Financial Report Analysis with LiveAI™
 Pathway Live Data Framework Community
Pathway Live Data Framework CommunityIntroduction
Most finance work starts with a pile of documents: annual reports, quarterly results, investor decks, filings. They’re long, they change often, and the facts you need are scattered across pages and versions. The result? Hours spent scrolling, searching, and cross-checking numbers just to answer a simple question like “How did margins change compared to last quarter?”
This blog introduces a different way forward: Financial report analysis with LiveAI™. Instead of digging through static PDFs, you ask plain-English questions and get clear answers, always grounded in the latest version of your reports.
Financial teams drown in PDFs: annual reports, investor presentations, SEC/SEBI filings, broker notes; each packed with metrics that move decisions. This post shows how to do financial report analysis with LiveAI™, so you can turn those documents into reliable, queryable insights in minutes not days.
Why LiveAI™ matters: traditional RAG pipelines go stale the moment your corpus changes. The Pathway Live Data Framework treats static and streaming data the same way: once your documents are preprocessed and indexed, it auto-detects updates in your document directory and refreshes the store, keeping every answer grounded in the latest facts. In other words, your RAG stays live by design: no manual re-indexing, no nightly jobs, no lag.
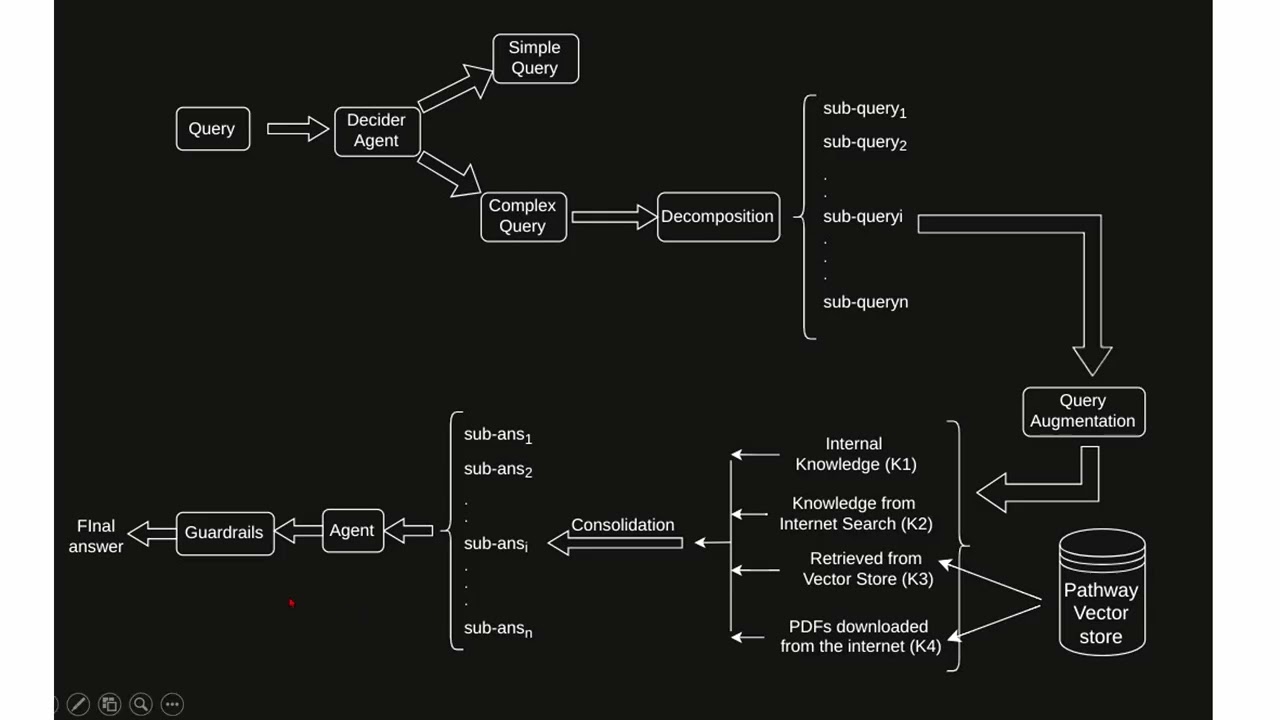
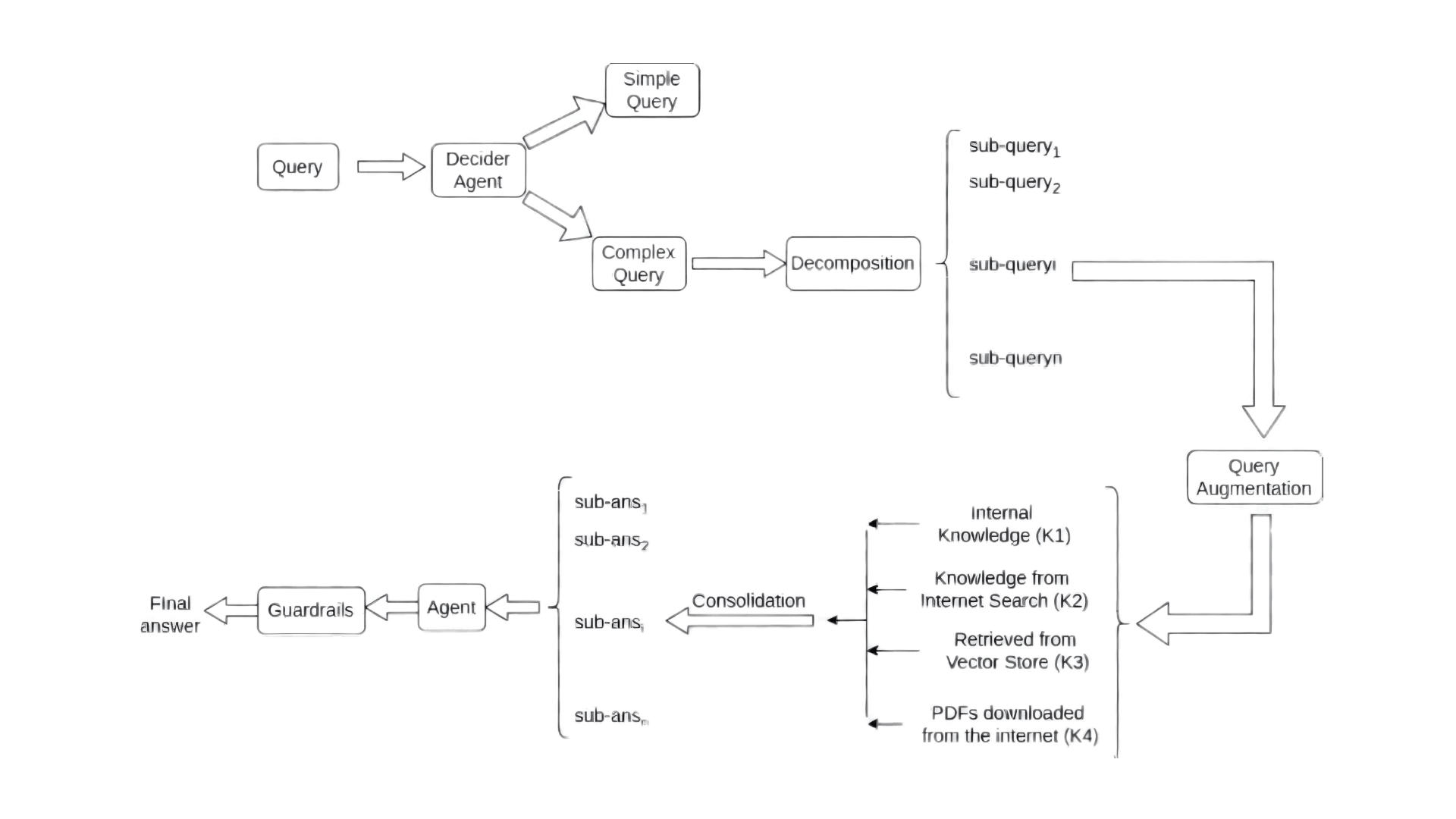
Under the hood, we pair this real-time substrate with an agentic workflow designed for finance. A decider routes simple vs. complex asks; query augmentation expands finance shorthand (EPS, EBITDA, ROI, CAGR) to boost recall; multi-agent retrieval pulls from internal knowledge, the web, and downloaded finance PDFs; a consolidation step resolves conflicts across sources; and guardrails (PII/profanity checks) keep outputs safe and compliant. The result is a pipeline built to handle noisy PDFs and contradictory narratives without melting down.
Why you should care:
- Speed: jump from 200-page PDFs to answers (revenue, margins, guidance shifts) in a single query.
- Accuracy: conflict-aware consolidation reduces hallucinations and reconciles PRs vs. filings vs. transcripts.
- Coverage: works across annual reports, quarterly results, regulatory filings, and investor decks.
- Compliance: guardrails help you avoid leaking sensitive identifiers while staying audit-friendly.
What you’ll learn in this post
- How LiveAI™ keeps your RAG real-time without extra ETL.
- A finance-tuned, multi-agent architecture that understands jargon and multi-hop questions.
- A PDF-first ingestion pattern for balance sheets, income statements, cash-flows, and risk sections.
- Practical prompts, schemas, and deployment tips you can reuse for your own AI financial repo
Read on to see how to plug this into your workflow and ship insights your stakeholders can trust.
Financial Report Analysis with LiveAI™: A Multi-Agent Workflow with Response Resolution
Overview
The solution integrates advanced techniques to build a robust Retrieval-Augmented Generation (RAG) system:
- Decider agent: A decider classifies queries as either simple or complex. Simple queries, which rely on general knowledge or straightforward logic, are answered directly using the agent's internal knowledge, while complex queries requiring tools, data processing, or sub-questions are forwarded for further processing (see Figure 1).
- Query Augmentation: Detects jargon using a dynamic repository and enriches queries via a Large Language Model(LLM) to enhance retrieval accuracy.
- Pathway Integration: Utilizes Pathway APIs with Google Drive for scalable storage and automated indexing, supporting diverse data formats (e.g., PDFs, JSON).
- Multi-Agent Retrieval: Implements tools for direct answers, internal knowledge retrieval, web search, and domain-specific retrieval (e.g., financial data in PDFs).
- Conflict Resolution: Addresses conflicting information through iterative knowledge consolidation, conflict flagging, and generating reliable answers. Guardrails ensure ethical and secure outputs.
- User Interface: Combines Flask and React for a responsive and low-latency interface. This system ensures accurate, scalable, and context-aware retrieval and response generation.
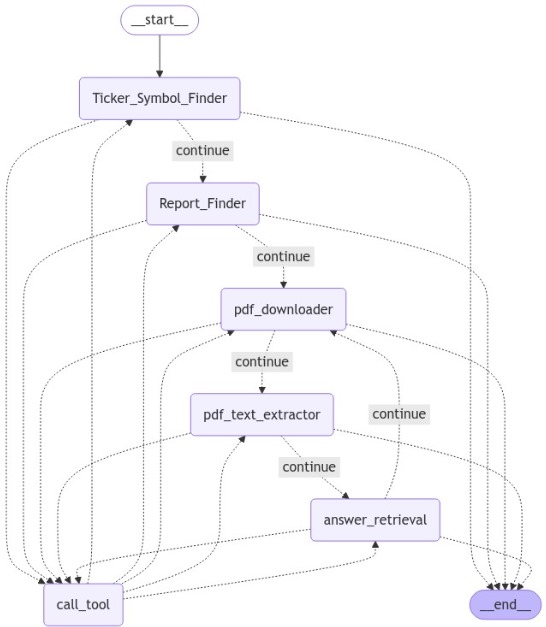
System Demonstration: AI Financial Report Analysis
Code Repository - Complete Setup & Usage Guide
Query Decomposition and Augmentation
As new information is continually generated, user queries may include terms that carry different meanings depending on the context. Specifically, queries containing jargon accompanied by some context can be reinterpreted to provide more precise or alternative meanings using an LLM.
To address this use case, we focus on identifying jargon within the user's query. This is achieved using a semi-dynamic predefined store that serves as a repository for querying and managing jargon. New jargon encountered can be added to this store, ensuring its adaptability over time.
Once jargon is identified, the entire query is passed to the LLM, which generates an augmented version enriched with additional contextual information. This process ensures that the retriever aligns more closely with the user's intent, enhancing the relevance and accuracy of the retrieved information.
Integration with Pathway
The integration of Pathway offers a flexible and versatile approach, leveraging its diverse range of APIs. For data storage, we chose Google Drive, primarily due to its adaptability and compatibility with our design requirements. This choice also aligns with our scalable approach, enabling seamless support for various data formats, such as PDF, JSON, and SQL, with minimal effort.
Moreover, the framework's existing vector store architecture facilitates efficient data management. Its reactivity allows for easy and rapid additions, deletions, and updates, all of which are automatically incorporated into the system. Additionally, the framework's automated indexing capabilities further enhance the efficiency of our workflow, ensuring smooth and reliable data retrieval.
Multi-Agent Retrieval for Financial Report Analysis
Initially, we adopted a divide-and-regain strategy for our approach. However, we discovered that this method resulted in incomplete integration of conflicting knowledge. To address this limitation, we explored an alternative approach, as outlined below.
- Internal Knowledge agent: This works when the LLM possesses the information in its internal knowledge to answer the query which has been asked.
- Retrieval Agent: We have set up the "retrieve_documents" tool to search for relevant documents from the internal knowledge base.
- Web Search Agent: Here, we used the "tavily_tool" to perform a web search which effectively finds critical and relevant information related to our context, if real time financial information like stock prices etc. is required then "google_search_tool" shall also be used.
- Downloaded Documents agent: This implementation introduces a novel approach focused on extracting domain-specific knowledge, specifically targeting the finance sector. It enables the retrieval and processing of PDF documents, as financial information from major companies is often stored in this format. Future scalability plans include integrating a web-list, allowing the system to expand and gather domain-specific knowledge from a variety of fields beyond finance depending upon the use case.
- Consolidation agent: The Consolidation Agent collects information retrieved by the above agents, it then processes this data using an iterative consolidation tool to reconcile discrepancies and ensure consistency. The final output consists of the most reliable and coherent information, providing a comprehensive and accurate response.
Resolving Conflicting Responses
Once we get data from retrieval, we proceed to resolving issues arising from unreliable external sources through the integration of internal and external information through a series of steps.
- Adaptive Internal Knowledge Generation: The LLM generates passages based on its internal knowledge relevant to the given query, this acts as a data source going forward.
- Iterative Source-Aware Knowledge Consolidation: Next, we consolidate and refine the knowledge pool by selectively iterating through the generated and retrieved passages obtained from various sources.
- Identifying Conflicts: Passages which present conflicting information are separated and flagged as conflicting. This allows the model to evaluate the reliability of each conflicting source, preventing the combination of contradictory data. We have also found the answers with a confidence which can be even converted to a score later on in future work.
- Answer Finalization: Finally, we generate the final, reliable answer from the consolidated knowledge pool. This is done through the consideration of multiple perspectives to provide a well-rounded response.
- Guardrails: It has been noticed that sometimes the answer provided could contain information which is private/controversial. To prevent the generation of answers like this, we have implemented rail checks which ensured that such information is not included in the final response.
Integration with User Interface
For the development of our solution, we integrated Flask with React, ensuring a seamless and efficient design. Special attention was given to minimizing latency to provide a smooth user experience. The resulting user interface features a dynamic and intuitive design, making it easy to navigate and interact with our solution.
Novelty and Specific Use-Cases
Use Cases
Our solution is specifically designed for the finance domain, addressing limitations in current solutions that typically rely on scraping raw text from web pages. These existing methods often miss out on structured and essential data found in documents like PDFs. Our approach leverages a multi-agent system that not only searches for and downloads PDF documents, such as financial report press releases, but also extracts meaningful insights from them, like tables, graphs, and key financial metrics.
For example, while many financial websites may display earnings reports or balance sheets in a web page's text, the most accurate and comprehensive information often resides in downloadable PDF documents. Our system efficiently retrieves these documents, extracts critical data such as revenue, profits, and year-over-year growth rates, and processes them to provide a more structured and insightful analysis. By focusing on these high-value sources, we ensure that the information we deliver is both up-to-date and relevant, providing a more accurate picture of a company's financial health.
Jargon Expansion in Question Augmentation
Our approach introduces jargon expansion as a key enhancement to the Agentic RAG framework, ensuring that domain-specific abbreviations and technical terms are fully understood by the retrieval system. This improves the accuracy and relevance of retrieved information, especially in domains with complex jargon. Our method stands out by automatically expanding jargon within financial queries, enabling the system to better interpret terms like EPS (Earnings Per Share) or P/E ratio (Price-to-Earnings Ratio). This ensures precise document retrieval and improves query understanding without requiring manual intervention.
Use Cases in Finance
Stock Market Analysis: Financial queries that contain shorthand terms like EPS or P/E ratio are expanded to their full forms, ensuring accurate retrieval of relevant stock market data. Example: "What's the impact of EPS on stock performance?" becomes "What's the impact of Earnings Per Share (EPS) on stock performance?"
Investment Strategy: Terms like ROI (Return on Investment) or CAGR (Compound Annual Growth Rate) are expanded to help retrieve more specific and relevant investment insights. Example: "What's the effect of ROI on business growth?" becomes "What's the effect of Return on Investment (ROI) on business growth?"
Financial Reports: Queries involving financial statements or metrics are enhanced by expanding abbreviations like EBITDA (Earnings Before Interest, Taxes, Depreciation, and Amortization), ensuring proper understanding in reports. Example: "How does EBITDA affect company valuation?" becomes "How does Earnings Before Interest, Taxes, Depreciation, and Amortization (EBITDA) affect company valuation?"
Advantage
- This approach allows for easy domain-specific tuning without retraining models. By expanding jargon, we can fine-tune the system for the finance domain, ensuring efficient and precise query handling for financial analysis, investment strategies, and reporting.
Question decomposition
In finance, users often ask questions that require insights from multiple angles. Query decomposition breaks down these complex questions into manageable sub-queries, enabling the system to retrieve and combine information from various sources for a more comprehensive answer.
Example of Query Decomposition
Original Query: "Who is the CEO of the company that made the biggest loss in Q3 2024?" This query requires two distinct pieces of information: The company that made the biggest loss. The CEO of that company.
To break it down:
Sub-query 1: "Which company made the biggest loss in Q3 2024?"
Sub-query 2: "Who is the CEO of Company Name?"
By splitting the query, the system can pull the relevant details from separate documents---one about Q3 2024 financial results and another listing company executives---and then combine them to generate the final answer.
Process in Action:
Sub-query 1 Retrieval: Search for data on financial losses in Q3 2024 and find that Company XYZ reported the biggest loss.
Sub-query 2 Retrieval: Search for information on Company XYZ and find that the CEO is Jane Doe.
Final Answer: "The CEO of the company that made the biggest loss in Q3 2024, Company XYZ, is Jane Doe."
Financial Data from PDFs: A Novel Approach to Domain-Specific Retrieval
A standout feature of our multi-agent retrieval system is its ability to extract and process financial data from PDFs. In industries like finance, crucial information is often stored in PDF format, especially when companies release detailed financial reports, earnings statements, regulatory filings, and annual reports. Traditional information retrieval systems might struggle to access and interpret this rich, domain-specific content. Our solution addresses this challenge by integrating a dedicated PDF extraction tool tailored specifically for financial data. This tool not only locates and retrieves PDF documents containing valuable financial knowledge but also processes them effectively to extract key insights such as:
- Balance Sheets: Extracting financial data related to assets, liabilities, and equity to understand a company's financial health.
- Income Statements: Identifying revenue, expenses, and profit margins to assess operational performance.
- Cash Flow Statements: Capturing cash inflows and outflows, which is crucial for understanding liquidity and financial stability.
- Investment Insights: Parsing through investment-related documents, including corporate announcements and projections, that influence market behavior.
he financial PDF extraction tool operates seamlessly alongside other retrieval agents, ensuring that when users ask finance-related questions, the system can efficiently retrieve and process the most relevant, up-to-date financial information directly from these sources. For example, if a user asks, "What were the revenue trends of XYZ Corp in the Q4 report for 2024?", the system would locate the latest PDF document containing XYZ Corp's financial report, extract the revenue data from the income statement, and present the insights directly in response.
Filtering Out Relevant Information
A key challenge in Retrieval-Augmented Generation (RAG) systems is ensuring the reliability and relevance of the information pulled from both internal and external sources. To address this, our approach integrates a series of systematic steps designed to enhance the performance of RAG while filtering out unreliable or conflicting data. This novel methodology ensures that the generated responses are both accurate and comprehensive.
Our information filtering process includes the following steps:
- Adaptive Internal Knowledge Generation: Initially, the LLM generates relevant passages from its internal knowledge base. These passages are generated based on the specific context of the query, ensuring that the information provided aligns with the user's needs and the domain of the query.
- Iterative Source-Aware Knowledge Consolidation: Once the internal knowledge is generated, the system consolidates and refines the knowledge pool by iterating through both generated and retrieved passages. This step ensures that the most relevant and high-quality information is retained while less relevant data is filtered out.
- Identifying Conflicts: In the case where different passages provide conflicting information (such as contradictory facts or varying perspectives), these conflicting passages are flagged and separated. This step is crucial in preventing the combination of contradictory data in the final answer. The system evaluates the reliability of each conflicting source, ensuring that only the most trustworthy and consistent information contributes to the final response.
- Answer Finalization: Finally, the system generates the most reliable answer by drawing from the consolidated knowledge pool. The final response is shaped by considering multiple perspectives and integrating the best sources of information, ensuring that the result is both balanced and well-rounded.
Advantages
This filtering process significantly improves the quality and accuracy of the generated answers. By systematically filtering and consolidating information from various sources, we ensure that the final response reflects the most reliable and relevant data. Moreover, by flagging conflicting information and evaluating its reliability, our system reduces the risk of propagating errors and inconsistencies, which is especially important in domains like finance, where accurate, dependable information is paramount. Through this innovative filtering mechanism, we not only enhance the performance of RAG but also ensure that the responses are trustworthy, relevant, and comprehensive, providing users with a robust tool for answering complex queries.
| Dataset | Norm Rouge-1 | Norm Rouge-2 | Embed Rouge-1 | Embed Rouge-2 | ||||
|---|---|---|---|---|---|---|---|---|
| Vanilla | R2R | Vanilla | R2R | Vanilla | R2R | Vanilla | R2R | |
| FinanceBench | 0.0769 | 0.1334 | 0.0231 | 0.0426 | 0.0908 | 0.1663 | 0.0458 | 0.0899 |
Table 1: Rouge
| Dataset | Meteor | |
|---|---|---|
| Vanilla | R2R | |
| FinanceBench | 0.1069 | 0.1548 |
Table 2: Meteor Scores
Guardrails
To ensure user safety and maintain ethical standards, we have implemented robust guardrails within the multi-agent RAG system. These guardrails are designed to identify and redact sensitive information such as credit card numbers, Aadhaar numbers, PAN, CVV, GSTIN, and IFSC codes using a combination of Presidio Analyzer and Presidio Anonymizer libraries. Additionally, we utilize Better Profanity to detect and censor offensive language, replacing inappropriate content with redaction markers. Custom rules tailored for India-specific identifiers enhance the system's ability to manage local regulatory requirements. By integrating these components, the system ensures that all outputs are sanitized, free from harmful or private information, and safe for user consumption. This critical feature reinforces the reliability and trustworthiness of the RAG system across diverse use cases.
Evaluation of the Approach for Financial Report Analysis
The evaluation of our Retrieval-Augmented Generation (RAG) system focuses on assessing the effectiveness of the retrieval component, which plays a crucial role in selecting and ranking relevant documents or data. To gauge how well the retrieval phase operates, we measure its performance using several standard metrics, which allow us to monitor the precision and overall quality of our pipeline. In particular, we use metrics such as ROUGE scores and METEOR, calculated for different values of k, to provide insights into the effectiveness of our retrieval mechanism.
ROUGE Score
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a widely-used metric for evaluating automatic summarization and machine translation systems. It combines precision, recall, and F1-score by considering k-grams (subsequences of k words). For this evaluation, we have chosen ROUGE-1 and ROUGE-2 with values of k set to 1 and 2, respectively. The choice of these values comes from the observation that larger values of k often result in difficulty finding exact matching n-grams in scenarios where the answer can be augmented by the language model (LLM). Thus, using k = 1 and k = 2 allows for a reasonable balance between capturing meaningful content while acknowledging the challenges posed by larger k-grams.
METEOR Score
METEOR (Metric for Evaluation of Translation with Explicit ORdering) is another automatic evaluation metric, originally developed for machine translation. It evaluates translation quality by comparing unigrams between machine-produced and human-produced reference translations. Unigrams are matched based on their surface forms, stemmed forms, and meanings. METEOR then calculates a score by combining unigram precision, unigram recall, and a measure of fragmentation that captures how well-ordered the matched words are relative to the reference. This ordering is particularly valuable in evaluating sentence accuracy and fluency.
Datasets
Given that our solution is primarily focused on financial tasks, we selected datasets that are relevant to the domain of finance while also choosing general datasets to maintain comparability with other solutions. The datasets used for this evaluation are HOTPOTQA, TriviaQA, and FinanceBench (a dataset specifically focused on financial terms). These datasets allow us to assess the system's performance in both general knowledge and domain-specific contexts. For the evaluation, we present results from our RAG implementation on the FinanceBench dataset, compared to the baseline Vanilla RAG.
Evaluation Results
The evaluation metrics used include both the ROUGE and METEOR scores, as shown in the Tables 1 and 2. Our results indicate a significant improvement in performance with our approach compared to Vanilla RAG.
- ROUGE-1: 73.4% improvement.
- ROUGE-2: 84.7% improvement.
- Embed ROUGE-1: 83.0% improvement.
- Embed ROUGE-2: 96.4% improvement.
- METEOR: 44.8% improvement.
Conclusion
This solution built using the Pathway Live Data Framework addresses significant limitations in traditional RAG systems by introducing a multi-agent design capable of resolving conflicting responses and refining query decomposition. Its integration with Pathway and the ability to handle diverse data formats ensure scalability and adaptability. Focused on the finance domain, it demonstrates practical utility through its capacity to retrieve and analyze structured data, such as financial PDFs, with precision. The approach’s novelty lies in its modular design, conflict resolution mechanisms, and ability to expand into other domains. Future scalability through unified embeddings and Swanson linking shows promise for broader applications, making this solution a notable advancement in intelligent query handling and domain-specific retrieval systems.
If you are interested in diving deeper into the topic, here are some good references to get started with Pathway:
- Pathway Live Data Framework Developer Documentation
- Pathway Live Data Framework's Ready-to-run App Templates
- End-to-end Real-time RAG app with Pathway Live Data Framework Live Data Framework
- Discord Community
References
Authors

Pathway Live Data Framework Community
Multiple authors