LiveAI™ for SEC Filings Analysis

 Pathway Live Data Framework Community
Pathway Live Data Framework CommunityIntroduction
When finance professionals spend hours digging through dense SEC filings, it’s clear we need better tools, enter AI for SEC filings.
The average annual report filed with the SEC (Form 10-K) exceeds 150 pages and contains thousands of data points, making manual analysis both time-consuming and error-prone.
Our team tackled this challenge head-on by developing a sophisticated LiveAI™ for SEC Filings system powered by multi-agent RAG (Retrieval-Augmented Generation)—transforming how financial documents are analyzed and understood in real time.
The result? A system that achieved 56% accuracy on FinanceBench, one of the most challenging evaluation datasets for financial document analysis significantly outperforming the baseline 19% accuracy reported for GPT-4 Turbo.
The Challenge: Why Traditional RAG Fails on SEC Filings
SEC filings present unique challenges that break traditional RAG systems. Each page contains dense, tabular data that appears nearly identical to embedding models, causing similarity search to fail catastrophically. Even exact matching algorithms like BM25 struggle when dealing with multiple companies' filings in a single index.
Consider this scenario: a finance professional needs to compare revenue growth across three different companies from their 10-K filings. Traditional systems would either:
- Return irrelevant chunks due to poor similarity matching
- Miss critical data buried in complex tables
- Fail to perform the mathematical calculations needed for comparison
Our multi-agent approach solves these fundamental limitations through intelligent architecture design and data enrichment strategies.
Enter the Multi-Agent Financial Document Analyzer
Built on a sophisticated Supervisor-Agent architecture with dynamic RAG enhancement and mathematical computation capabilities, this system transforms traditional document analysis:
- 56% accuracy on FinanceBench (Arxiv Paper) - dramatically outperforming GPT-4 Turbo's 19% baseline
- Intelligent data enrichment that solves the similarity search problem plaguing dense financial tables
- Expert reasoning simulation with specialized financial personas (Risk Management, Market Sentiment, Fundamental Analysis)
- Mathematical computation agent ensuring calculation accuracy that LLMs typically fail at
- Built on the Pathway Live Data Framework’s LiveAI™ infrastructure - every new SEC filing is processed and indexed in real-time, turning traditional research bottlenecks into instantly accessible insights.
System Demonstration: LiveAI™ for SEC Filings Analysis
Video Walkthrough - Complete System in Action
Code Repository - Complete Setup & Usage Guide
Architecture Deep Dive: Supervisor With Agents as Tools
Why We Chose This Architecture
After evaluating multiple multi-agent architectures including fully connected networks, hierarchical systems, and custom topologies, we selected the "Supervisor with Agents as Tools" approach with an even more modified version inspired by the LLM Compiler paper.
This architecture provides three critical advantages:
- Context Separation: Each agent maintains its own context, preventing the supervisor from getting overwhelmed by individual task details while focusing on the bigger picture.
- Parallel Execution: The supervisor can call multiple agent tools simultaneously, dramatically reducing processing time for complex queries.
- Token Efficiency: This approach requires fewer total tokens compared to other multi-agent architectures, making it more cost-effective at scale.
The LLM Compiler Enhancement
Our implementation incorporates the LLM Compiler's innovation of concurrent function calling using a directed acyclic graph. This creates execution plans with built-in routing logic, allowing for truly intelligent task orchestration.
Dynamic RAG Pipeline: Solving Key Challenges in AI for SEC Filings
The Data Enrichment Strategy
Raw SEC filing chunks are information-dense but retrieval-unfriendly. Our solution enriches each chunk with three key components:
- Contextual Descriptions: LLM-generated summaries that include context from surrounding chunks
- Markdown Formatting: Enhanced readability for both humans and AI systems
- Search Query Generation: Relevant queries derived from table content to improve discoverability
- MetaData Inclusion: Included metadata such as document type, year, company name etc for metadata filtering.
This was possible using the support of unstructured parser supported by the framework’s retrievers.
Here's what this enrichment process achieves:

Before Enrichment: A raw table with quarterly revenue figures After Enrichment: The same table plus a natural language description explaining revenue trends, formatted in readable markdown, with associated search terms like "quarterly revenue growth Q3 2023"
Advanced Retrieval Capabilities

Our RAG agent incorporates several sophisticated features:
- Multi-query Decomposition: Breaking complex questions into retrievable sub-queries
- Web Search Integration: Accessing real-time market data when needed
- Grading and Reranking: Quality assessment of retrieved content
- Retry Logic: Intelligent decision-making on when to retry retrieval
The agent makes autonomous decisions about data quality and retrieval success, ensuring the supervisor receives only relevant, high-quality information.
The Pathway Live Data Framework: The Infrastructure Foundation
Our dynamic RAG pipeline's success relied heavily on the Pathway Live Data Framework serving as the LiveAI™ layer that handled enterprise-scale data integration and retrieval optimization.
Seamless Data Integration: The framework's Google Drive connector eliminated traditional data pipeline complexity, automatically ingesting new SEC filings and regulatory documents without manual intervention. This plug-and-play integration allowed us to focus on multi-agent orchestration rather than data management.
Hybrid Retrieval Enhancement: Beyond our data enrichment strategy, we leveraged the framework's built-in hybrid search combining vector similarity with BM25 keyword matching. This proved crucial for financial documents filled with domain-specific jargon, stock tickers, and regulatory codes that embedding models often under-emphasize. We configured BM25 with a 0.6 weight alongside semantic search, ensuring exact financial terms weren't lost while maintaining contextual relevance.
Advanced Metadata Filtering: The framework's out-of-the-box metadata filtering capabilities allowed our agents to narrow search scope rapidly:
- Company-specific queries by ticker symbol
- Time-based filtering for specific quarters or fiscal years
- Document type restrictions (10-K vs. 8-K reports)
- Regulatory section targeting for specific disclosures
These filters operate at the vector store level, dramatically reducing search space before similarity calculations and improving both response time and result relevance.
Performance at Scale: The optimized Rust backend ensured consistently low latency even when multiple agents queried simultaneously, supporting our concurrent execution architecture while maintaining the token efficiency that made our supervisor-agent approach cost-effective.

Specialized Agent Tools: Beyond Simple Retrieval
The Mathematical Computation Agent
Financial analysis requires precise calculations that LLMs often get wrong. Our mathematical agent uses code interpreter capabilities to:
- Determine whether calculations should be performed in LLM memory or through code execution
- Handle large-scale data processing with accuracy
- Provide step-by-step calculation breakdowns for transparency
This agent bridges the gap between data retrieval and actionable financial insights.

The Expert Reasoning Group: Domain-Adaptive Professional Simulation
One of our most innovative and transferable tools simulates conversations between domain experts with different specializations. For financial analysis, this includes:
- Risk Management Analysts: Assess potential downsides and regulatory concerns
- Market Sentiment Experts: Evaluate investor perception and market positioning
- Fundamental Analysts: Deep-dive into company fundamentals and valuation metrics
These personas engage in structured dialogues using retrieved data, mimicking how real professional teams collaborate on complex decisions. This approach leverages the same reasoning principles that make modern LLMs more effective generating extensive intermediate reasoning before reaching conclusions.
The beauty of this system lies in its adaptability. The expert personas are easily configurable, making the entire framework transferable to virtually any professional domain requiring complex document analysis and multi-perspective reasoning.

Rapid Report Generation
For time-pressed professionals, our system includes a report generation tool that creates concise, two-page company summaries. These reports distill key financial metrics, recent performance, and risk factors into actionable insights.
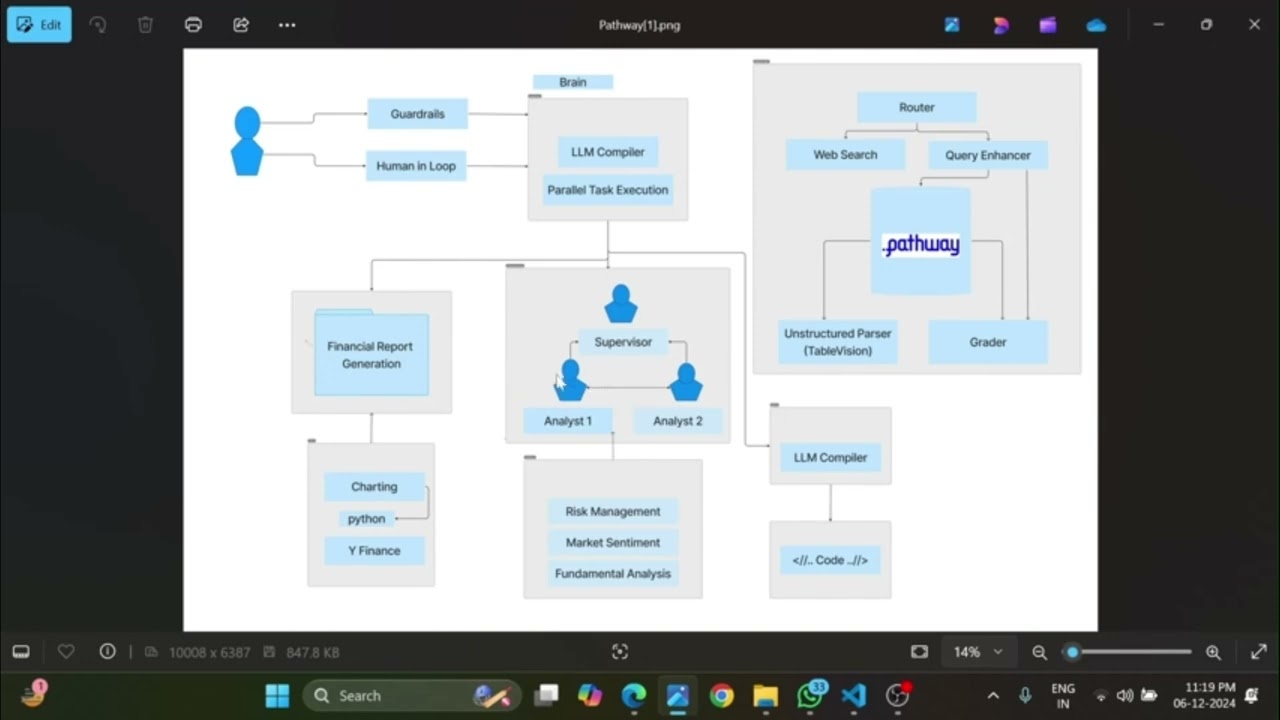
Complete System Architecture
Now that we've covered each component, the diagram above shows how all pieces work together from initial document ingestion through the enriched RAG pipeline, mathematical processing, expert reasoning simulation, and final report generation.

Performance Results: FinanceBench Evaluation
We tested our system against FinanceBench, one of the most challenging benchmarks for financial document analysis:
- Baseline (Simple RAG): 24% accuracy
- With Data Enrichment: 36% accuracy
- Complete Multi-Agent Pipeline: 42% accuracy
- Human-in-the-Loop Integration: 56% accuracy
The human-in-the-loop component allows for clarification requests, significantly boosting accuracy for ambiguous queries while maintaining system autonomy for straightforward tasks.

Implementation Insights and Lessons Learned
Data Processing at Scale
We leveraged the Pathway Live Data Framework's Google Drive connector for seamless data ingestion, allowing real-time processing of large volumes of unstructured financial documents. The plug-and-play nature of this integration eliminated traditional data pipeline complexity.
Guardrails and Safety
Input validation includes:
- Content sanitization
- Personally Identifiable Information (PII) detection
- Jailbreak attempt prevention through vector matching
Since SEC filings are public documents, we focused guardrails on user inputs rather than retrieved content.
Performance Optimization
Key optimizations that improved system performance:
- Chunk Size Tuning: Optimizing for both context preservation and retrieval accuracy
- Embedding Model Selection: Testing multiple models for financial document understanding
- Concurrent Processing: Maximizing parallel execution opportunities
- Cache Strategy: Implementing intelligent caching for frequently accessed data
Beyond Finance: Universal Applicability of Multi-Agent RAG
While this system was purpose-built as an AI for SEC filings analysis system, the architecture's components are inherently domain-agnostic. The power of our multi-agent approach lies in its modularity; each component can be adapted to different professional fields without fundamental architectural changes.
Core Components That Transfer Across Domains
Dynamic RAG Pipeline: The data enrichment strategy works for any document type with dense, structured information. Legal contracts, medical research papers, engineering specifications all benefit from contextual descriptions and improved retrievability.
Mathematical Computation Agent: Any field requiring precise calculations can leverage this component. Engineering calculations, statistical analysis in research, or financial modeling in accounting all utilize the same code interpreter capabilities.
Expert Reasoning Simulation: Perhaps the most adaptable component, the multi-persona reasoning system can be reconfigured for any professional domain by simply changing the expert roles and their specialized knowledge areas.
Case Study: Adapting for Legal Document Analysis
Consider how easily our financial system transforms for legal applications:
Original Financial Personas:
- Risk Management Analyst
- Market Sentiment Expert
- Fundamental Analyst
Legal Domain Adaptation:
- Constitutional Law Expert: Analyzes constitutional implications and precedent alignment
- Contract Specialist: Focuses on clause interpretation, liability assessment, and enforceability
- Litigation Strategist: Evaluates case strength, procedural considerations, and potential outcomes
The system would analyze legal documents (contracts, case law, regulatory filings) using the same retrieval and enrichment strategies, but with legal-specific reasoning patterns. For example, when analyzing a complex merger agreement, the three legal personas might debate:
- Constitutional Expert: "The interstate commerce implications here require careful consideration of federal vs. state jurisdiction..."
- Contract Specialist: "The indemnification clauses in Section 8.3 create asymmetric risk exposure that favors the acquirer..."
- Litigation Strategist: "If this deal faces regulatory challenge, the antitrust arguments in the Hart-Scott-Rodino filing suggest a 60% probability of approval..."
Other Domain Applications
Healthcare/Medical Research:
- Clinical Research Specialist
- Regulatory Affairs Expert
- Patient Safety Analyst
Engineering/Technical Documentation:
- Systems Architecture Expert
- Safety Compliance Engineer
- Performance Optimization Specialist
Academic Research:
- Methodology Expert
- Statistical Analysis Specialist
- Peer Review Evaluator
The mathematical agent adapts to domain-specific calculations (statistical analysis for research, safety factor calculations for engineering), while the RAG pipeline handles field-specific document structures and terminology.
- Due Diligence: Rapidly analyzing multiple companies' financial health for investment decisions
- Regulatory Compliance: Tracking changes in financial reporting requirements across filings
- Competitive Analysis: Comparing key metrics and strategies across industry competitors
- Risk Assessment: Identifying potential red flags in financial statements and disclosures
Technical Architecture Considerations
Scalability Design
The system scales horizontally through:
- Independent agent processing
- Distributed vector storage
- Load-balanced API endpoints
- Asynchronous task processing
Integration Capabilities
Built with enterprise integration in mind:
- RESTful API interfaces
- Webhook support for real-time updates
- SSO authentication compatibility
- Audit logging and compliance tracking
Future Enhancements and Roadmap
Current development focuses on:
- Multi-Modal Analysis: Incorporating chart and graph analysis from financial documents
- Temporal Reasoning: Better understanding of time-series financial data
- Regulatory Updates: Automatic adaptation to changing financial reporting standards
- Industry Specialization: Custom models for specific financial sectors
Getting Started With Multi-Agent RAG Systems
If you're considering building similar systems for any professional domain, here are key takeaways:
- Start Simple: Begin with a basic supervisor-agent architecture before adding complexity
- Focus on Data Quality: Invest heavily in data enrichment and preprocessing this principle applies whether you're working with financial statements or legal contracts
- Domain Expertise Configuration: Identify the key professional perspectives in your field and configure expert personas accordingly
- Measure Everything: Establish clear metrics and evaluation datasets early, tailored to your specific domain requirements
- Plan for Scale: Design with horizontal scaling and distributed processing in mind
- User Experience Matters: Balance automation with human oversight capabilities
- Cross-Domain Thinking: Consider how components might be reused or adapted for related professional fields
Conclusion: Advancing AI for SEC Filings
Our multi-agent AI for SEC filings system demonstrates that complex document analysis can be significantly improved through thoughtful architecture design and specialized agent capabilities not just for finance, but across any professional domain requiring deep document understanding and expert reasoning.
By achieving 56% accuracy on challenging financial benchmarks, we've proven that AI can genuinely augment professional capabilities rather than simply replacing manual processes. The system's modular design means these benefits can extend to legal professionals analyzing contracts, medical researchers reviewing literature, or engineers evaluating technical specifications.
The combination of intelligent retrieval, domain-specific computation, and expert reasoning simulation creates a powerful template for professional document analysis tools. As organizations across industries grapple with information overload, this multi-agent approach offers a scalable solution that adapts to sector-specific needs while maintaining high performance standards.
If you are interested in diving deeper into the topic, here are some good references to get started with Pathway:
- Pathway Live Data Framework Developer Documentation
- Pathway Live Data Framework's Ready-to-run App Templates
- End-to-end Real-time RAG app with Pathway Live Data Framework Live Data Framework
- Discord Community
Frequently Asked Questions
What makes this AI for SEC filings solution different from others?
Our multi-agent system solves core issues like table parsing, financial reasoning, and cross-document comparison.
How easily can this system be adapted to other professional domains?
Very easily. The core components are domain-agnostic; only the expert personas and domain-specific terminology need adjustment. We estimate 2-3 weeks for full adaptation to a new field like legal or medical document analysis.
What types of documents work best with this architecture?
Any structured, information-dense documents benefit most financial filings, legal contracts, technical specifications, research papers, or regulatory documents.
How does this compare to existing financial AI tools?
Our multi-agent approach specifically addresses the limitations of single-model systems when dealing with complex, multi-step financial analysis requiring both retrieval and computation.
What types of financial documents can the system analyze?
Currently optimized for SEC filings (10-K, 10-Q, 8-K), with plans to expand to earnings reports, analyst notes, and regulatory submissions.
How accurate is the mathematical computation component?
The code interpreter approach achieves near-perfect accuracy for computational tasks, unlike LLM-only calculations which can introduce errors.
Can the system handle real-time market data?
Yes, through web search integration, though the primary focus remains on structured document analysis rather than live market feeds.
What's required for implementation in an enterprise environment?
Standard enterprise requirements: API access, secure data handling, user authentication, and integration with existing workflow tools.
Authors

Pathway Live Data Framework Community
Multiple authors