you would do the following query:
Given the following discounts data: {input_data} answer this query: {user_query}
The concept is straightforward. Rather than posting a question directly, the method first creates vector embeddings through OpenAI API for each input document (text, image, CSV, PDF, or other types of data), then indexes generated embeddings for fast retrieval and stores them into a vector database and leverages the user's question to search and obtain relevant documents from the vector database. These documents are then presented to ChatGPT along with the question as a prompt. With this added context, ChatGPT can respond as if it's been trained on the internal dataset.
On the other hand, if you use Pathway’s LLM App, you don’t need even any vector databases. It implements real-time in-memory data indexing directly reading data from any compatible storage, without having to query a vector document database that comes with costs like increased prep work, infrastructure, and complexity. Keeping source and vectors in sync is painful. Also, it is even harder if the underlined input data is changing over time and requires re-indexing.
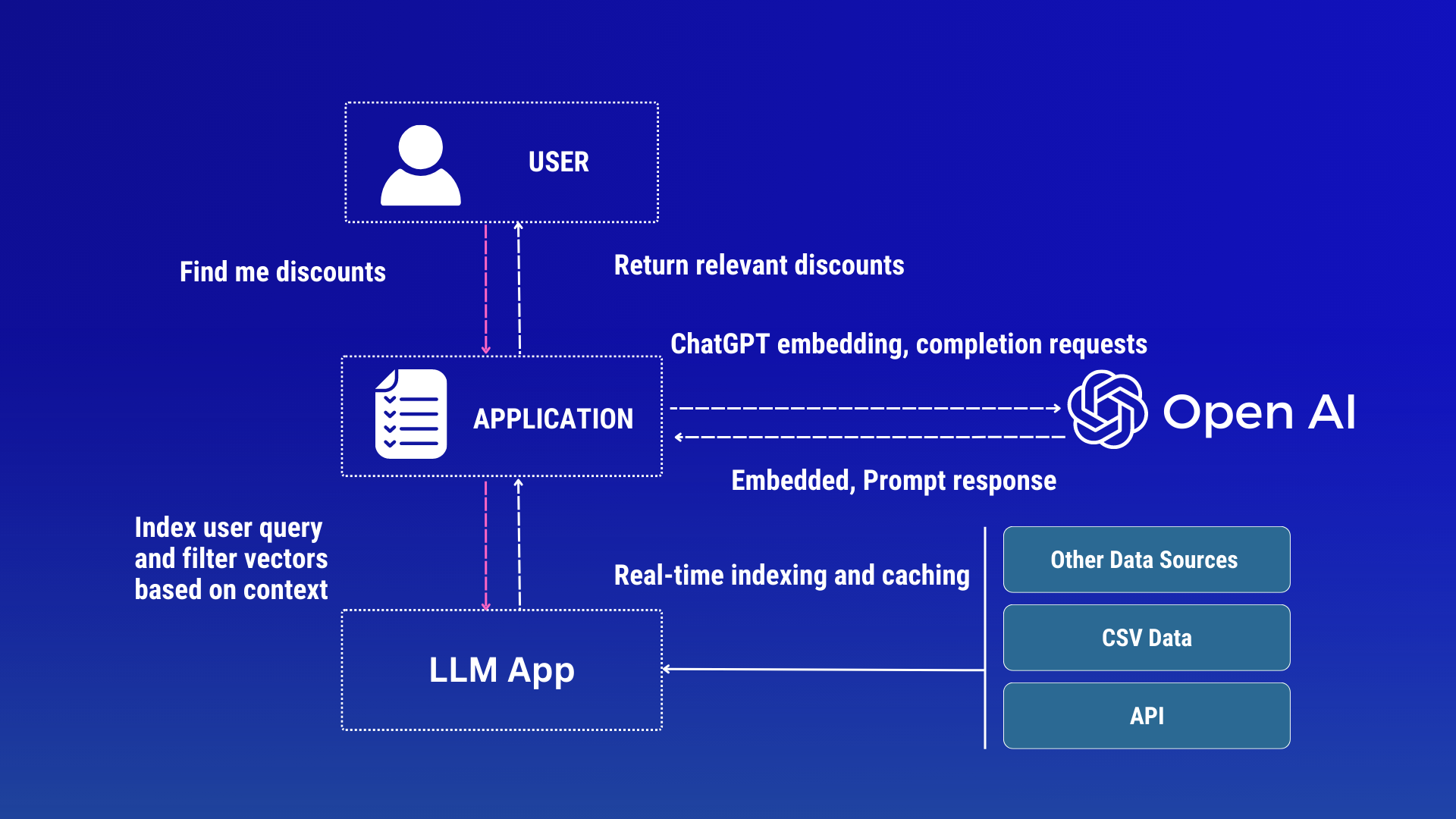
ChatGPT with custom data using LLM App
These simple steps below explain a data pipelining approach to building a ChatGPT app for your data with LLM App.
- Prepare:
- Collect: Your app reads the data from various data sources (CSV, JsonLines, SQL databases, Kafka, Redpanda, Debezium, and so on) in real-time when a streaming mode is enabled with Pathway Live Data Framework (Or you can test data ingestion in static mode too). It also maps each data row into a structured document schema for better managing large data sets.
- Preprocess: Optionally, you do easy data cleaning by removing duplicates, irrelevant information, and noisy data that could affect your responses' quality and extracting the data fields you need for further processing. Also, at this stage, you can mask or hide privacy data to avoid them being sent to ChatGPT.
- Embed: Each document is embedded with the OpenAI API and retrieves the embedded result.
- Indexing: Constructs an index on the generated embeddings in real-time.
- Search
- Given a user question let’s say from an API-friendly interface, generate an embedding for the query from the OpenAI API.
- Using the embeddings, retrieve the vector index by relevance to the query on-the-fly.
- Ask
- Insert the question and the most relevant sections into a message to GPT
- Return GPT's answer (chat completion endpoint)
Build a ChatGPT Python API for sales
Once we have a clear picture of the processes of how the LLM App works in the previous section. You can follow the steps below to understand how to build a discount finder app. The project source code can be found on GitHub. If you want to quickly start using the app, you can skip this part and clone the repository and run the code sample by following the instructions in the README.md file there.
Sample project objective
Inspired by this article around enterprise search, our sample app should expose an HTTP REST API endpoint in Python to answer user queries about current sales by retrieving the latest deals from various sources (CSV, Jsonlines, API, message brokers, or databases) and leverages OpenAI API Embeddings and Chat Completion endpoints to generate AI assistant responses.
Step 1: Data collection (custom data ingestion)
For simplicity, we can use any CSV as a data source. The app takes CSV files like discounts.csv in the CSV folder and uses this data when processing user queries. Here is an example of a CSV file with a single raw:
| discount_until | country | city | state | postal_code | region | product_id | category | sub_category | brand | product_name | currency | actual_price | discount_price | discount_percentage | address |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2024-08-09 | USA | Los Angeles | IL | 22658 | Central | 7849 | Footwear | Men Shoes | Nike | Formal Shoes | USD | 130.67 | 117.60 | 10 | 321 Oak St |
The cool part is, the app is always aware of changes in the CSV folder. If you add another CSV file, the LLM app does magic and automatically updates the AI model's response. Discounts data generator Python script simulates real-time data coming from external data sources and generates/updates existing discounts.csv file with random data. For example, you generate the second CSV discounts2.csv file under the data folder to test the app's reaction to real-time data changes.
Step 2: Data loading and mapping
With the CSV input connector, we will read the local CSV file, map data entries into a schema (if all CSV fields are known) and create a Pathway Table. See the full source code in app.py:
...
sales_data = pw.io.csv.read(
"./examples/csv/data",
schema=CsvDiscountsInputSchema,
mode="streaming"
)
Map each data row into a structured document schema. See the full source code in app.py:
import pathway as pw
...
class CsvDiscountsInputSchema(pw.Schema):
discount_until: str
country: str
city: str
state: str
postal_code: str
region: str
product_id: str
category: str
sub_category: str
brand: str
product_name: str
currency: str
actual_price: str
discount_price: str
discount_percentage: str
address: str
...
Step 3: Data preprocessing
After our documents are loaded into a table, we transform each table row into a self-contained column called doc with column titles and values using the Pathway Apply function. See the full source code in transform.py:
...
def transform(sales_data):
return sales_data.select(
doc=pw.apply(concat_with_titles, **sales_data),
)
Step 4: Data embedding
Each document is embedded with the OpenAI API and retrieves the embedded result. See the full source code in embedder.py:
...
def contextful(context, data_to_embed):
return context + context.select(data=openai_embedder(data_to_embed))
...
Step 5: Data indexing
Then we construct an instant index on the generated embeddings:
index = index_embeddings(embedded_data)
Step 6: User query processing and indexing
We create a REST endpoint, take a user query from the API request payload, and embed the user query also with the OpenAI API.
...
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
embedded_query = embeddings(context=query, data_to_embed=pw.this.query)
...
Step 7: Similarity search and prompt engineering
We perform a similarity search by using index to identify the most relevant matches for the query embedding. Then we build a prompt that merges the user's query with the fetched relevant data results, send the message to ChatGPT Completion endpoint to produce a proper and detailed response.
responses = prompt(index, embedded_query, pw.this.query)
We followed the same in context learning approach when we crafted the prompt and added internal knowledge to ChatGPT in the prompt.py.
prompt = f"Given the following discounts data: \\n {docs_str} \\nanswer this query: {query}"
Step 8: Return the response
The final step is just to return the API response to the user
# Build prompt using indexed data
responses = prompt(index, embedded_query, pw.this.query)
# Feed the prompt to ChatGPT and obtain the generated answer.
response_writer(responses)
Step 9: Put everything together
Now if we put all the above steps together, you have LLM-enabled Python API for custom discounts data ready to use as you see the implementation in the app.py Python script.
import pathway as pw
from common.transform import transform
from common.embedder import embeddings, index_embeddings
from common.prompt import prompt
def run(host, port):
# Real-time data coming from external data sources such as csv file
sales_data = pw.io.csv.read(
"./examples/csv/data",
schema=CsvDiscountsInputSchema,
mode="streaming"
)
# Data source rows transformed into structured documents
documents = transform(sales_data)
# Compute embeddings for each document using the OpenAI Embeddings API
embedded_data = embeddings(context=documents, data_to_embed=documents.doc)
# Construct an index on the generated embeddings in real-time
index = index_embeddings(embedded_data)
# Given a user question as a query from your API
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
# Generate embeddings for the query from the OpenAI Embeddings API
embedded_query = embeddings(context=query, data_to_embed=pw.this.query)
# Build prompt using indexed data
responses = prompt(index, embedded_query, pw.this.query)
# Feed the prompt to ChatGPT and obtain the generated answer.
response_writer(responses)
# Run the pipeline
pw.run()
Running the app
Follow the instructions in the README.md file’s How to run the project section and you can start to ask questions about discounts, and the API will respond according to the discounts data source you have added.
When the user has the following query in the API request as we asked ChatGPT before and send this request to our API with curl command or using Postmancurl --data '{"query": "Can you find me discounts this week for Adidas men shoes?"}' http://localhost:8080/:
curl --data '{"query": "Can you find me discounts this week for Adidas men's shoes?"}' <http://localhost:8080/>
You will get the response with some discounts available based on your custom data (CSV file) as we expected.
Based on the given data, there is one discount available this week for Adidas men's shoes:
Available until 2023-10-28 in San Francisco, CA, USA.
Here is the cleaned output:
Discount Until: 2023-10-28
Country: USA\\nCity: San Francisco
State: CA\\nPostal Code: 87097
Region: West
Product ID: 9803
Category: Footwear
Sub-category: Men's Shoe
Brand: Adidas\\n
Product Name: Running Shoes
Currency: USD
Actual Price: 130
Discount Price: 76.30
Discount Percentage: 58%
Address: 321 Oak St
In case you use it as a data source Rainforest API provides real-time deals for Amazon products, you will get the following output for the same request:
Further Improvements
We've only discovered a few capabilities of the LLM App by adding domain-specific knowledge like discounts to ChatGPT. There are more things you can achieve:
- Incorporate additional data from external APIs, along with various files (such as Jsonlines, PDF, Doc, HTML, or Text format), databases like PostgreSQL or MySQL, and stream data from platforms like Kafka, Redpanda, or Debedizum.
- Merge data from these sources instantly.
- Maintain a data snapshot to observe variations in sales prices over time, as Pathway Live Data Framework provides a built-in feature to compute differences between two alterations.
- Beyond making data accessible via API, the LLM App allows you to relay processed data to other downstream connectors, such as BI and analytics tools. For instance, set it up to receive alerts upon detecting price shifts.
Related resources
Community
Join the Discord channel to see how the AI ChatBot assistant works that we built using LLM App.

 Olivier Ruas
Olivier Ruas blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework
blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework Saksham Goel
Saksham Goel blog · tutorial · engineeringFeb 5, 2025Real-Time AI Pipeline with DeepSeek, Ollama and Pathway
blog · tutorial · engineeringFeb 5, 2025Real-Time AI Pipeline with DeepSeek, Ollama and Pathway Shlok Srivastava
Shlok Srivastava blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework
blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework