AI Paper Reviewer | LiveAI™ for Conference Classification

 Pathway Community
Pathway Community1. Why Another AI Paper Reviewer?
Because the stakes—and the gaps—are bigger than ever.
“Scientists get naturally anxious when submitting a research paper. We know that peer review is coming.”
— PeerRecognized
Most “AI helpers” still act like static proofreading bots.
- A GPT plug-in on ResearchGate offers generic feedback across “various parameters.”
- Marketplaces such as YesChat promise “Expert AI-Powered Academic Paper Reviews.”
- Even full-fledged platforms like Paper Digest warn that hallucinations remain a critical risk and stress the need for citation-grounded outputs—because “for research, every word counts.”
Yet none of these tools confront the two questions that make or break a submission:
- Is my work publishable right now?
- Which conference will actually accept it?
Enter the LiveAI™ Paper Reviewer
Built on a dual-LLM Tree-of-Thought Actor–Contrastive-Critic (TACC) engine and a hybrid Retrieval-Augmented Generation (RAG) layer, this system goes far beyond copy-editing:
- Binary publishability prediction with up to 92% real-world accuracy.
- Ensemble-reasoned conference classification (SCHOLAR → SCRIBE) that resolves overlap, class imbalance, and keyword bias across venues like CVPR, EMNLP, KDD, NeurIPS, and TMLR.
Because the entire pipeline runs in streaming mode, every new paragraph, revision, or freshly uploaded pre-print is re-indexed on the fly—turning conventional peer-review anxiety into live, data-backed confidence.
User Walkthrough: LiveAI™ for Conference Classification and Paper Publishability Prediction

Code Repository - Complete Setup & Usage Guide
2. Building the AI Paper Reviewer: The Architecture of TACC
2.1. Motivation: Moving Beyond the Black Box to a Transparent AI Reviewer
Our first objective was to determine a paper's publishability. While a basic LLM prompt can achieve reasonable accuracy, it functions as an opaque "black box," providing an answer without a verifiable line of reasoning. For a task that demands trust and justification, this is a non-starter. Our core motivation was to construct a "glass box" , a system whose decision-making process is transparent, auditable, and structurally sound.
2.2. Our Design Journey: From Simple Embeddings to Agentic Reasoning
Our final architecture was the culmination of a deliberate, four-stage evolution:
- Stage 1: BERT-Based Clustering (73.3% Accuracy): A foundational but naive start.
- Stage 2: Basic LLM Classification (78% Accuracy): A leap in knowledge, but a step back in transparency.
- Stage 3: Simple Actor-Critic (83% Accuracy): Our first foray into meta-cognition, proving that a system's ability to evaluate its own reasoning was the path forward.
- Stage 4: The TACC Architecture: The synthesis of our learnings into a sophisticated, transparent reasoning engine.
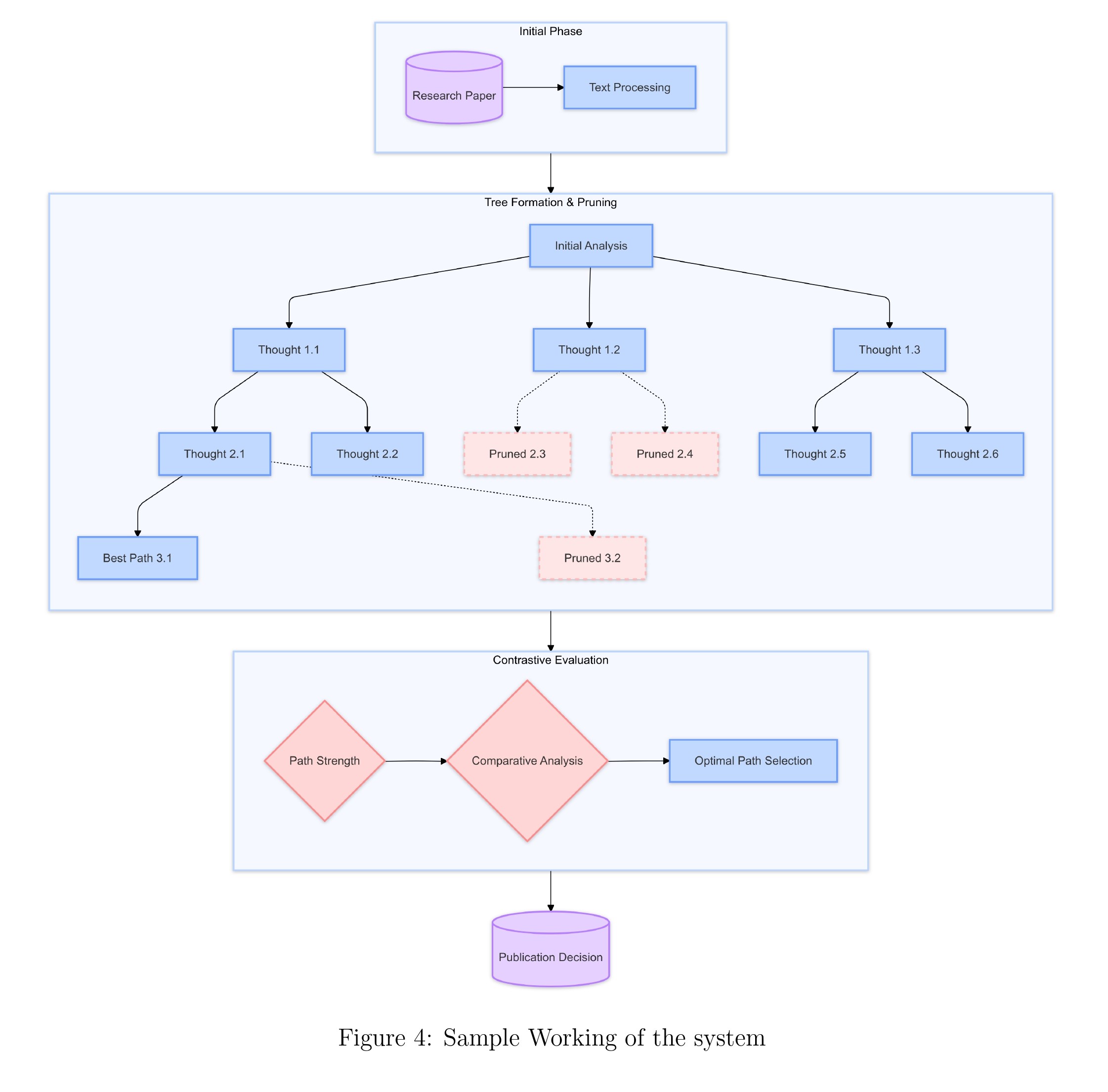
2.3. TACC: An Architectural Deep Dive into our AI Paper Reviewer
TACC (ToT Actor–Contrastive-CoT Critic) is a dual-LLM system engineered for hierarchical, multi-step reasoning. It integrates several advanced AI paradigms to create an evaluation engine that is both accurate and interpretable.
2.3.1. Core Framework: Why Tree of Thoughts (ToT) for AI Review?
At the heart of TACC lies the Tree of Thoughts framework. Unlike a linear Chain of Thought (CoT), which pursues a single, sequential line of reasoning, ToT empowers the system to explore multiple analytical branches in parallel. This is a fundamental architectural choice. When a human expert reviews a paper, they don't just read it from start to finish; they concurrently evaluate its novelty, check its methodology for flaws, assess the clarity of its language, and question the validity of its conclusions. ToT mimics this divergent thinking process, allowing our AI to build a comprehensive and multi-faceted understanding of the paper's quality. This entire workflow is programmatically managed in agent/services/tree_of_thoughts.py.
2.3.2. The Decisive Component: Intelligent Pruning with Contrastive CoT
This is TACC's most significant innovation. A standard evaluation loop would have the Critic assess each of the Actor's thoughts in isolation ("Is this thought valid?"). We implemented a more sophisticated Contrastive Chain-of-Thought. In this paradigm, the Critic is prompted to take a set of parallel thoughts and explicitly compare them against each other. It must generate a structured rationale answering questions like: "Which of these three analytical paths is most critical to the paper's publishability? Which argument is best supported by textual evidence? Which path is a red herring?" This comparative analysis allows the system to intelligently prune weaker or less relevant branches, ensuring that computational resources are focused on the most promising lines of inquiry.
2.3.3. Engineering TACC, an Efficient AI Reviewer: Asynchronicity and Optimization
Building a ToT system that performs well requires careful engineering.
- The Dual-LLM Dynamic: We made a strategic decision to use two different models. The Actor, responsible for generating a wide "fan-out" of thoughts, was gpt-4o-mini. Its speed and cost-effectiveness were ideal for generating breadth. The Critic, which required nuanced understanding for its contrastive analysis, was the more powerful gpt-4o. This created a highly effective and economically viable division of labor.
- Asynchronous Execution: The entire system, implemented in agent/services/paper_evaluator.py, is built on Python's asyncio. The Actor's thought generation and the Critic's evaluation are executed as parallel, asynchronous tasks. This means that while the Critic is evaluating the thoughts at Depth N, the Actor can already begin generating new branches for Depth N+1 from the previously validated nodes. This concurrent processing was crucial for achieving high performance.
- Strategic Pruning: Through empirical testing, we found our "sweet spot" for performance and cost. At each depth of the tree (up to a maximum of 3), the Critic was configured to prune the weakest one-third of the thought branches. The remaining validated nodes would then serve as the foundation for the next level of thought generation, each producing three new branches. This 3x3 expansion-pruning cycle kept the search space manageable while allowing for deep exploration.
This robust architecture resulted in 100% accuracy on the reference sample papers and an exceptional 92% overall accuracy on the combined, human-labeled dataset.
3. Mastering Conference Classification: The SCRIBE Multi-Agent Ensemble
3.1. How Pathway helped as a LiveAI™ layer:
- Our conference classification agent couldn't rely on a static, pre-trained model. It needed to be grounded in a live, evolving dataset of academic papers. Pathway provided the critical infrastructure for this "LiveAI™ Layer."
- We chose Pathway for its performance and simplicity. Its core engine is written in Rust, ensuring the low-latency data processing required for a responsive RAG pipeline. This speed was essential for minimizing the time-to-first-token in our LLM agent.
- Pathway’s unified architecture handles both batch and streaming data with the same code. This simplified our development, allowing us to use a single logic for both the initial bulk indexing and for processing new papers as they arrived.
- Pathway's Google Drive Connector gave us a seamless, real-time data pipeline. It automatically detected and streamed new reference papers from our source folder, keeping our knowledge base current without manual intervention.
- For retrieval, we used Pathway’s DocumentStore configured for hybrid search. This combined fast keyword matching (BM25) with conceptual semantic search (USearchKNN), a crucial capability for navigating the precise and nuanced language of academic research.
In short, Pathway provided the high-performance data backbone, allowing us to focus our efforts on the agent's reasoning logic rather than on complex data engineering.
3.2. The Challenge: Tackling Nuance and Data Imbalance in Conference Classification
Task 2 presented a more subtle challenge. Conferences have thematic overlaps (e.g., NLP papers in EMNLP and NeurIPS) and severe data imbalances (thousands of papers at NeurIPS vs. hundreds at TMLR). A simple classifier would be hopelessly biased. Our motivation was to design a system that could navigate this nuance through a multi-perspective, ensemble-based architecture.
3.3. SCRIBE (Semantic Conference Recommendation with Intelligent Balanced Evaluation)
SCRIBE (Semantic Conference Recommendation with Intelligent Balanced Evaluation) is our solution a multi-agent ensemble where three specialized AI agents independently analyze a paper and "vote" on the best conference. A final controller then weighs these recommendations to make an informed decision.

3.4. The SCRIBE Expert Committee: A Three-Pronged Approach to Classification
3.4.1. Agent 1: The 'Cookbook' LLM for Foundational Knowledge
This agent's expertise comes from a meticulously curated knowledge base we called the "Cookbook." This was not a simple prompt; it was a comprehensive, structured document built through a semi-automated pipeline. We used advanced web-scraping agents and LLM-powered summarization (akin to Gemini's DeepResearch) to synthesize information from hundreds of sources, official conference websites, calls for papers, and topical analyses from academic blogs. The resulting "cookbook" provided the LLM agent (agent/services/llm_based_classifier.py) with a deep, nuanced understanding of each conference's unique academic identity, including its core topics, methodological preferences, and evolving trends.

3.4.2. Agent 2: Real-Time Pathway RAG Agent for Data-Grounded Conference Classification
This agent provided a data-driven perspective grounded in historical precedent, and it was our direct implementation of the hackathon's core requirement.

- Real-Time Data Ingestion: Using Pathway’s Google Drive Connector (indexer/services/drive_connector.py), we created a live data pipeline that streamed reference papers directly from the source.
- Advanced Hybrid Retrieval: We indexed this content using Pathway’s DocumentStore, which we configured in indexer/services/document_store.py for hybrid retrieval. This is a crucial technical choice. It combines BM25 for fast, keyword-based lexical search with USearchKNN for dense, semantic search. This dual-pronged approach, powered by Pathway's efficient indexing, allowed our RAG agent (agent/services/rag_based_classifier.py) to retrieve highly relevant examples from past conference papers, providing a robust foundation for its recommendations.
3.4.3. Agent 3: The SCHOLAR Agent for Global-Scale Analysis
This agent(agent/services/similarity_based_classifier.py) was designed to overcome the limitations of our local dataset and tap into the vast corpus of global academic research.
- Hierarchical Query Generation: It begins with an LLM that generates 5-7 diverse search queries. This is run in parallel five times, and a "consolidator" agent synthesizes the ~30 initial queries into 10-20 unique, non-redundant queries, optimizing the search space.
- Large-Scale Search & Re-ranking: These queries are dispatched to the Semantic Scholar API, searching over 190 million papers. The top 1,000 results are then re-ranked using lightweight machine learning models (like learning-to-rank algorithms) that consider metadata features and fuzzy text matching to promote the most relevant results.
- Final RAG Similarity: The top 100 papers from this re-ranked list then undergo a final, precise similarity comparison between their abstracts and a summary of the input paper.
- Logarithmic Scoring for Imbalance: To solve the critical data imbalance problem, we devised a logarithmic scoring function: Final Score = Average Similarity * log(Number of Papers). The logarithm dampens the effect of raw paper counts, preventing a conference like NeurIPS from winning simply because it has more papers. This focuses the decision on the quality of the match, not the size of the conference. We also explored a more advanced version where an LLM would perform a final qualitative re-ranking of the top-scoring papers, though for the hackathon, the direct metric was used for efficiency.
3.5. The Ensemble Controller: From Voting to Agentic Adjudication
Currently, the FinalClassifier (agent/services/final_classifier.py) analyzes the outputs and rationales from the three agents to make a reasoned final decision. A key future improvement would be to replace this with a dedicated "Judge Agent." This agent could use an Actor-Critic framework itself to moderate a simulated debate, forcing the three agents to justify their choices and leading to an even more robust and transparent final recommendation.

4. Engineering for Performance and the Future of AI Paper Review
4.1. Optimizing for Speed: Inference Acceleration with LPUs and Speculative Decoding
We leveraged Groq's LPU™ Inference Engine for its exceptional speed on sequential language tasks. We further amplified this with speculative decoding, where a smaller "draft" model generates token sequences that are then validated in a single pass by the larger model, dramatically increasing throughput.
4.2. The Path Forward: Next-Generation Models and Automated System Tuning
The field is advancing rapidly.
- Next-Generation Models: Our architecture is model-agnostic. Integrating newer, more powerful reasoning models (like gemini-2.5-pro, o3, o4-mini-high, and claude 4 sonnet) is a direct path to higher performance.
- Hyperscale Inference: Emerging hardware like Cerebras's Wafer-Scale Engines, which can hold entire LLMs on a single chip, could enable near-instantaneous analysis of entire research libraries.
- Automated System Tuning: A truly advanced implementation would involve a meta-learning layer. A reinforcement learning agent could learn to dynamically tune the system's parameters like the pruning threshold in TACC or the voting weights in SCRIBE based on feedback, creating a self-improving system that gets more accurate over time.
5. Conclusion
Our journey was a deep dive into the practical engineering of complex AI systems. We demonstrated that the true power of modern LLMs is unlocked when they are augmented with structured reasoning frameworks like Tree of Thoughts and grounded in real-world data via technologies like the real-time RAG using Pathway pipeline. TACC and SCRIBE represent a philosophical shift from AI as a passive tool to AI as an active analytical partner.
Take a look at the original report
If you are interested in diving deeper into the topic, here are some good references to get started with Pathway:
- Pathway Developer Documentation
- Pathway's Ready-to-run App Templates
- End-to-end Real-time RAG app with Pathway
- Discord Community
Authors

Pathway Community
Multiple authors




