Pathway Live Data Framework: Fastest Data Processing Engine - 2023 Benchmarks

 Pathway Team
Pathway TeamPathway Live Data Framework is the fastest data processing engine on the market – 2023 benchmarks
The Pathway Live Data Framework supports more advanced operations while being up to 90x faster than existing streaming solutions.

Read the full story about what and how we benchmarked, the benchmark results and why the framework is so powerful 👇
Traditional data processing systems are designed to either maximize throughput or minimize latency. Maximizing throughput means processing the largest data volume possible; this is usually done through batch computations. Minimizing latency means reducing the data processing time as much as possible; this is approached through stream processing. The Pathway Live Data Framework delivers both: low latencies for high data throughputs. It does so through its unified engine and single syntax for both batch and stream processing.
Our 2023 benchmarks show that the Pathway Live Data Framework is able to match or outperform current state-of-the-art solutions on representative streaming tasks, both in speed and complexity. This is why global organizations like La Poste and DB Schenker are adopting Pathway to deliver real-time data insights.
The short version: the Pathway Live Data Framework is fast, flexible and friendly. The Pathway Live Data Framework offers top-notch performance for data processing tasks, promotes developer joy and productivity by unifying code for batch and streaming systems, and eases adoption across organizations with its friendly Python and SQL APIs.
Jump in to learn more 🚀
What and How We Benchmarked
The 2023 streaming benchmarks compare Pathway against Kafka Streams, Spark and Flink on 2 types of tasks:
- A WordCount Benchmark to measure performance on a basic online streaming task. While the algorithm is meant to count words in a sentence, you can think of it in this context as the "unit test" of streaming tasks. Performance on this benchmark indicates that the foundational elements of a data streaming product are working as expected.
- A PageRank Benchmark to measure performance on more advanced tasks. The PageRank algorithm, named after Larry Page, is the key algorithm behind the success of Google and is used to rank web pages in search engine results. It is an iterative graph algorithm. Performance on this benchmark indicates a product's ability to handle advanced workloads.
All benchmarks were run on dedicated machines with: 12-core AMD Ryzen 9 5900X Processor, 128GB of RAM and SSD drives. All experiments were run using Docker, enforcing limits on used CPU cores and RAM consumption.
For an in-depth description of the benchmark design and implementation, read our arXiv preprint paper. The benchmarks can be reproduced from the public pathway-benchmarks Github repository.
Benchmark Results
The WordCount and PageRank benchmarks test platforms' ability to handle a wide range of streaming use cases. The benchmarks show that:
- The Pathway Live Data Framework outperforms state-of-the-art solutions for common data streaming tasks in most cases, especially for high throughput values.
- The Pathway Live Data Framework outperforms state-of-the-art solutions for advanced graph computations in all cases. Furthermore, the Pathway Live Data Framework is the only platform able to perform hybrid batch and streaming computations in a reliable and scalable manner.
In the sections below, we walk through each of the benchmark results in more detail.
Basic Streaming Performance (WordCount Benchmark)
As the name suggests, this benchmark counts the number of words in a stream of messages. The same algorithm is used as a foundational operation in most language models in order to discover word distributions. Examples of real-world applications include sentiment analysis, Search-Engine Optimization (SEO) and social media monitoring. The WordCount operation is also a representative example of a groupby operation, which is used in all SQL and database benchmarks.
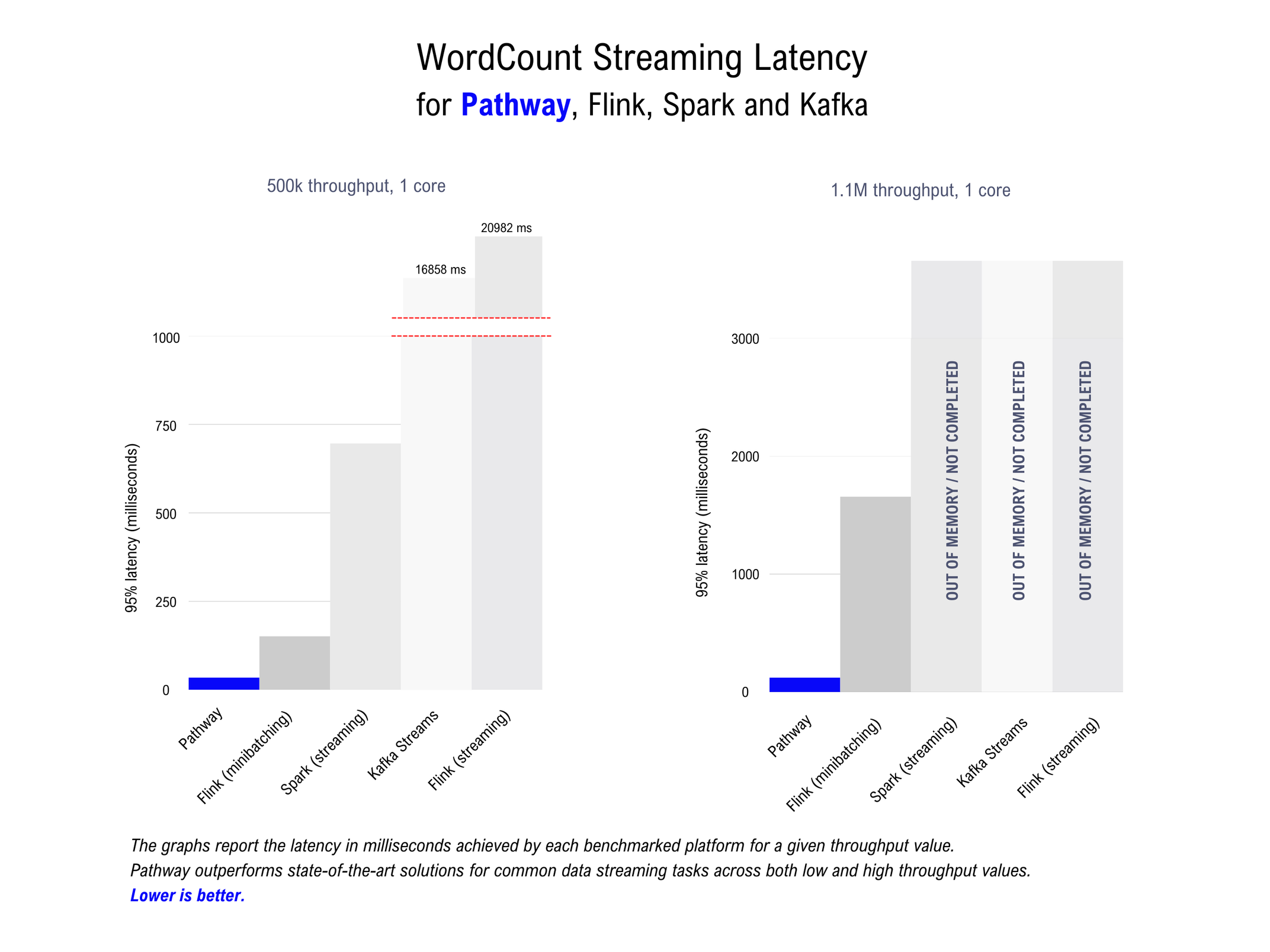
The WordCount benchmark measures an engine’s performance on a foundational streaming task. If an engine can’t do this well, it is unlikely to perform well at any more complex task. The latency with which the task is performed at various throughput rates is reported and used to compare solutions.
The graph below shows the results of the WordCount benchmark. 95% latency is reported in milliseconds (y-axis) per throughput value (x-axis).
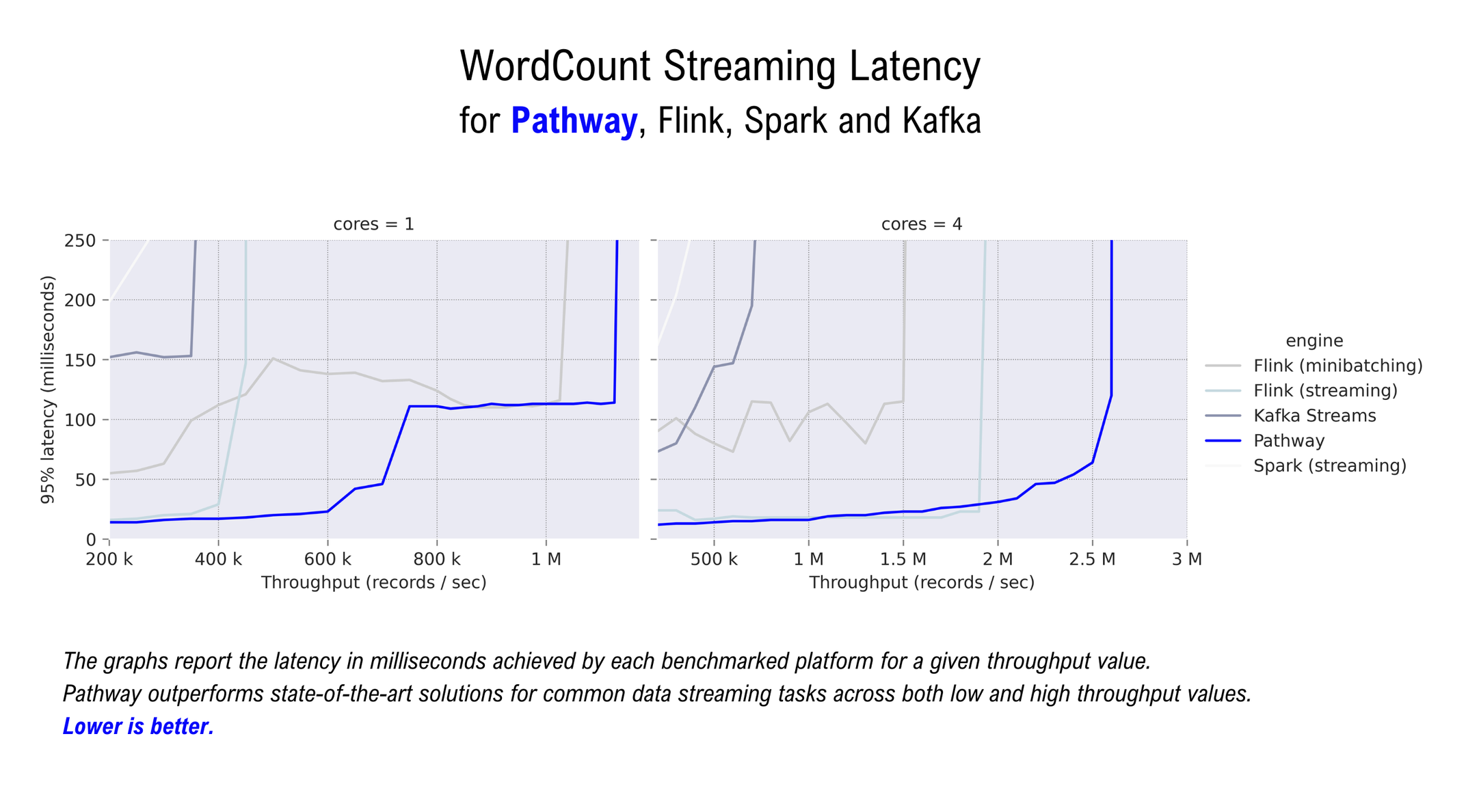
Pathway outperforms the default Flink streaming setup in terms of sustained throughput, and dominates the Flink minibatching setup in terms of latency for the throughput spectrum measured (200k-1.3M on a single-core machine; 200k-3M on a 4-core distributed streaming system). For most throughputs, Pathway also achieves lower latency than the better of the two Flink setups. The plots below show the Pathway Live Data Framework outperforms state-of-the-art solutions at both low and high throughput values.
So why does good performance on WordCount matter?
High performance on the WordCount benchmark is especially relevant for data aggregation and ETL workloads. Potential applications where performance gains will translate into significant cost reduction or computation speed-up include anomaly detection in event distributions, trend monitoring, and all types of real-time Natural Language Processing.
Pathway outperforms state-of-the-art solutions for common online streaming tasks at high throughput values.
Advanced Streaming Performance (PageRank Benchmark)
PageRank is the key algorithm behind the success of Google: it’s a graph algorithm used to score the importance of websites to then deliver users a smooth and relevant search experience. Iterative graph processing algorithms are also used in recommender systems, gradient descent algorithms, agent-based modeling and fraud detection in payment solutions, amongst many other applications. Graphs are omnipresent but graph algorithms are not always the easiest to implement. Some of the benchmarked engines do not support this type of task at all.
The PageRank benchmark is evaluated in three modes:
- Batch (static dataset)
- Streaming (live data stream)
- Backfilling (supplementing a live data stream with data points from a batch dataset)
The PageRank benchmarks are performed on the LiveJournal dataset. This social network graph dataset contains 4,847,571 nodes (or ‘pages’) and 68,993,773 edges (or ‘connections’). The algorithm ranks pages according to their importance, which is determined by the number of connections it has. Pages with a higher number of important connections (i.e. connections that themselves have more connections) will rank higher. This interdependence of one page’s importance on the importance of its connecting pages requires an iterative algorithm like PageRank, with multiple iterations over the graph to converge to a final result.
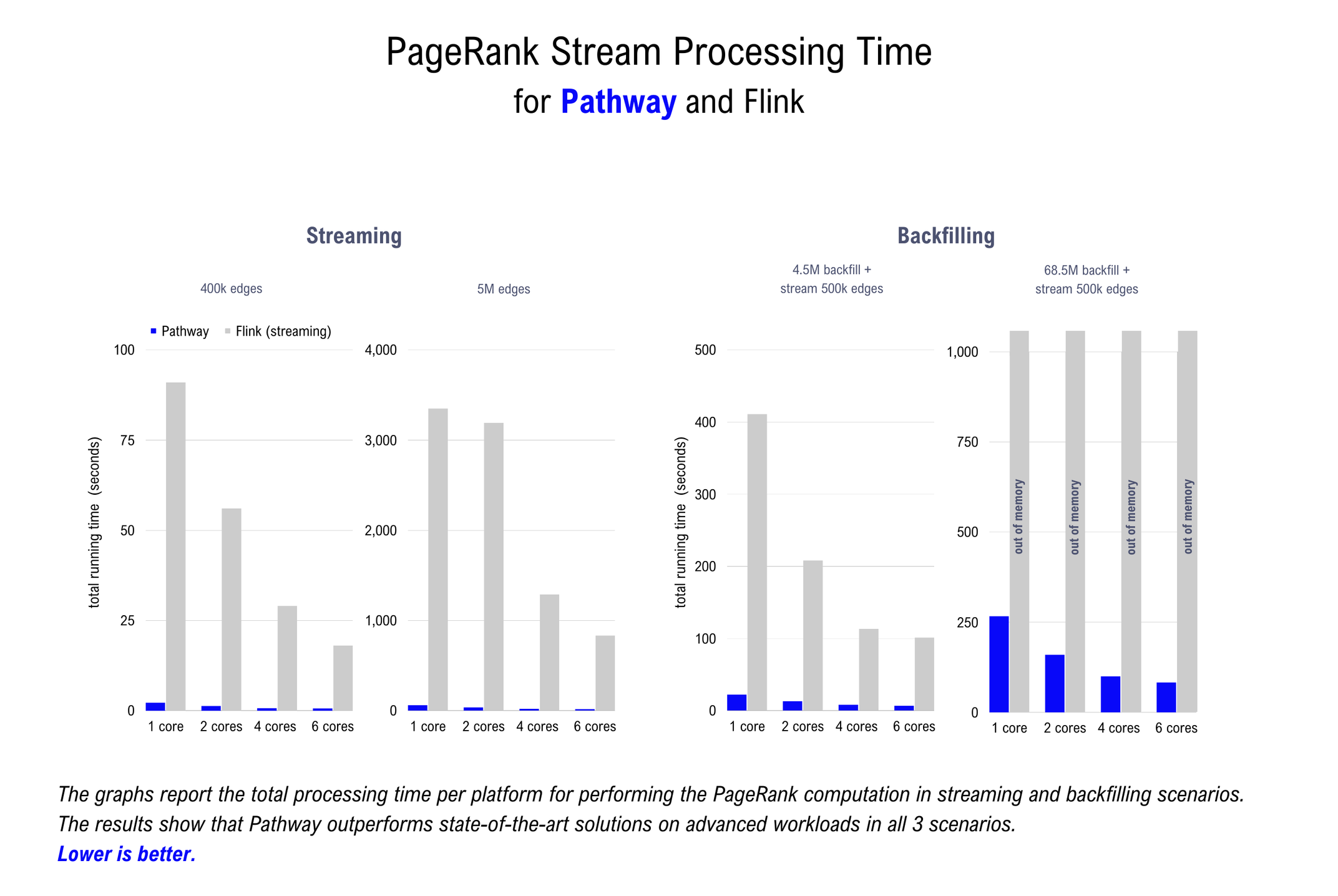
Pathway outperforms the benchmarked platforms across all three PageRank computation scenarios. Below, we dive deeper into each scenario and explain the relevance of the results.
PageRank (batch)
The table below shows the results of the PageRank benchmark in batch processing mode, meaning that the entire dataset is processed as a single chunk with no live streaming taking place. The total time to complete a batch PageRank computation on the LiveJournal is reported in seconds.
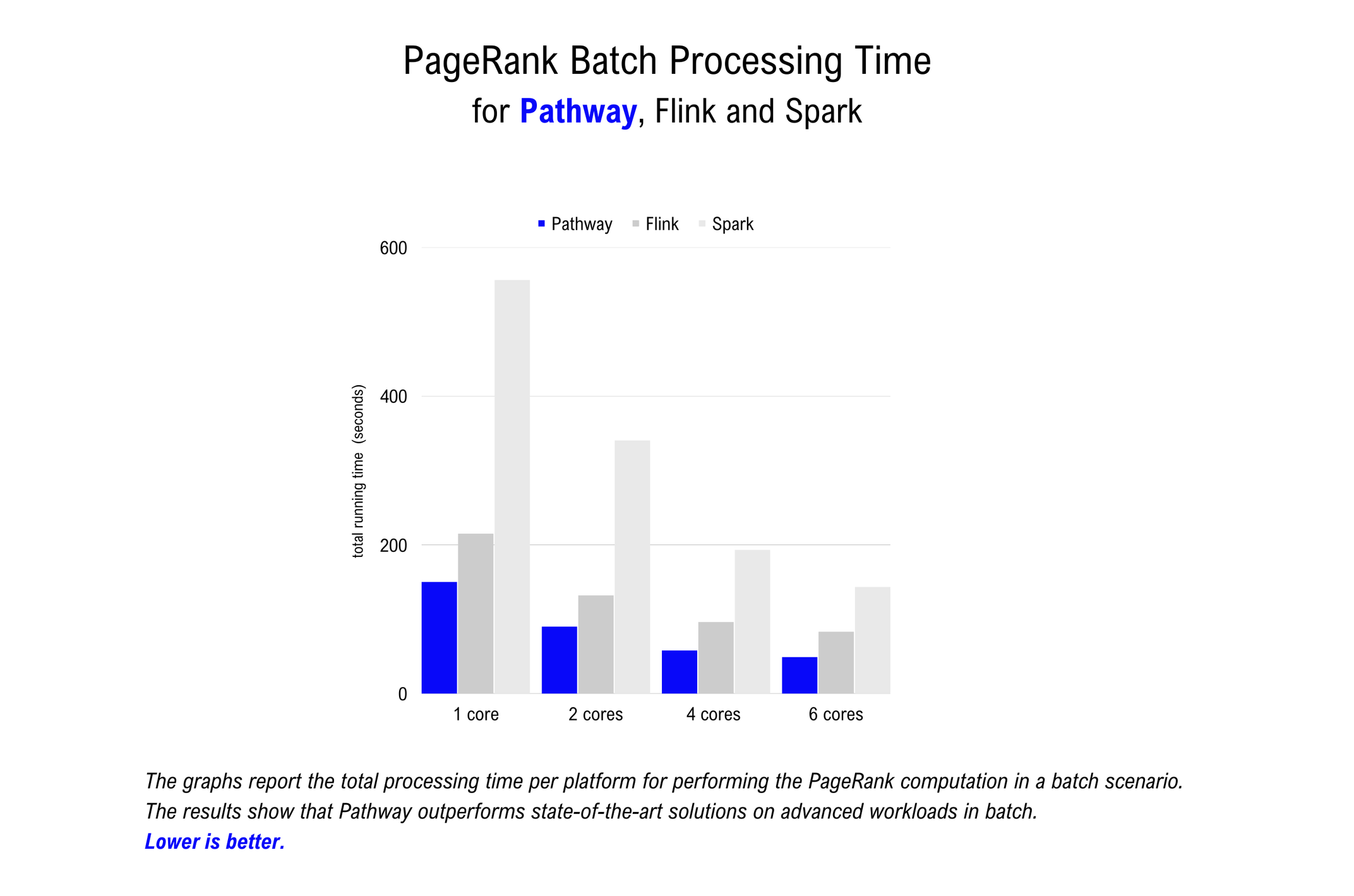
The Pathway Live Data Framework is consistently the fastest among engines with equivalent Table-like APIs, followed by Flink and Spark. Kafka Streams does not offer an API for batch computations and is therefore not included.
The results of this benchmark confirm that the Pathway Live Data Framework outperforms state-of-the-art solutions for complex computations in batch mode. Moving existing code for advanced batch computations to the framework will likely result in faster processing times and may significantly reduce your compute bill.
The Pathway Live Data Framework outperforms state-of-the-art solutions for iterative graph processing tasks in batch mode.
PageRank (streaming)
The second version of the PageRank benchmark evaluates the same task but now in a live streaming scenario. Data is generated and processed in real-time. This type of data processing offers real time insights because data processing can start as soon as the first data point arrives.
Switching from batch to stream processing has traditionally been a daunting task because it required major code rewrites. The Pathway Live Data Framework’s unified batch and streaming engine changes the paradigm. It is built to facilitate easy transitions from batch to streaming scenarios. By design, the framework requires no change in the code syntax to switch from batch to streaming: it provides one technology for both cases. The Flink batch code, on the other hand, will not run in a streaming setting and requires a significant rewrite.
The table below shows the results of the PageRank benchmark in streaming mode. The total running time to process the dataset is reported in seconds. In this benchmark, 1000 edges are sent at a time and the output graph is updated after each group of 1000 edges has been processed. Results are reported on subsets of the LiveJournal dataset containing 400k and 5M edges, respectively.
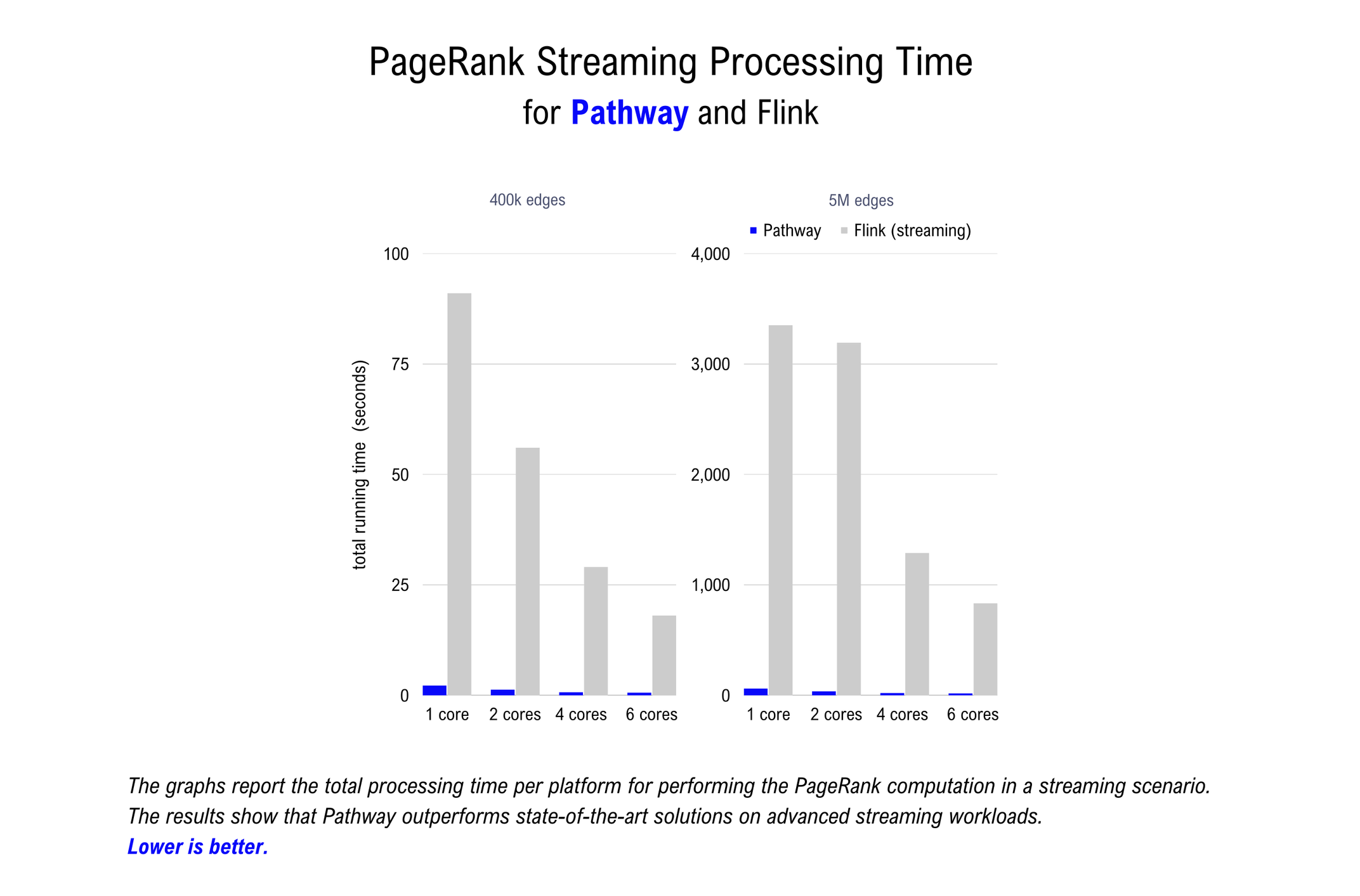
Only two systems are benchmarked on the streaming PageRank task: the Pathway Live Data Framework and Flink. The other engines showed suboptimal performance on the simple WordCount benchmark (Kafka) or do not support this kind of benchmark at all (Spark).
The Pathway Live Data Framework maintains a large advantage over Flink. This advantage is consistent across the number of cores and the number of processed edges, with a factor ranging from 30x to 90x. Extending the benchmarks to tests on larger datasets than those reported is problematic as Flink’s performance is degraded by memory issues. The results of this benchmark confirm that the Pathway Live Data Framework is the fastest data processing engine on the market for streaming tasks.
Because the Pathway Live Data Framework uses a single syntax and engine for both batch and stream processing, the barrier to setting up real-time streaming pipelines is significantly lowered. Organizations that have previously avoided building streaming pipelines because of the increased complexity and (human) resources required to translate existing codebases can use the framework to facilitate the switch to real-time.
This is crucial for many applications of PageRank-like processes, such as fraud detection, power-grid modeling or transportation flow forecasting. In situations like these, signals processed in batch can be rendered meaningless by the passage of time and the ability to detect and act in real-time can make all the difference. It’s about going from the status quo where businesses are dealing with data which is perpetually out-of-date, to always having the freshest actionable insights available.
The Pathway Live Data Framework is the fastest data processing engine on the market for advanced streaming tasks.
PageRank (backfilling)
The backfilling PageRank benchmark measures the engine’s ability to switch from batch to online during processing. This is helpful when dealing with delayed data-point arrival, a common occurrence in logistics and IoT deployments, for example. In this scenario, a stream of live data points needs to be updated or corrected to include data points that have arrived out-of-order.
The benchmark is performed on two versions of the LiveJournal dataset: a subset with 5 million edges and the full dataset with 69 million edges. The table below shows the results, with the time to process the dataset reported in seconds.
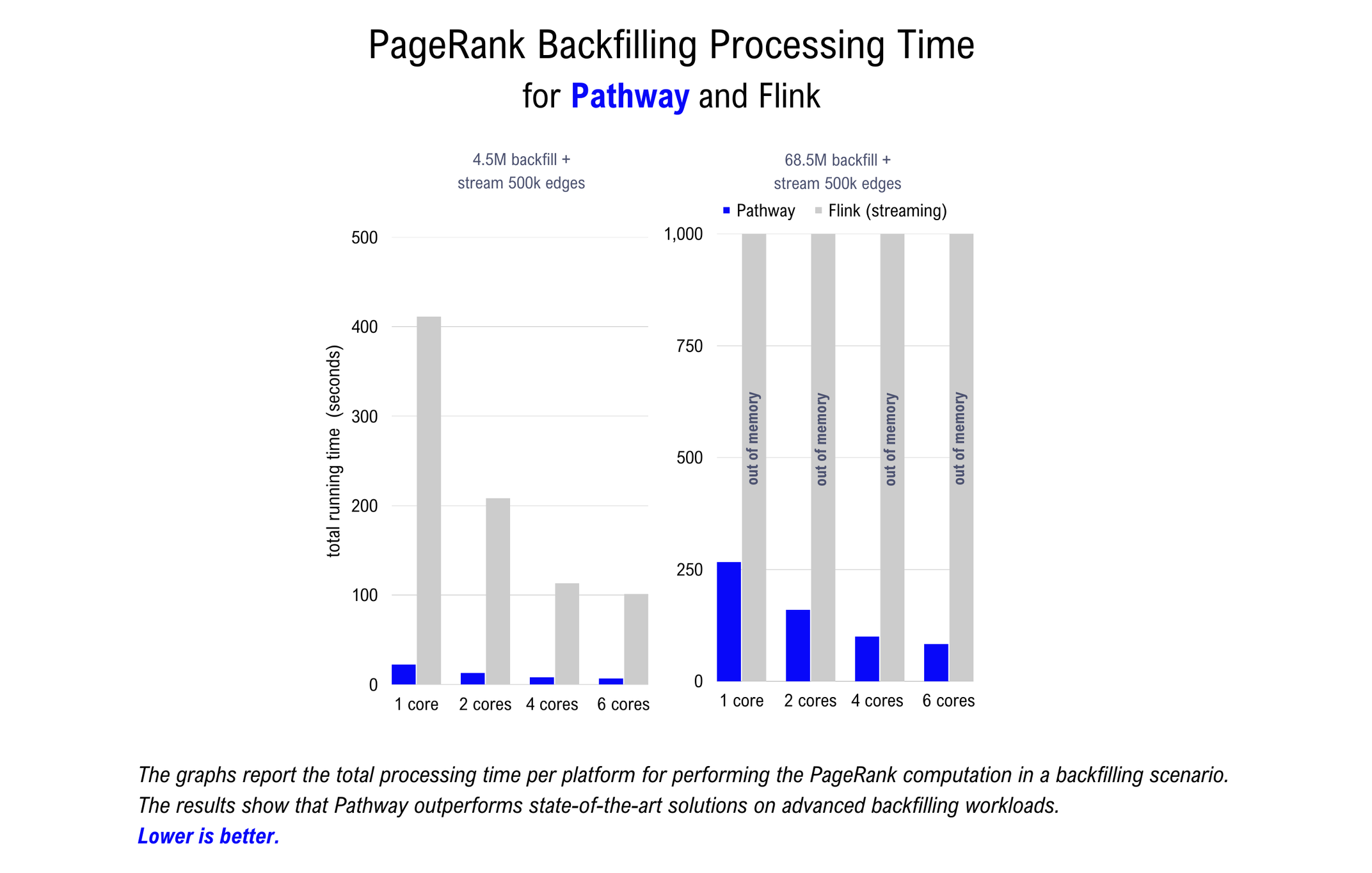
The Pathway Live Data Framework clearly offers superior performance. It outperforms Flink on the smaller dataset by a factor of approximately 20x. For the benchmark on the complete LiveJournal dataset, Flink either ran out of memory or failed to complete the task on 6 cores within 2 hours, depending on the setup.
The Pathway Live Data Framework is unique in its ability to mix batch and streaming workflows with a unified syntax and engine. Organizations working with other platforms regularly end up designing two systems: one system for batch (which is unable to work with streaming sources) and one system for streaming (which is unable to enrich streams with batch data or perform backfilling). The streaming system allows for preliminary conclusions to be drawn from the incomplete data within seconds, but the arrival of delayed data points means that these preliminary results will often need to be revised and updated. Rerunning the entire pipeline in batch mode is often too costly. The framework offers an efficient solution by combining streaming and batch in a single workflow to provide incremental updates.
The Pathway Live Data Framework is uniquely able to perform hybrid batch and streaming computations at scale.
Why is the Pathway Live Data Framework so Fast?
The engine is built in Rust. We love Rust 🦀. Rust is built for speed, parallel computation and low-level control over hardware resources. This allows us to execute maximum optimization for performance and speed.
We also love Python 🐍 – which is why you can write your data processing code in Python and the Pathway Live Data Framework will automagically compile it into a Rust dataflow. In other words, with the framework you don’t need to know anything about Rust to enjoy its enormous performance benefits! (that said, Rust is a great language, so don’t hesitate to learn it 🙂).
>> t_age.filter(pw.this.age>30)
| age
^Z3QWT29... | 32
All I/O operations in the Pathway Live Data Framework are performed using highly-optimized Rust libraries and native Rust data parsing and formatting. There are multiple stages of optimization on this dataflow to ensure that the basic data transformations are being used as efficiently as possible.
Whenever you write a user-defined function in Python, chances are that it will also be converted into Rust to allow for easy parallel and distributed execution…and because it’s simply faster :) For functions which remain native in Python, e.g. API calls or use of external libraries, the engine ensures that the Rust-to-Python bridge is streamlined and fast.
The engine keeps state in memory so that, whenever possible, particular stages of a computation do not require disk-access or network communication, both of which are costly and slow. Furthermore, the dataflow design has been planned from the outset for simplicity, efficiency and scalability and has been developed and executed by a core team over the course of just two years. This has allowed the framework to avoid the kind of ‘architecture drift’ that many OSS projects in the space have suffered.
Last but not least, we have learned from the best...and gone further. By benchmarking a range of scenarios against other frameworks we have been able to identify places where we were underperforming and, by adopting industry best practices, have been able to find ways to overcome these bottlenecks and boost performance.
Speed isn't Everything
A fast sports car is great for weekend days when the sun is out. But most of the time, you’ll also want something that’s comfortable and easy-to-handle: something that will reliably get you where you need to go without too much fuss.
The Pathway Live Data Framework is built to deliver the speed of real time insights while also giving you:
- a single, unified tool for a wide range of both batch and streaming processing operations,
- friendly Python and SQL APIs to facilitate adoption across organizations.
The 2023 benchmarks show that the Pathway Live Data Framework is able to handle a wider range of operations than any of the other solutions. Not only is the framework able to execute these types of operations, but it outperforms the competitors in most cases. This combination of speed and versatility is due to core design principles in the engine.
Unified Engine
The Pathway Live Data Framework is able to unify batch and streaming code by separating the transformation logic from the data updates through reactive design. This is comparable to how a simple spreadsheet works. You enter a formula that defines the relationship between two cells. Whenever you change the input data, the spreadsheet will react automatically and transform this new data for you. This means that you can describe your logic as you would in batch mode, and the framework will handle dealing with the streaming data updates for you.

Friendly Python and SQL APIs
The Pathway Live Data Framework is built in Rust and offers familiar Python and SQL APIs for ease of use. The Python API is built around Table objects, similar to a Spark RDD or pandas DataFrame. Tables can be created from static or streaming data sources. The framework offers built-in operations to manipulate the Tables as well as the possibility to define your own custom transformations. Below is a simple example of the Python API syntax which reads an incoming stream of CSV data, performs a reduction on the data and then outputs it to a stream of CSV data.
# sample Pathway workload using the Python API
import pathway as pw
t = pw.io.csv.read('./sum_input_data/',
["value"],
types={"value": pw.Type.INT},
mode="streaming"
)
t = t.reduce(sum=pw.reducers.sum(t.value))
pw.io.csv.write(t, "output_stream.csv")
pw.run()
The SQL API enables developers and data analysts to leverage their existing SQL knowledge and transition these skill sets smoothly into a real-time streaming scenario. Using the pw.sql() syntax, users can run SQL queries on data stored in Pathway Tables. Below is an example:
# sample Pathway workload using the SQL syntax
import pathway as pw
t = pw.debug.table_from_markdown(
"""
| a | b
1 | 1 | 2
2 | 4 | 3
3 | 4 | 7
"""
)
ret = pw.sql("SELECT * FROM tab WHERE a<b", tab=t)
pw.debug.compute_and_print(ret)
Install Pathway with pip to get started. Or check out one of our more advanced tutorials, for example about running online linear regression with Kafka or performing a window join on a live data stream.
Fast. Flexible. Friendly.
To sum it all up, the 2023 benchmarks indicate that:
- The Pathway Live Data Framework is fast: The engine matches or outperforms all the benchmarked engines on both simple and complex tasks in both batch and streaming scenarios.
- The Pathway Live Data Framework is flexible: It makes it easy to switch from batch to stream processing. It’s a matter of adding pw.run() at the end of your script. That’s it.
- The Pathway Live Data Framework is friendly: It offers familiar Python and SQL APIs to facilitate onboarding and adoption.
If you have questions about the benchmarks or would like to discuss using Pathway for your specific use case, come say hello on Discord – our team of streaming experts is there to support you!

Pathway Team
 Zuzanna Stamirowska
Zuzanna Stamirowska blog · open betaDec 5, 2022Pathway Live Data Framework is now in Open Beta
blog · open betaDec 5, 2022Pathway Live Data Framework is now in Open Beta Olivier Ruas
Olivier Ruas blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework
blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework Shlok Srivastava
Shlok Srivastava blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework
blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework