Scalable Alternative to Apache Kafka and Flink for Advanced Streaming: Build Real-Time Systems with NATS and Pathway

 Shlok Srivastava
Shlok SrivastavaBuild Real-Time Systems with NATS and Pathway: Scalable Alternative to Apache Kafka and Flink for Advanced Streaming
Real-time data processing is crucial for businesses to make swift, informed decisions. Whether it's monitoring IoT devices, analyzing financial transactions, or providing instant user feedback, real-time systems form the backbone of modern applications.
In this blog post, you’ll learn how to build robust real-time systems without using Kafka or Flink.
You’ll be using NATS, a high-performance messaging system, and Pathway Live Data Framework, a powerful batch and stream processing framework. Building such systems can be complex, but powerful tools like NATS and Pathway Live Data Framework are making it easier than ever. This blog introduces these technologies which are well-adopted alternatives to Apache Kafka and Apache Flink respectively. This blog also provides practical code examples, and walks through a use case of Real Time Fleet Monitoring and Predictive Maintenance.
Why Consider Alternatives to Apache Kafka and a Flink Alternative?
As your distributed systems grow, you may find yourself looking for alternatives of Apache Kafka or alternatives of Flink. These platforms, while powerful, introduce unnecessary complexity, inconsistent performance, and steep costs—up to $20,000 per month for minimal Kafka deployments, plus thousands more for managed services like Confluent Cloud. In contrast, a streaming pipeline using NATS and Pathway can address several of these issues.
NATS: A Simpler, More Efficient Alternative to Apache Kafka
- NATS is an open-source, lightweight messaging system designed for cloud-native applications, IoT messaging, and microservices architectures.
- It provides a simple yet powerful publish/subscribe model for asynchronous communication between distributed systems.
- As an alternative to Apache Kafka, NATS delivers lower overhead and simpler operations while maintaining high throughput and resilience.
Pathway Live Data Framework: the Leading Flink Alternative for Advanced Real-Time Analytics
- Pathway Live Data Framework is an advanced stream-processing framework tailored for real-time data analytics.
- It simplifies building data pipelines for ingesting, processing, and analyzing data streams, allowing developers to focus on business logic rather than infrastructure.
- For teams seeking a Flink alternative, Pathway Live Data Framework is not only easier to learn and use, but also supports real-time machine learning, dynamic graph algorithms, and advanced data transformations—features that make it a more powerful option than traditional Flink implementations.
- If you’re evaluating alternatives to Apache Kafka for high-performance messaging, or seeking a Flink alternative to handle advanced streaming analytics, this guide will show you how NATS and Pathway Live Data Framework fit the bill
Basic Terminologies
Before diving deeper into the implementation, here’s a quick glossary of terms and concepts used in this tutorial. If you're already familiar with message brokers, feel free to skip this section and proceed to "Getting Started with NATS". Most of these terms are also briefly explained where needed as you follow through this tutorial.
- Publisher: In a pub/sub system, the component responsible for sending (or publishing) messages to a particular subject.
- Subscriber: The component that listens to (or subscribes to) messages from a particular subject. It acts upon the messages it receives in real time.
- Subject: In NATS, a lightweight mechanism to categorize messages. Publishers send messages to subjects, and subscribers receive messages by subscribing to specific subjects.
- Telemetry Data: Sensor data collected from IoT devices or systems. For instance, in the fleet monitoring example, telemetry data includes vehicle location, engine temperature, and fuel levels.
- Anomaly Detection: The process of identifying unusual patterns or critical conditions in data that deviate from normal behavior. For example, detecting high engine temperatures or low fuel levels in vehicle telemetry.
- Message Broker: A system or tool like NATS that facilitates message exchange between publishers and subscribers. It ensures reliable communication in distributed systems.
- Schema: A defined structure for data. For example, a schema in Pathway specifies the fields and data types expected in telemetry data.
- JSON (JavaScript Object Notation): A lightweight, text-based format for structuring data. It is commonly used for sending and receiving structured data in APIs and messaging systems.
- AsyncIO: A Python library that supports asynchronous programming. It enables efficient handling of I/O-bound and high-level structured network code, such as the publisher and subscriber implementations.
- Alerting System: A system or process that notifies stakeholders about critical conditions or anomalies. In this tutorial, alerts are generated for anomalies in telemetry data and logged in real time.
- Real-Time Processing: The ability to process data as it arrives, enabling immediate analysis and response. Systems like NATS and Pathway are optimized for real-time data handling.
- Connector: A mechanism to integrate different systems. For example, the framework’s NATS connectors allow seamless communication between NATS and Pathway Live Data Framework for real-time data ingestion and processing.
Getting Started with NATS
Installing NATS
Since this tutorial uses NATS, you need to install it first. The easiest way to run it locally is via Docker. Use the command below to start it:
docker run -p 4222:4222 nats:latest
This command pulls and runs the latest NATS Docker image, exposing the default port 4222.
There are multiple other ways to install and run NATS. Especially on a production server, this might not be the most efficient way to install and run NATS. For multiple other ways to get started with NATS, you can refer to the official NATS documentation here: https://docs.nats.io/running-a-nats-service/introduction/installation
Installing the NATS Python Client
Having the NATS server up and running, you can now proceed using it for messaging. To interact with NATS using Python, you can make use of the nats-py library. It provides a simple interface for connecting and communicating with a NATS server. Install it using pip:
pip install nats-py
Creating a Publisher
Now that the NATS server is running and the NATS client is also installed, you can follow the steps below to create a simple publisher - a program sending messages to a NATS subject.
- Import the necessary modules:
You need asyncio for asynchronous programming and nats to interact with the NATS server.
import asyncio
import nats
- Define an asynchronous function to publish a message:
This function handles the publishing process.
async def publish_message():
- Connect to the NATS server:
You can use nats.connect() to establish a connection to the NATS server running locally. The connection string "nats://localhost:4222" specifies the server's address and port.
nc = await nats.connect("nats://localhost:4222")
- Publish a message to a subject:
nc.publish("updates", b"Hello, NATS!") sends the message "Hello, NATS!" to the subject updates. The message is prefixed with b to indicate that it's a byte string, which is required by NATS.
await nc.publish("updates", b"Hello, NATS!")
print("Message sent: Hello, NATS!")
- Close the connection:
await nc.close()
- Run the asynchronous function:
asyncio.run(publish_message())
This starts the event loop and runs the publish_message() function.
Complete Publisher Code (publisher.py):
import asyncio
import nats
async def publish_message():
# Connect to the NATS server
nc = await nats.connect("nats://localhost:4222")
# Publish a message to the 'updates' subject
await nc.publish("updates", b"Hello, NATS!")
print("Message sent: Hello, NATS!")
# Close the connection
await nc.close()
# Run the asynchronous function
asyncio.run(publish_message())
Creating a Subscriber
After writing code for the publisher, you now need to write a subscriber that listens for messages on the same subject and handles them as they arrive.
Follow the below instructions to create a subscriber script:
- Import the necessary modules:
import asyncio
import nats
import argparse
- Define an asynchronous function to subscribe to messages:
async def subscribe_messages(subject):
- Connect to the NATS server:
nc = await nats.connect("nats://localhost:4222")
- Define a message handler function:
async def message_handler(msg):
print(f"Received a message on '{msg.subject}': {msg.data.decode()}")
This function is called whenever a message is received on the subscribed subject. msg.subject contains the subject of the message. msg.data contains the message data in bytes, so you decode it to a string.
- Subscribe to the subject passed as a parameter:
await nc.subscribe(subject, cb=message_handler)
print(f"Subscribed to '{subject}' subject.")
nc.subscribe() subscribes to the specified subject and assigns the message handler. The callback message_handler is called whenever a message is received.
- Keep the subscriber running indefinitely:
while True:
await asyncio.sleep(1)
This infinite loop ensures that the subscriber keeps running to listen for incoming messages.
- Set Up Argument Parser:
if __name__ == "__main__":
# Set up argument parser
parser = argparse.ArgumentParser(description='NATS Subscriber')
parser.add_argument('--subject', type=str, required=True, help='NATS subject to subscribe to')
args = parser.parse_args()
subject = args.subject
Define a --subject flag that must be provided while running the script.
- Run the asynchronous function:
asyncio.run(subscribe_messages(subject))
Complete Subscriber Code (subscriber.py):
import asyncio
import nats
import argparse
async def subscribe_messages(subject):
# Connect to the NATS server
nc = await nats.connect("nats://localhost:4222")
# Define a message handler to process incoming messages
async def message_handler(msg):
print(f"Received a message on '{msg.subject}': {msg.data.decode()}")
# Subscribe to the subject provided
await nc.subscribe(subject, cb=message_handler)
print(f"Subscribed to '{subject}' subject.")
# Keep the subscriber running indefinitely
while True:
await asyncio.sleep(1)
if __name__ == "__main__":
# Set up argument parser
parser = argparse.ArgumentParser(description='NATS Subscriber')
parser.add_argument('--subject', type=str, required=True, help='NATS subject to subscribe to')
args = parser.parse_args()
subject = args.subject
# Run the asynchronous function
asyncio.run(subscribe_messages(subject))
Testing the Setup
It's crucial to run the subscriber before the publisher. NATS does not buffer messages by default; it delivers messages to subscribers who are actively listening at the time of publishing. If you run the publisher first, the message won’t be sent anywhere because no subscribers are listening yet.
Having that given, you can run the pipeline using these two simple steps:
- Run the subscriber script first:
python subscriber.py —-subject updates
- Then, in another terminal, you can run the publisher script:
python publisher.py
Expected Output on Subscriber Terminal:
Subscribed to 'updates' subject.
Received a message on 'updates': Hello, NATS!
The subscriber listens to the updates subject.
When the publisher sends a message, the subscriber immediately receives and prints it.
Getting Started with Pathway Live Data Framework
Installing the Pathway Live Data Framework
Install the framework using pip by running the following command:
pip install pathway
Connecting Pathway Live Data Framework with NATS
The Pathway Live Data Framework has recently introduced connectors for NATS, enabling seamless integration between the two systems. This allows for efficient ingestion and processing of real-time data streams from NATS within the framework.
Supported NATS Parameters and Formats:
When using the framework's NATS connectors, you can specify various parameters. Below are some of the parameters that are used in the code below:
- uri: The URI of the NATS server (e.g.,
"nats://127.0.0.1:4222"). - subject: The NATS subject to subscribe messages from.
- format: The format of the messages. Supported formats include:
"plaintext": Messages are expected to be plain text strings and decoded from UTF-8. Useful for simple string messages."json": Messages are JSON-formatted strings, which will be parsed into structured data. Requires specifying a schema."raw": Messages are treated as raw bytes without any decoding.
Additional Parameters:
- schema: Used only when
format="json". Defines the structure of the data to map JSON fields to table columns. - autocommit_duration_ms: The maximum time between two commits. Every autocommit_duration_ms milliseconds, the updates received by the connector are committed and pushed into Pathway's dataflow.
- json_field_paths: Allows mapping field names to paths within the JSON structure when using
format="json".
For a detailed list of all the supported parameters and examples, you can head to the Pathway documentation on NATS connectors: https://pathway.com/developers/api-docs/pathway-io/nats
Reading/Writing NATS Messages with Pathway
Here's how you can read messages from a NATS subject, process them using Pathway, and write the processed messages back to another NATS subject:
- Import Pathway:
import pathway as pw
- Read messages from NATS using 'plaintext' format:
message_table = pw.io.nats.read(
uri="nats://127.0.0.1:4222",
topic="updates",
format="plaintext"
)
Use pw.io.nats.read() to subscribe to the updates subject. The format="plaintext" indicates that messages are plain text and decoded from UTF-8. The messages are stored in the data column of message_table.
- Process the messages:
processed_messages = message_table.select(
message=pw.this.data
)
Create a new table processed_messages by selecting a new column message with the original message intact.
- Output processed messages to another subject using 'plaintext' format:
pw.io.nats.write(
processed_messages,
uri="nats://127.0.0.1:4222",
topic="processed.updates",
format="plaintext",
value=processed_messages.message
)
Use pw.io.nats.write() to publish messages to the processed.updates subject. format="plaintext" specifies that the messages are plain text. value=processed_messages.message indicates which column to use as the message payload.
- Run the Pathway pipeline:
pw.run()
This starts the Pathway computation graph.
Complete Pathway Code (pathway_processor.py):
import pathway as pw
# Read messages from NATS
message_table = pw.io.nats.read(
uri="nats://127.0.0.1:4222",
topic="updates",
format="plaintext"
)
# Process the messages as you wish
processed_messages = message_table.select(
message=pw.this.data
)
# Output processed messages to another subject
pw.io.nats.write(
processed_messages,
uri="nats://127.0.0.1:4222",
topic="processed.updates",
format="json"
)
pw.run()
To demonstrate the data flow, this time you have to run the subscriber with processed.updates subject.
Running the Pathway Script
- Start the Pathway processor script that listens to the messages on the subject “updates “ and forwards them to the subject “processed.updates”:
python pathway_processor.py
- Run the subscriber script that listens to the messages produced by the Pathway script run in the previous step. Since it forwards messages to the subject “processed.updates”, this subject will be listened to by the script:
python subscriber.py --subject processed.updates
- Run the publisher script to produce messages to the subject “updates”. These messages will be picked up by Pathway script ran in the step 1 and then will be forwarded to the subject “processed.updates” that is listened by a subscriber script from the step 2:
python publisher.py
Expected Output on Subscriber Terminal:
Subscribed to 'processed.updates' subject.
Received a processed message on 'processed.updates': Hello, NATS!
Real Time Fleet Monitoring use case with Kafka and Flink Alternatives: NATS and Pathway Live Data Framework
Problem Statement
Suppose you work at a logistics company that operates a fleet of vehicles equipped with sensors that send telemetry data such as location, engine temperature, fuel level, and brake health. You need to monitor these vehicles in real-time to optimize routing and logistics. For instance, tracking the exact locations of the fleet makes it possible to make more efficient dispatching decisions.
In addition, it is crucial to detect critical issues like engine overheating or low fuel levels to prevent breakdowns and delays. By analyzing the incoming telemetry data, you aim to predict maintenance needs before failures occur, enhancing safety and operational efficiency.
The immediate alerts for any critical conditions are essential to maintain uninterrupted service and ensure the safety of drivers and cargo.
System Architecture
To effectively monitor this fleet, you come up with an architecture that integrates data collection, processing and alerting components. The description of each component can be found below.
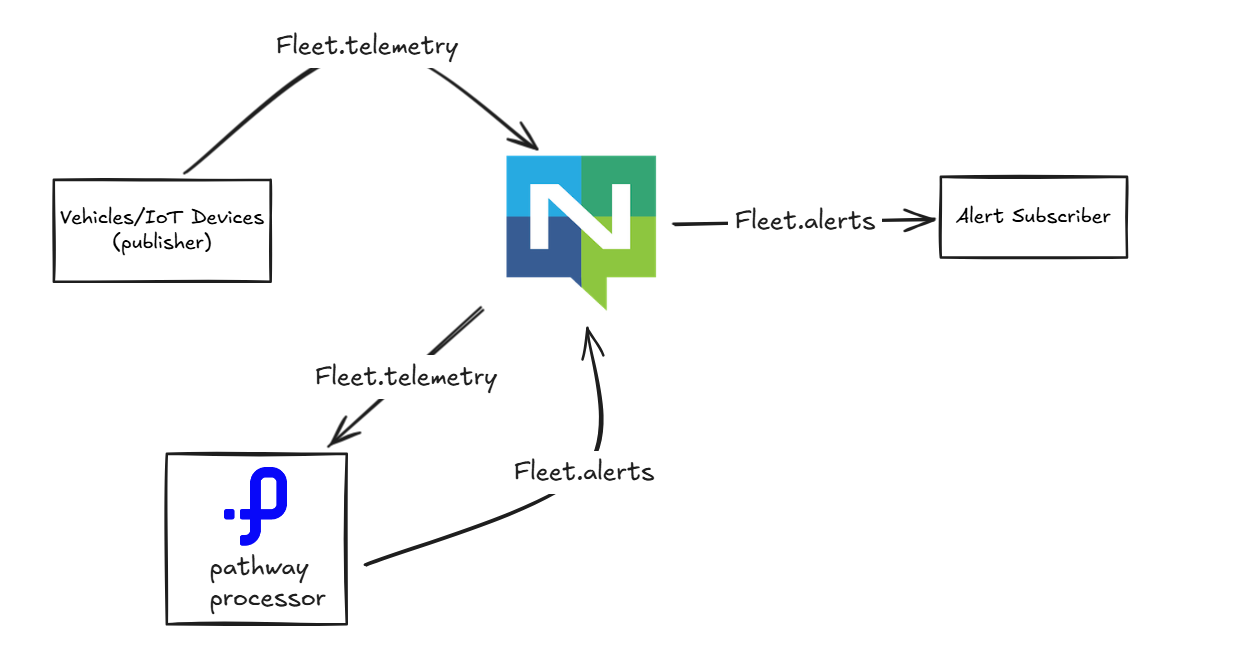
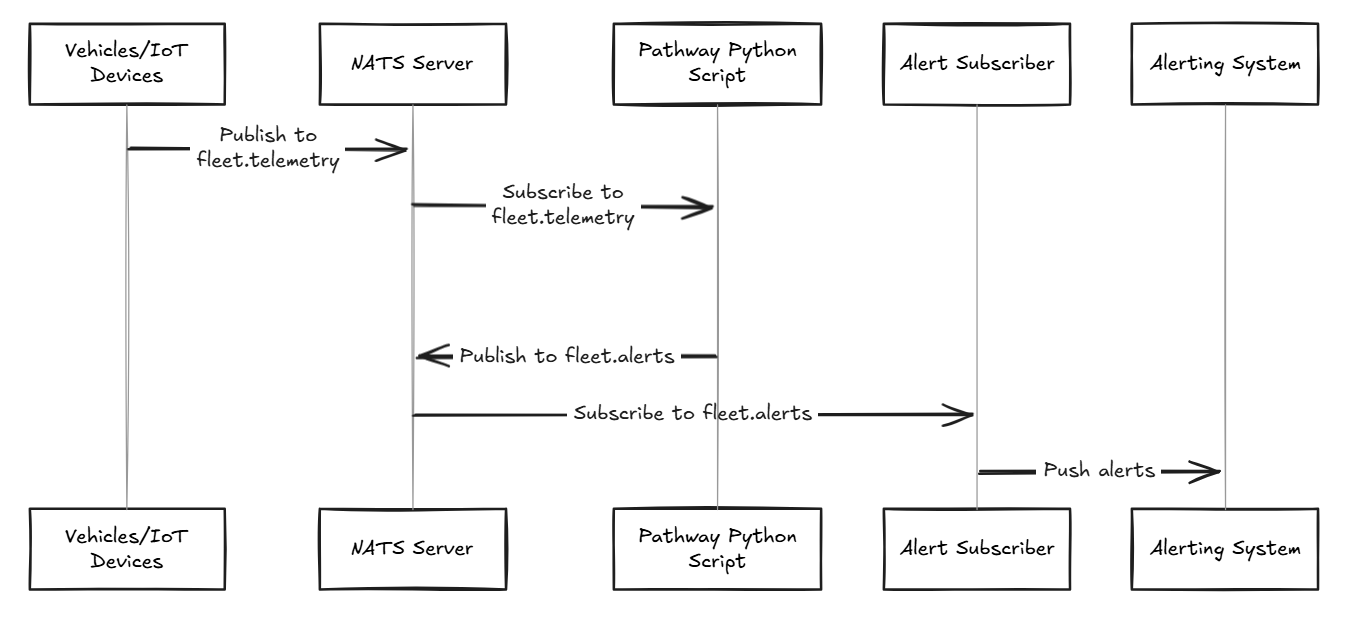
The data flow in the system is illustrated by the following figure:
Vehicles/IoT Devices:
The devices generate telemetry data, such as vehicle location, speed, temperature, and any other relevant metrics. This data is published to a specific subject on the NATS Server, named fleet.telemetry.
NATS Server:
The NATS Server acts as a message broker facilitating communication between various system components. Two different subjects will be used in the NATS server here, one to send the telemetry data and one to send alerts.
fleet.telemetry: Vehicles/IoT devices send their telemetry data to this subject. The Pathway Python Script subscribes to this subject to process the incoming telemetry data.fleet.alerts: After processing, if any conditions or anomalies are detected, the Pathway Python Script publishes alerts to this subject.
Pathway Live Data Framework Anomaly Detection Script:
This script is responsible for processing the telemetry data it receives from fleet.telemetry. It might include logic for detecting anomalies, such as speeding, out-of-bounds location, or malfunction alerts. If an anomaly is detected, the script publishes an alert to the fleet.alerts subject on the NATS server.
Alert Subscriber:
This component subscribes to the fleet.alerts subject to receive alerts published by the Pathway Python Script in json format.
Alerting System:
The Alert Subscriber pushes these alerts to the Alerting System. The Alerting System can be responsible for:
- Delivering the alerts to stakeholders, such as sending notifications via email, SMS, or dashboard updates.
- Triggering further workflows or escalations based on the nature of the alerts.
Since the primary focus of this tutorial is data processing and anomaly detection using Pathway, for the purpose of this tutorial, an alerting system is omitted. Alerts will be printed on the terminal, which can later be pushed to any alerting system of your choice.
Simulating Telemetry Data
Since there is no real source of signals in this tutorial, you need to have a simulator that creates and publishes random data to a NATS subject.
Below are several steps you need to take in order to create this simulator:
- Import necessary modules:
import asyncio
import nats
import json
from datetime import datetime
import random
- Define an asynchronous function to publish telemetry data:
async def publish_telemetry():
- Connect to the NATS server:
nc = await nats.connect("nats://localhost:4222")
- Simulate a list of vehicle IDs:
vehicle_ids = [f"TRUCK-{i}" for i in range(1, 6)] # Simulate 5 trucks
- Start an infinite loop to publish data periodically:
while True:
- Generate random telemetry data:
telemetry = {
"vehicle_id": random.choice(vehicle_ids),
"timestamp": datetime.utcnow().isoformat(),
"lat": random.uniform(34.0, 35.0),
"lon": random.uniform(-118.0, -117.0),
"engine_temp": random.randint(70, 120), # Critical if >100
"fuel_level": random.randint(10, 100), # Critical if <20
"brake_health": random.randint(50, 100) # Critical if <60
}
- Publish the telemetry data to the
'fleet.telemetry'subject:
await nc.publish("fleet.telemetry", json.dumps(telemetry).encode())
Convert the telemetry data to a JSON string and encode it to bytes.
- Wait for a second before publishing the next data point:
await asyncio.sleep(1)
- Run the asynchronous function:
asyncio.run(publish_telemetry())
Complete Telemetry Publisher Code (telemetry_publisher.py):
import asyncio
import nats
import json
from datetime import datetime
import random
async def publish_telemetry():
# Connect to the NATS server
nc = await nats.connect("nats://localhost:4222")
vehicle_ids = [f"TRUCK-{i}" for i in range(1, 6)] # Simulate 5 trucks
while True:
# Generate random telemetry data
telemetry = {
"vehicle_id": random.choice(vehicle_ids),
"timestamp": datetime.utcnow().isoformat(),
"lat": random.uniform(34.0, 35.0),
"lon": random.uniform(-118.0, -117.0),
"engine_temp": random.randint(70, 120), # Critical if >100
"fuel_level": random.randint(10, 100), # Critical if <20
"brake_health": random.randint(50, 100) # Critical if <60
}
# Publish telemetry data as JSON
await nc.publish("fleet.telemetry", json.dumps(telemetry).encode())
await asyncio.sleep(1)
# Run the asynchronous function
asyncio.run(publish_telemetry())
Processing Data with Pathway Live Data Framework Anomaly Detection Script
Now that data is flowing into the fleet.telemetry subject in NATS. It’s time for you to process that data and identify anomalies, as discussed in the proposed architecture above. This step will detect any anomaly in the telemetry data and push it to a fleet.alerts subject.
If one of the below criteria is met in any of the Trucks in your fleet, it’s an anomaly and needs to be alerted immediately:
- Engine Temperature > 100
- Fuel Level < 20
- Brake Health < 60
You have to write code using Pathway Live Data Framework to detect these anomalies and push alerts back to the NATS server.
Follow the steps to write the Pathway anomaly detection script:
- Import Pathway:
import pathway as pw
- Define the telemetry schema:
class TelemetrySchema(pw.Schema):
vehicle_id: str
timestamp: str
lat: float
lon: float
engine_temp: int
fuel_level: int
brake_health: int
This schema maps the JSON fields to table columns.
- Ingest telemetry data from NATS: Messages are read from the fleet.telemetry subject. format="json" specifies that the messages are in JSON format. The schema parameter tells Pathway how to parse the JSON data.
telemetry_table = pw.io.nats.read(
uri="nats://127.0.0.1:4222",
topic="fleet.telemetry",
format="json",
schema=TelemetrySchema
)
- Define a User-Defined Function (UDF) for detecting alerts:
You can define a UDF to encapsulate the logic for detecting multiple alerts per data point. This allows you to check all the conditions and generate multiple alerts if necessary. Refer to this link to read more about UDFs in Pathway Live Data Framework: https://pathway.com/developers/user-guide/data-transformation/user-defined-functions
@pw.udf
def detect_alerts(engine_temp, fuel_level, brake_health):
alerts = []
if engine_temp > 100:
alerts.append("High Engine Temp")
if fuel_level < 20:
alerts.append("Low Fuel Level")
if brake_health < 60:
alerts.append("Poor Brake Health")
return alerts
- Apply the UDF and generate multiple alerts:
You apply the detect_alerts UDF to each row in the telemetry_table. The UDF returns a list of alerts, which can contain multiple alert messages for each data point.
select() is used to create new table alerts with the necessary fields.
alerts = telemetry_table.select(
vehicle_id=pw.this.vehicle_id,
timestamp=pw.this.timestamp,
alert_type=detect_alerts(
pw.this.engine_temp,
pw.this.fuel_level,
pw.this.brake_health
)
)
- Flatten the alerts and filter out rows with no alerts:
Since the alert_type column now contains lists of alerts, you need to flatten it to have one alert per row. Then you can filter out any rows where alert_type is None or empty.
alerts = alerts.flatten(pw.this.alert_type).filter(pw.this.alert_type.is_not_none())
- Output alerts to another NATS subject:
Alerts are then published to the fleet.alerts subject in JSON format.
pw.io.nats.write(
alerts,
uri="nats://127.0.0.1:4222",
topic="fleet.alerts",
format="json"
)
- Run the Pathway pipeline:
pw.run()
Complete Telemetry Processor Code (telemetry_processor.py)
import pathway as pw
# Define the telemetry schema
class TelemetrySchema(pw.Schema):
vehicle_id: str
timestamp: str
lat: float
lon: float
engine_temp: int
fuel_level: int
brake_health: int
# Ingest telemetry data from NATS
telemetry_table = pw.io.nats.read(
uri="nats://127.0.0.1:4222",
topic="fleet.telemetry",
format="json",
schema=TelemetrySchema
)
# Define a UDF for detecting alerts with if conditions
@pw.udf
def detect_alerts(engine_temp, fuel_level, brake_health):
alerts = []
if engine_temp > 100:
alerts.append("High Engine Temp")
if fuel_level < 20:
alerts.append("Low Fuel Level")
if brake_health < 60:
alerts.append("Poor Brake Health")
return alerts
# Apply the UDF and generate multiple alerts
alerts = telemetry_table.select(
vehicle_id=pw.this.vehicle_id,
timestamp=pw.this.timestamp,
alert_type=detect_alerts(
pw.this.engine_temp,
pw.this.fuel_level,
pw.this.brake_health
)
)
# Filter rows with no alerts
alerts = alerts.flatten(pw.this.alert_type).filter(pw.this.alert_type.is_not_none())
# Output alerts to another NATS subject
pw.io.nats.write(
alerts.select(
vehicle_id=pw.this.vehicle_id,
timestamp=pw.this.timestamp,
alert_type=pw.this.alert_type
),
uri="nats://127.0.0.1:4222",
topic="fleet.alerts",
format="json"
)
# Run the Pathway pipeline
pw.run()
Subscribing to Alerts
In a real-world application, other services or systems would subscribe to the fleet.alerts subject to receive and act upon real-time alerts generated by the Pathway anomaly detection script. These services might include dashboards, notification systems, or automated workflows that handle critical events. Depending on the severity of an alert, the system could escalate it appropriately—for example, by sending an SMS or making a phone call for high-priority issues, while less critical alerts might be sent via email or logged for later review. Alerts could also be duplicated across popular messaging platforms to ensure they reach the relevant stakeholders promptly.
For the sake of this tutorial, to demonstrate that the data pipeline works correctly, it is sufficient to have a simple subscriber script that listens to the fleet.alerts subject and prints the received alerts to the console.
Complete code for the subscriber (alerts_subscriber.py):
import asyncio
import nats
import json
async def receive_alerts():
nc = await nats.connect("nats://localhost:4222")
async def alert_handler(msg):
alert = json.loads(msg.data.decode())
print(f"ALERT: Vehicle {alert['vehicle_id']} - {alert['alert_type']} at {alert['timestamp']}")
await nc.subscribe("fleet.alerts", cb=alert_handler)
print("Subscribed to 'fleet.alerts' subject.")
while True:
await asyncio.sleep(1)
asyncio.run(receive_alerts())
Testing your setup
It’s finally time to test your setup. As mentioned previously, you need to run the subscriber script before running the publisher scripts.
You can start running the scripts above by following these steps:
- Run your subscriber script alerts_subscriber.py that subscribes to
fleet.alertssubject:
python alerts_subscriber.py
- Run your Pathway anomaly detection script that reads from
fleets.telemetrysubject and writes tofleets.alertssubject:
python alerts_subscriber.py
- Now run your publisher script that stimulates telemetry data and is pushing to
fleets.telemetrysubject:
python alerts_subscriber.py
In the output terminal for the alerts_subscriber.py in step 1 above, you should now be able to see alerts similar to the ones below.
ALERT: Vehicle TRUCK-3 - High Engine Temp at 2024-11-25T12:43:33.809829
ALERT: Vehicle TRUCK-1 - High Engine Temp at 2024-11-25T12:43:34.811335
ALERT: Vehicle TRUCK-2 - High Engine Temp at 2024-11-25T12:43:35.812677
Conclusions
In this tutorial, you have learned how to build a real-time data processing system by integrating NATS with Pathway Live Data Framework as powerful alternatives to Kafka and Flink. Starting by setting up basic publishers and subscribers using NATS and Python, then connecting Pathway to NATS to process messages in real time. The fleet monitoring use case, has shown how to ingest telemetry data, identify critical conditions, and generate alerts.
Below is the recap of the key points of the technologies discussed in this article.
Benefits of Using Pathway Live Data Framework (the Flink alternative here) and its NATS Connector:
- Seamless Integration: The framework’s native NATS connectors allow you to directly ingest data from NATS subjects into Pathway Live Data Framework without writing custom integration code. This streamlines development and lets you focus on processing logic rather than data plumbing.
- High Performance and Low Latency: Both NATS and Pathway Live Data Framework are designed for speed. NATS handles rapid message delivery, while the framework processes streams in real time. This ensures that data is analyzed and alerts are generated almost instantly.
- Scalability: NATS supports clustering, and Pathway Live Data Framework can distribute processing across multiple nodes. This means your system can handle increased data volumes as your application grows.
- Flexibility in Data Formats: The framework’s NATS connectors handle various data formats, including JSON, plaintext, and raw bytes. This allows you to work with the data format that best suits your application.
- Reliability and Fault Tolerance: NATS offers features like message acknowledgment and clustering for high availability. The Pathway Live Data Framework can recover state after failures, ensuring continuity in processing.
Advantages of NATS – the Kafka alternative:
- Lightweight and Efficient: NATS is a lightweight messaging system that provides fast and reliable communication between distributed systems.
- Simple Publish/Subscribe Model: Its straightforward pub/sub model makes it easy to implement asynchronous communication.
- Flexible Topologies: NATS supports various communication patterns and can be deployed in diverse architectures.
This way, by leveraging the strengths of both NATS and Pathway, you can build scalable, efficient, and reliable real-time data processing systems.
Additional Resources
- NATS Documentation: docs.nats.io
- NATS Python Client: nats.py GitHub
- Pathway Documentation: pathway.com/docs
- Pathway GitHub Repository: pathwaycom/pathway
- Synadia Multi-cloud NATS.io Platform Docs: https://docs.synadia.com/cloud
- AsyncIO in Python: Python AsyncIO Documentation

 Saksham Goel
Saksham Goel blog · tutorial · engineeringFeb 5, 2025Real-Time AI Pipeline with DeepSeek, Ollama and Pathway
blog · tutorial · engineeringFeb 5, 2025Real-Time AI Pipeline with DeepSeek, Ollama and Pathway Olivier Ruas
Olivier Ruas blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework
blog · tutorial · engineering · frameworkFeb 2, 2026Real-Time OCR with PaddleOCR and Pathway Live Data Framework Shlok Srivastava
Shlok Srivastava blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework
blog · tutorialFeb 11, 2025Apache Iceberg Connectors for Real-Time Data Pipelines with Pathway Live Data Framework