Data Discovery to Data Pipeline Process

 Shlok Srivastava
Shlok SrivastavaEver feel like you’re swimming in spreadsheets, logs, or databases without a clear path forward? You’re not alone. In today’s business landscape, simply possessing large amounts of data doesn’t cut it. What truly matters is how well you uncover hidden gems in that data and channel them into actionable insights. This article demystifies the journey from spotting the right datasets (data discovery) to building efficient, repeatable pipelines that deliver dependable analytics to the right people at the right time.
Whether you’re new to the world of data and just dipping your toes into metadata, or a seasoned data pro refining your workflow with advanced streaming tools, the following pages will provide both foundational context and deeper technical details. Get ready to transform raw numbers and logs into clear, meaningful reports, dashboards, and real-time decisions that propel your organization forward.
Introduction to Data Discovery
Before building automated pipelines that move data seamlessly from source to destination, it’s crucial to understand what data is available and how it might be used. This initial phase, known as data discovery, sets the stage for every subsequent step in your data journey.
Data discovery is the process of identifying and understanding datasets that are relevant to a particular goal, question, or business requirement. This step precedes more advanced stages of data processing, such as building pipelines or running machine learning models. Data discovery helps you figure out what data you have, where it is located, and how it can be used to generate insights.
For absolute beginners, data discovery often involves:
- Performing exploratory data analysis (EDA) to understand data characteristics, such as distribution, outliers, or missing values.
- Creating visualizations (charts, graphs, dashboards) to highlight trends or anomalies.
- Documenting metadata: data sources, data types, and the relationships among different datasets.
For more experienced practitioners, data discovery is a continued effort of:
- Automating data profiling using specialized tools or scripts.
- Integrating metadata management across a variety of systems.
- Employing advanced algorithms to detect data drift, correlation, and hidden patterns.
Regardless of your level of expertise, data discovery lays the groundwork for your entire data strategy. By establishing clarity about the datasets you have, you can better define objectives, plan transformations, and ensure quality checks that will be integral to a robust data pipeline.
After completing a thorough data discovery process, you’ll be better equipped to decide how your data might feed into downstream processes—particularly data pipelines.
2. Why Data Discovery Matters
Now that you’ve laid out the basics of data discovery, let’s discuss its significance. Ensuring that you have a clear understanding of your data’s origins, structure, and quality is key to driving tangible results.
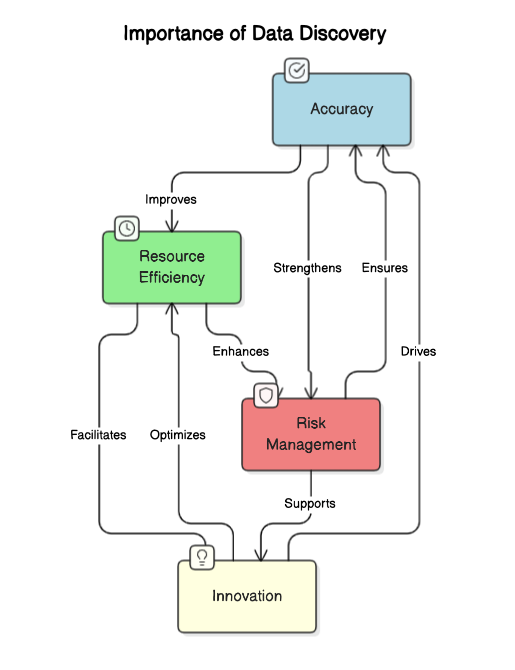
Below are four major reasons why data discovery is a critical phase:
- Accuracy
Incomplete, duplicated, or inconsistent data can lead to flawed analyses. Through effective data discovery, you ensure the data you rely on truly reflects the underlying realities of the business or domain. - Resource Efficiency
Knowing what data you have (and where it resides) helps you avoid the inefficiency of repeated data collection. You can allocate computing and storage resources more effectively, ensuring that you do not waste time or money. - Risk Management
As data privacy and compliance regulations become more stringent (GDPR, HIPAA, etc.), data discovery helps you pinpoint where sensitive data resides. By identifying all relevant datasets upfront, you reduce the risk of regulatory breaches. - Innovation
Sometimes, the best ideas emerge from unexpected data combinations. Data discovery encourages exploration, leading to novel insights that can differentiate your business offerings from competitors.
3. Key Steps in Data Discovery
Having established the importance of data discovery, it’s time to look at the practical steps involved. Each step helps you build a clearer picture of your data ecosystem and its potential value.
While data discovery can span multiple organizational roles (data analysts, engineers, scientists), the following steps are common to a successful discovery process:
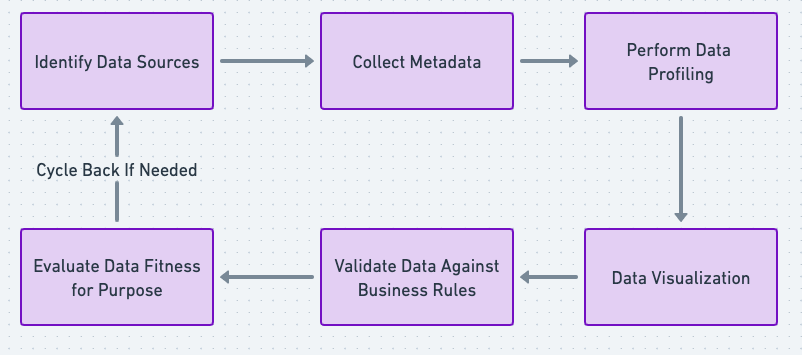
- Identify Data Sources
Catalog all potential data sources: databases, data lakes, SaaS platforms, logs, or even spreadsheets. The more systematically you can achieve this, the better. Some organizations use data catalogs or specialized governance tools to maintain this list. - Collect Metadata
Document the data’s schema, lineage, and format. Metadata is essential for both technical and business stakeholders, providing clarity on data definitions, transformations, and usage constraints. - Perform Data Profiling
Conduct basic statistical analysis to measure data quality. Identify missing values, outliers, or anomalies. For advanced users, machine learning techniques like clustering can reveal hidden segments in the data. - Data Visualization
Tools like Tableau, Power BI, or Python libraries (matplotlib, seaborn) help you visualize relationships and trends in your data. Visual analysis can be far more intuitive, particularly for stakeholders who prefer graphical insights over raw numbers. - Validate Data Against Business Rules
Confirm that the discovered datasets align with domain knowledge. For instance, if you’re dealing with sales data, cross-check figures with known revenue targets to ensure data integrity. - Evaluate Data Fitness for Purpose
Is the data suitable for the intended objective? Some data might be complete but stale. Other data could be timely but too sparse for a detailed analysis. Balancing these criteria is essential to deciding if the data is “good enough” for downstream processes.
Upon completing these steps, you’ll have a well-documented understanding of your datasets, their structure, and their potential for fueling valuable analytics. The next phase in your data journey is to transform these insights into a repeatable, automated process: the data pipeline.
4. From Discovery to Data Pipeline
Once you’ve identified high-quality data and gained initial insights, the next question becomes: “How do we continuously move and refine this data for ongoing analysis?” Enter the data pipeline a sequence of data processing steps that captures, transforms, and stores data.
A data pipeline is a series of data processing steps that systematically move data from source to destination, often culminating in storage systems, analytics platforms, or machine learning applications. If data discovery is about answering “What data do we have and how can we use it?”, then building a pipeline answers “How can we automate the flow of this data from collection to utilization?”

- Data Ingestion: Gathering raw data from diverse sources.
- Data Processing: Cleaning, validating, transforming, and enriching data.
- Data Storage: Storing processed data in data lakes, warehouses, or specialized databases.
- Data Analysis: Using the data for BI dashboards, ML models, or real-time insights.
The entire journey is cyclical. As more data is generated or new use cases arise, you revisit data discovery to find new sources or reevaluate existing data sets. A well-designed data pipeline is flexible enough to incorporate changes quickly, ensuring that your organization remains agile and responsive to evolving data requirements.
Next, you’ll explore the core components of a data pipeline, giving you a high-level view of how each piece fits into the broader architecture.
5. Core Components of a Data Pipeline
At a high level, a data pipeline typically comprises the following components:
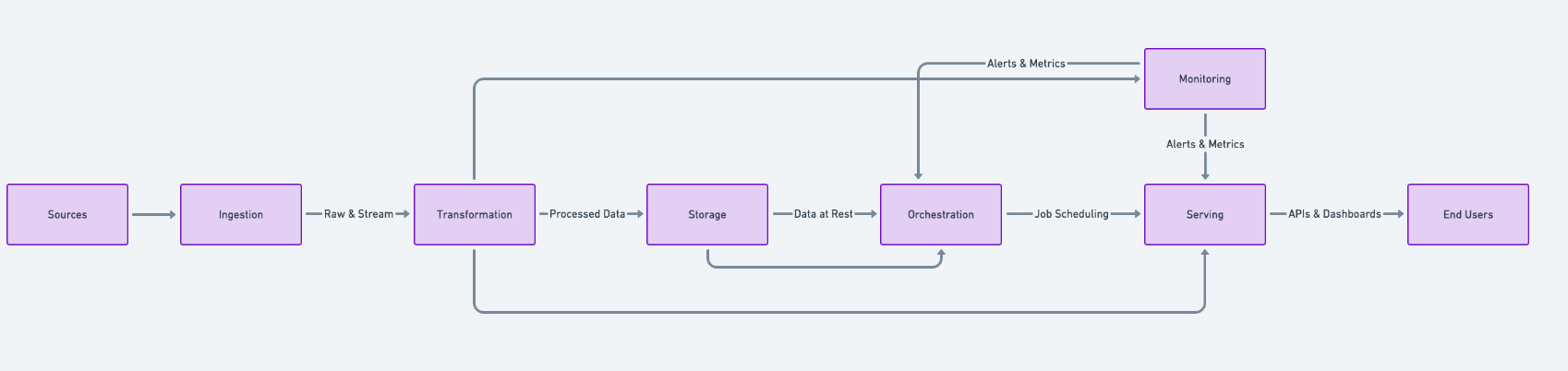
- Data Sources
- Structured: Relational databases (e.g., MySQL, PostgreSQL), data warehouses.
- Unstructured: Emails, text files, social media feeds, logs.
- Semi-Structured: JSON, XML, CSV exports from various systems.
- Ingestion Layer
- Tools like Apache Kafka, AWS Kinesis, or managed solutions that capture data in real-time or batch mode.
- Connectors for extracting data from SaaS platforms (Salesforce, Marketo), logs, or IoT devices.
- Transformation Layer
- Data cleansing, deduplication, normalization, aggregation, and enrichment.
- Libraries and frameworks like Apache Spark, Pathway, dbt, Python (pandas), or visual ETL tools such as Informatica or Talend.
- Storage Layer
- Data Lake: Designed for storing raw or semi-structured data. Examples: Amazon S3, Azure Data Lake.
- Data Warehouse: Optimized for analytics with structured schemas (Snowflake, Redshift, BigQuery).
- NoSQL Databases: For unstructured or flexible schema data (MongoDB, Cassandra).
- Orchestration and Scheduling
- Tools like Apache Airflow, Luigi, or cloud services like AWS Step Functions that coordinate complex workflows.
- Ensures tasks execute in the correct sequence with defined dependencies and error-handling strategies.
- Monitoring and Alerting
- Observability platforms (Datadog, Prometheus, Grafana) that track pipeline performance and resource usage.
- Automated alerts when data quality checks fail or pipeline stages encounter errors.
- Data Serving Layer
- BI tools (Tableau, Power BI, Looker) for dashboard and reporting.
- Machine learning or data science platforms (SageMaker, DataRobot, Vertex AI) for advanced predictive analytics.
This modular view helps you understand how data moves from one phase to another. It also enables you to pinpoint where advanced optimizations or business logic might be best applied.
6. Tools and Technologies in Modern Data Pipelines
With the key components of a pipeline in mind, it’s helpful to explore the specific technologies that make these components work. The modern data landscape is vast, offering numerous open-source and commercial products.
The data ecosystem is vast and constantly evolving. Choosing the right tools depends on your data volume, business requirements, and team expertise. Below is a non-exhaustive list of popular tools and their primary use cases:
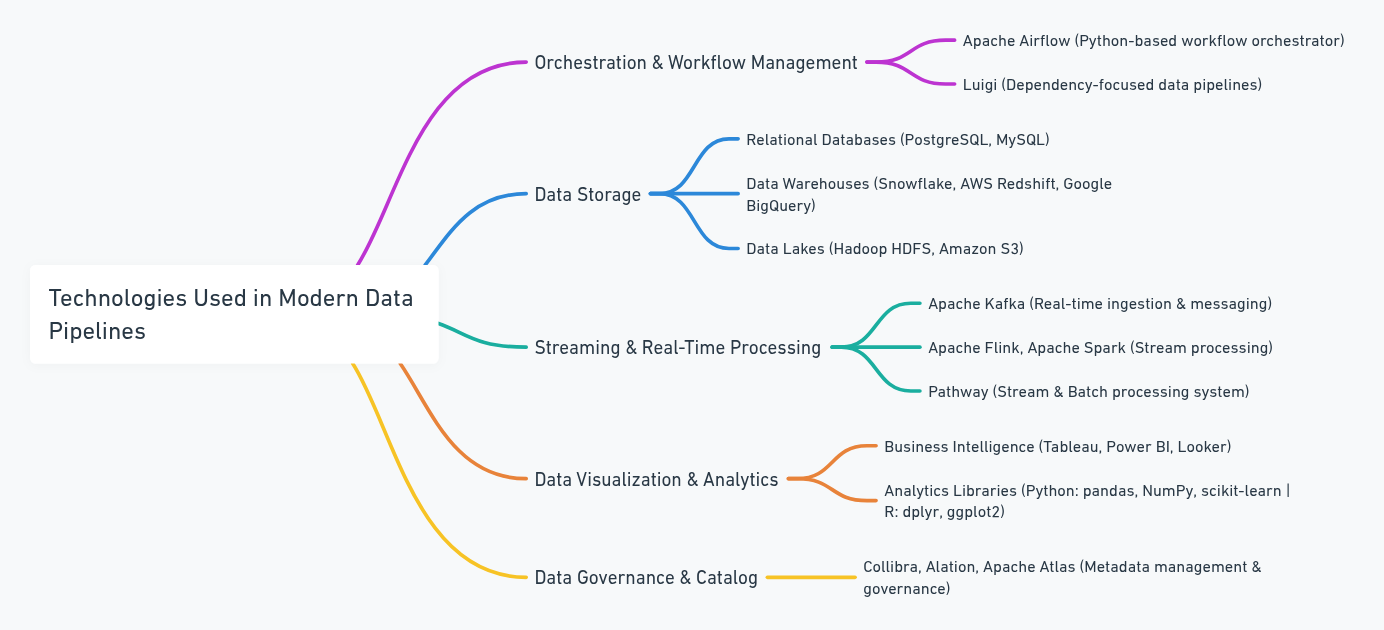
- Orchestration and Workflow Management
- Apache Airflow: A highly flexible, Python-based workflow orchestrator for scheduling tasks.
- Luigi: A similar Python package for building data pipelines with a focus on dependency management.
- Data Storage
- Relational Databases: PostgreSQL, MySQL for structured data in OLTP systems.
- Data Warehouses: Snowflake, AWS Redshift, Google BigQuery for large-scale analytics.
- Data Lakes: Hadoop HDFS or cloud-based object storage (Amazon S3) for raw data.
- Streaming and Real-Time
- Apache Kafka: Real-time data ingestion, streaming, and messaging.
- Apache Flink and Apache Spark: Stream and batch processing engines with powerful data transformation libraries.
- Pathway: A streaming database system that can handle stateful data processing and real-time data transformations (more on this later).
- Data Visualization and Analytics
- Business Intelligence: Tableau, Power BI, Looker for creating dashboards and visualizing KPIs.
- Analytics Libraries: Python (pandas, NumPy, scikit-learn), R (dplyr, ggplot2) for data science tasks.
- Data Governance and Catalog
- Collibra, Alation, Apache Atlas: Tools to manage data metadata, define data lineage, and maintain data governance policies.
For beginners, picking a user-friendly, cloud-based platform can simplify setup, reduce maintenance overhead, and let you focus on learning the basics. Advanced users often combine multiple open-source tools for maximum flexibility and control. Regardless of your toolset, adopt a modular approach that separates ingestion, transformation, storage, and analytics.
7. Best Practices for Designing and Managing Data Pipelines
Here are some guiding principles to keep your pipelines maintainable and efficient:
- Start Small, Then Scale
Especially for beginners, don’t try to build an enterprise-grade system overnight. Build a minimal pipeline, automate it, and improve as your data needs grow. - Data Quality Checks
Implement validations, deduplication, and anomaly detection as early as possible in the pipeline. If you ignore quality checks until the final step, you risk propagating errors downstream. - Metadata-Driven Approach
Store and leverage metadata to automate transformations and ensure consistent definitions. This approach is invaluable for advanced data governance and lineage tracking. - Automation and Orchestration
Use workflow tools like Airflow or Luigi to schedule jobs and manage dependencies. Automate all repeated tasks—from data extraction to final reporting—to minimize manual intervention. - Security and Compliance
Encrypt data in transit and at rest, implement strong access control (role-based access, multi-factor authentication), and regularly audit logs for suspicious behavior. - Version Control
Keep your pipeline scripts, configurations, and even your data schemas in a version control system like Git. This ensures reproducibility and a clear history of changes. - Monitoring and Observability
Track key metrics: pipeline run times, latency, throughput, error rates. Dashboards and alerts help you troubleshoot issues proactively. - Documentation and Knowledge Sharing
Maintain clear documentation to help new team members and stakeholders understand the pipeline’s functionality and logic. This is particularly important as pipelines grow in complexity.
8. Advanced Topics and Challenges
Moving from intermediate to advanced data engineering involves addressing more complex challenges. Below are some scenarios that seasoned data professionals often encounter:
- Data Lineage and Impact Analysis As pipelines become more elaborate, understanding precisely how data flows, transforms, and merges is crucial. Tools like Apache Atlas, Collibra, or custom solutions can track lineage and allow for sophisticated impact analyses (e.g., “Which reports will break if this column changes?”).
- Real-Time vs. Batch Pipelines While batch processing remains a staple for many analytical workloads, real-time streaming is essential for use cases like fraud detection, IoT analytics, and dynamic pricing. Solutions like Kafka, Flink, and Pathway enable stream processing with sub-second latencies.
- Microservices and Distributed Systems Large-scale pipelines often involve many microservices, each handling a piece of the puzzle. Designing these systems involves trade-offs around consistency, latency, fault tolerance, and cost.
- Machine Learning Integration Advanced analytics can require model serving, feature stores, and continuous model retraining. Tools like MLflow, Kubeflow, and AWS Sagemaker orchestrate these workflows.
- Data Governance and Privacy Regulations With increased regulatory scrutiny, advanced data governance ensures compliance and trust. This might include implementing processes for data anonymization, retention policies, and strict data access controls.
- Cost Optimization Scaling your pipeline can get expensive. Balancing data freshness, pipeline complexity, and cloud infrastructure costs is a continuous challenge.
Addressing these complexities effectively often depends on choosing the right technologies. In the next section, it’s highlighted how Pathway specifically supports real-time data processing, bridging the gap between discovery-driven insights and actionable analytics.
9. How Pathway Fits into the Journey
Pathway is a high-performance streaming database built to handle large volumes of real-time data. Its strengths include:
- Stateful Data Processing: Unlike traditional event streaming tools, Pathway maintains state, allowing complex transformations to be computed in real time.
- Scalable Architecture: Suitable for both small projects and large-scale enterprise applications, thanks to its distributed design and efficient resource usage.
- Easy-to-Use API: Pathway provides user-friendly APIs (in Python or Rust) that allow developers to define complex dataflow computations without excessive boilerplate.
- Advanced Streaming Capabilities: Ideal for scenarios where real-time insights or immediate data transformation is critical, such as fraud detection or real-time analytics dashboards.

By incorporating Pathway into your pipeline stack, you gain an engine specifically optimized for real-time data transformations, bridging the gap between data discovery (where you learn about the data’s structure and potential) and advanced analytics (where you apply transformations on streaming or fast-moving data).
Here’s a quick high-level overview of how Pathway might fit in:
- Data Ingestion: Data flows from sources like Kafka or IoT devices into Pathway.
- Real-Time Transformation: Pathway aggregates, enriches, and cleans data on the fly.
- Downstream Distribution: Pathway continuously updates data in storage layers or triggers alerts in analytics systems, ensuring you have an always up-to-date view of your data.
This tight loop between discovery and action means you can iterate and deploy new data insights much faster than with a purely batch-driven architecture.
10. Conclusion
The path from data discovery to an automated, production-ready data pipeline is both rewarding and filled with potential challenges.
- Data discovery sets the foundation by clarifying what data is available and whether it meets your business needs.
- Building a pipeline automates the flow of that data from ingestion to final analysis, ensuring the right people and applications have the right data at the right time.
However, success doesn’t end at the initial deployment. Maintaining a robust pipeline involves:
- Continuous monitoring of data quality.
- Keeping documentation updated.
- Ensuring security and compliance measures evolve with regulatory changes.
- Regularly revisiting your data strategy to incorporate new sources or tools.
For real-time needs, platforms like Pathway offer specialized capabilities that can bring fresh insights to life as soon as data is generated. Whether you’re a beginner mapping out your first pipeline or an experienced data engineer scaling complex architectures, embracing best practices—alongside the right tools—can elevate your data operations to new heights.






