Building LLM enterprise search APIs

 Anup Surendran
Anup SurendranBuilding LLM enterprise search APIs
Offering robust and relevant search is critical for many enterprise applications today. Users expect Google-like experiences that understand intent and context. Achieving this requires a combination of natural language processing, high-performance search across different silos, and a scalable architecture.
Fortunately, by leveraging large language models (LLMs), vector search, and API gateways, developers can now build intelligent semantic search APIs easier than ever before.
LLM Search Architecture for APIs
Here is an example architectural sequence diagram which includes different components of a search pipeline which enables a user search for realtime product price lookups
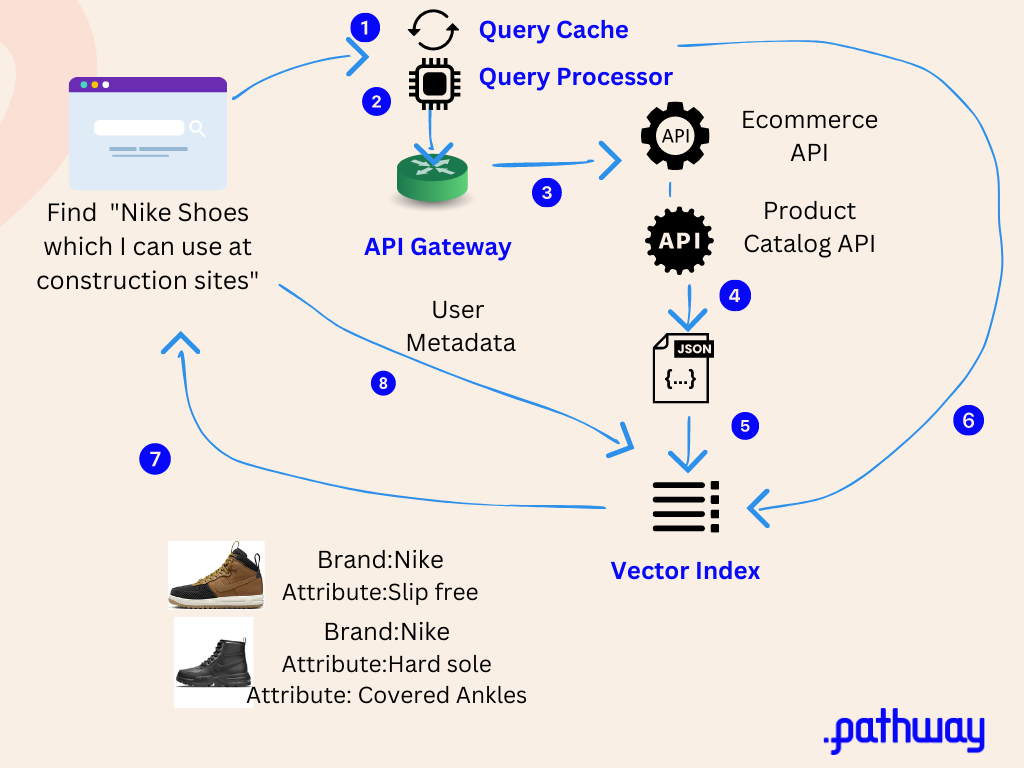
Let’s dig a little deeper into the different components here:
1) Query Cache
For repeated queries, the Query Cache performs deduplication and returns responses from memory. With similar requests, it can perform an approximate smart-dedupe and handle synonyms. As a result, the user queries' embedding workload is reduced.
2) Query Processor
The query processor parses incoming user queries and searches the vector index to find best matching api queries.
The query processor can essentially help the api gateway by doing the following:
- Analyzing request parameters, payload, and headers for intent and context clues.
- Ranking api queries based on previous usage patterns.
Some way the query processor can know which APIs to map to are by talking to API discovery or scanning existing api log files. If these are not possible then manually configuring api information for the first time is an option.
Once the API queries are identified, then this information is passed to the API Gateway.
3) API gateway
A key responsibility of the API gateway is mapping incoming requests to appropriate backend services. As the number of microservices grows, locating the correct service endpoint gets increasingly challenging. Once the user query translation to a possible list of api queries is done by the query cache, then the API gateway can do the API service matching.
The combination of large language models and caching provides a scalable, resilient, and intelligent way to handle request mapping across services. The LLM understands semantics to translate user queries into API queries properly, while caching boosts efficiency and performance.
This gateway also provides the other important capabilities to connect to different siled microservices across the enterprise. The gateway handles cross-cutting infrastructure concerns, so search services can focus on the domain logic.
- Load Balancing - Distribute requests across available instances.
- Caching - Cache common queries and results.
- Rate Limiting - Prevent overload from spike traffic.
- Observability - Performance monitoring, logging, and tracing.
- API Keys - Manage and authenticate access.
4) JSON List
In this example, every relevant API service will return a JSON based on the api requests. These are most likely different formats with different values
5) JSON Translation and Combiner
A translation service will convert this into a vector friendly JSON so that you don’t have to unnecessarily embed elements which are not going to be used by the search engine. The translation function also builds up your master search results model. You may need to sort, filter, paginate, or further process the aggregated data before passing it on. The key is hiding this complexity behind the combiner function.
6) User query embedding
If the query cache can’t find a similar user query in the cache then the corresponding embedding model will be used to embed the user query into the vector index. Then user query is then also stored in the cache for the future.
7) Search friendly response
Depending on what the application needs, a lightweight semantic search response is provided. In this example, anything which can help the user decide on whether the product is useful for them ideally should be part of the response itself e.g thumbnails of the product, price, attributes of the product, discounts, when it was last added to the inventory, how many items left in the inventory, user review aggregates etc.
8) User profile metadata
User profile data such as demographics, interests, and past search behavior can be highly valuable for improving vector search relevancy. By ingesting user attributes into an embedding model, we can learn dense vector representations that capture similarities between users. These user vectors can then be used during query time to rerank results in a way that personalizes them to the individual.
For example, if we know a user is interested in photography, we can boost results for "camera" that are about DSLRs over point-and-shoots. Or for a teenage user we can rank results for "music" higher that are relevant to current pop artists.
User vector similarity can also connect users with similar tastes, so we can leverage the search behavior of one user to refine results for similar users. Overall, user profile data allows us to transform generic vector search into intelligent personalized search that better serves each user's unique interests and needs. With thoughtful search modeling, personalization can greatly improve search accuracy and user satisfaction
Capabilities the Pathway Live Data Framework provides:
Within the architecture diagram the Pathway Live Data Framework can provide the following capabilities
- Query Cache (1)
- Query Processor (2)
- JSON translation (4)
- Vector Index (supporting interactions 5,6,7,8)
Example showcase without API Gateway
Here is a lightweight showcase with realtime api search with LLM
Conclusion
LLMs and Vector indexes in this example have been used in the following capabilities:
- User query caching
- Query processing with smart lookups for API query mapping
- User query embedding
- JSON translation
- Realtime product and price search with personalization
By combining innovations in LLM, Vector Indexes and caching, developers now have the tools to build production-grade semantic search experiences. LLMs bring natural language understanding, vector indexes enable blazing search speed at scale, and API gateways tie it all together into powerful search APIs. The future of search is full of potential, and leveraging these technologies unlocks new possibilities for any developer building search-enabled applications.





