Retrieval Augmented Generation: Beginner’s Guide to RAG Apps

 Mudit Srivastava
Mudit SrivastavaRetrieval Augmented Generation: Beginner’s Guide to RAG Apps
Generative Artificial Intelligence (Gen AI) has graduated from tech jargon to C-suite strategy; a recent McKinsey report indicates that nearly a quarter of top executives are personally using gen AI tools.
Large Language Models (LLMs) are the workhorses behind this evolution, capable of understanding and generating various forms of content. Yet, they're not flawless - issues like generating inaccurate information, inability to verify data sources, and relying on stale data stand out. These challenges are significant for most enterprises as they require real-time, accurate, and traceable data—factors often cited as top concerns.
Retrieval Augmented Generation (RAG) offers a transformative solution to these issues. It elevates the capabilities of LLMs, making them relevant, reliable, and up-to-date. In this article, we'll demystify RAG, delve into its role in augmenting LLMs for better accuracy, and guide you through the working of your own RAG-powered application.
As you read through this article, you'll:
- Understand how a Retrieval Augmented Generation (RAG) or RAG App works, including its real-time integration with Large Language Models.
- Dive into the cost and efficiency aspects of RAG to get a better understanding of its advantages.
- Discover how RAG contributes to robust data governance and compliance.
- Gain the insights needed to assess if RAG is the right fit for your organization's Gen AI and data strategy.
What is Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is an AI framework that enhances the performance of Large Language Models (LLMs) by integrating them with external knowledge sources. This enables the LLM to generate responses that are not only contextually accurate but also updated with real-time information.
Need for Retrieval Augmented Generation (RAG) LLMs
Retrieval-Augmented Generation (RAG) offers an efficient way to adapt and customize Large Language Models (LLMs) without the complexities of fine-tuning or limitations of prompt engineering. Let’s understand how.
Retrieval Augmented Generation vs Fine Tuning LLM
In fine-tuning, a pre-trained language model like GPT-3.5 Turbo or Llama-2 is retrained on a smaller, specialized, labeled dataset. While you're not starting from scratch, retraining and deploying a model is expensive, and preparing this new data presents its own set of challenges. Subject-matter experts are needed to label the data correctly. Additionally, the model can start making more errors if the data changes or isn't updated frequently. This makes fine-tuning a resource-intensive and repetitive task. Imagine having to do this every time your company releases a new product, just to ensure your support teams do not receive outdated information from your Gen AI model.
In terms of cost-efficiency, using vector embeddings, a core component of the Retrieval-Augmented Generation (RAG) model, is about 80 times less expensive than using OpenAI's commonly used fine-tuning API. While these terms may seem technical, the real takeaway is efficiency; RAG offers significant advantages in both process complexity and operational cost.
Retrieval Augmented Generation vs Prompt Engineering
Acknowledging the resource-heavy nature of fine-tuning, it's worth examining the limitations of directly copy-pasting data via prompts to apps such as ChatGPT. Enterprises and LLMs, in particular, face the dual challenges of data privacy and technical constraints. Privacy is a concern for any company that can't afford to expose sensitive documents.
Besides privacy, there's a technical constraint: the “token limit.” This restricts the volume of data you can feed into an LLM for a given query or prompt, causing errors when you exceed this threshold.
The response below on a ChatGPT is a classic example.

RAG LLM adeptly navigates these challenges by retrieving most pertinent information, all within the model's token limit, from a set of data sources.
Examples of these data sources include your existing databases such as PostgreSQL, unstructured PDFs, Rest APIs, or Kafka topics. This targeted retrieval not only enhances the model's accuracy but also maintains the relevance and currency of its responses.
Vector Embeddings and Vector Indexes: Building Block of RAG Apps and LLMs
Before delving into how RAG operates, it's vital to familiarize ourselves with two foundational pillars: vector embeddings and vector indexes.
Vector Embeddings serve as numerical fingerprints for various data types, be it words or more intricate "objects." To understand this, picture a 3-D color space, where similar colors are close together. For example, Kelly Green is represented by (76,187,23) and similar colors are placed near to it. This proximity enables easy, objective comparisons.
Source: Huggingface / jphwang / colorful vectors
Like this, vector embeddings group similar data points as vectors in a multi-dimensional space.
OpenAI's text-embedding-ada-002 is commonly used for generating efficient vector embeddings from various types of structured and unstructured data. These are then stored in vector indexes, specialized data structures engineered to ensure rapid and relevant data access using these embeddings.
It's worth noting that applications like recommender systems also use vector indexes and often manage these using vector databases in production settings. However, this isn't required for RAG-based applications. Specialized libraries designed for RAG applications, have the capability to generate and store their own vector indexes within the program memory.
How RAG Works with Real-time or Static Data Sources
Understanding how Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) requires a walk-through of the underlying processes. The functioning can be broadly categorized into several key components and steps:
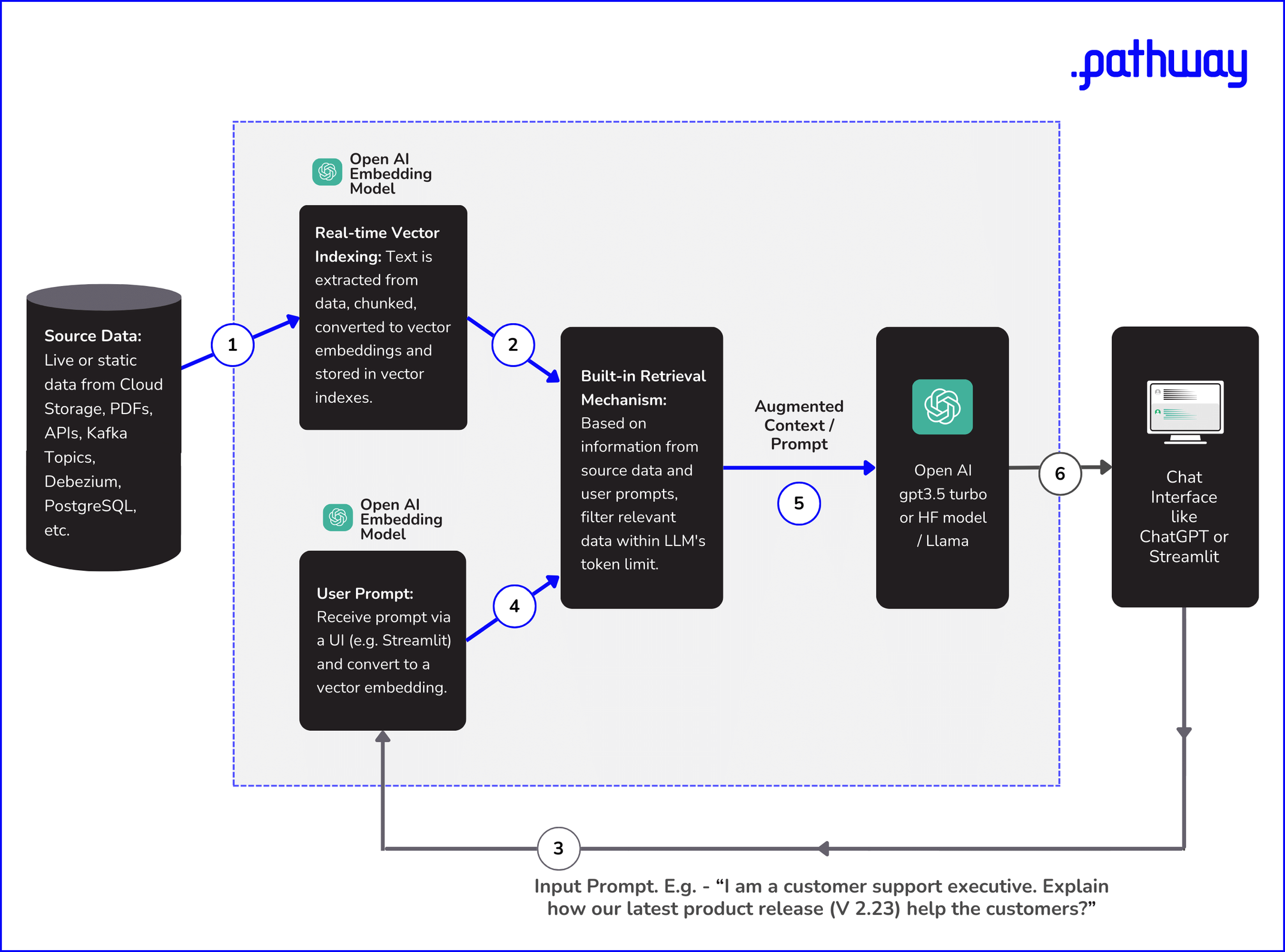
- Source Data
- Your initial data can exist in multiple formats and locations—be it cloud storage, Git repositories, PDF files, or databases like PostgreSQL. The preliminary step involves linking these diverse data sources through built-in connectors.
- Real-time Vector Indexing
- Text data, irrespective of its original format, is first extracted and segmented into manageable chunks. These segments are then transformed into vector embeddings using specialized models like OpenAI's text-embedding-ada-002. The resultant vectors are indexed in real-time, enabling rapid information retrieval.
- Input Prompt
- To accurately capture user intent, the input prompt provided by the user is also transformed to vector embeddings. This transformation again utilizes an embedding model, ensuring that the user query is compatible with the indexed data for efficient context retrieval.
- Context Retrieval Mechanism
- Employing algorithms like Locality-Sensitive Hashing (LSH) or Hierarchical Navigable Small World (HNSW), a similarity search is executed on the vector embeddings of both the user's prompt and the indexed data. This approach ensures the retrieval of the most pertinent context, adhering to token limitations.
- Content Generation
- Based on the augmented context provided by the context retrieval algorithm, foundational LLM models like GPT-3.5 or Llama-2 generate a response using Transformer architecture-based techniques such as self-attention or grouped-query attention.
- Output
- The generated response from models such as GPT-3.5 turbo is rendered for user interaction through a UI like Streamlit or a ChatGPT.
While the process may seem intricate at first glance, specialized libraries like Pathway Live Data Framework LLM App can greatly simplify it. This library comes with built-in data connectors, generates its own vector indexes, and incorporates an efficient retrieval mechanism based on widely-used algorithms like LSH. For most use cases, the LLM App can be used to productionize LLM Apps without the hassle of using vector databases. This feature allows for varied deployment scenarios while it serves as a one-stop solution for effortless RAG implementation .
For instance, there's an open-source RAG application that leverages the Amazon Prices API and a CSV file to provide a Streamlit-based chat interface. This interface fetches relevant discount information and communicates it in natural language.
The technology opens up exciting opportunities when paired with various real-time or static data sources, such as internal wikis, CSV files, JSONLines, PDFs, APIs, and streaming platforms like Kafka, Debezium, and Redpanda.
Benefits of Implementing Real-time RAG in LLMs
Implementing RAG through such architecture in LLMs offers several advantages:
- Current, Reliable Facts based on Real-time updates: The model has real-time access to the most current and accurate data, reducing the chance of providing outdated or incorrect information.
- Data Governance and Security:
- Reduced Hallucination: Real-time vector indexing allows for accurate data retrieval, lowering the risk of the LLM generating incorrect or 'hallucinated' responses.
- PII and Access Control: Advanced data governance mechanisms ensure that Personally Identifiable Information (PII) is processed appropriately. The system can also address enterprise hierarchy-related issues, restricting access to sensitive or restricted data. For instance, if an employee queries about their manager's salary increment, the system will recognize the limitations and withhold that information.
- Source Transparency and Trust: Knowing the origin of the information improves the reliability and trustworthiness of the LLM's responses.
- Compliance and Regulation Readiness:
- Security Risks and Proprietary Data: Much like traditional IT security governance, protections can be extended to cover specific generative AI risks. This includes automating compliance checks or sending reminders when sensitive data is accessed.
- Regulatory Tracking: With the evolving landscape of regulations around generative AI, such as the European Union’s AI Act, it's critical to be prepared for new compliance standards. This ensures that your LLM is adaptable to future regulations, possibly requiring the 'untraining' of models using regulated data.
- Efficient Customization: Implementing RAG eliminates the need for fine-tuning, extra databases, or additional computational power, thereby making customization efficient and cost-effective.
Get started with Pathway Live Data Framework Realtime Document AI pipelines with our step-by-step guide, from setup to live document sync. Explore built-in features like Similarity Search, Vector Index, and more!
Frequently Asked Questions around Retrieval Augmented Generation
- Can RAG LLM App work on unstructured data? Yes, RAG is versatile enough to process a wide array of data types, including but not limited to relational databases, free-form text repositories, PDFs, live data feeds from the internet, internal wikis, APIs, transcribed audio, Kafka, Debezium, Redpanda, and more.
- Is using vector databases mandatory for RAG? Short answer, no. While many libraries, including LLM App, are compatible with established vector databases such as Pinecone and Weaviate, they are not a requirement for many use cases even in production. Utilizing a separate, dedicated database solely for managing vector indexes is not an efficient approach. LLM App, for instance, has the capability to generate its own vector index. Additionally, mainstream databases like PostgreSQL are increasingly incorporating built-in support for vector indexing via extensions like PG Vector.
- Is a Separate Real-Time Processing Framework Needed for Streaming Data? No. LLM App leverages the Pathway Live Data Framework, a high-performance (benchmarks), open-source real-time processing engine capable of handling streaming and batch processing in a unified framework.
- Can Transfer Learning from Large Language Models Be Applied in RAG? Certainly, the principle of transfer learning is integral to RAG. Large language models like GPT-3.5 or Llama-2 can be combined with the retrieval mechanism in RAG to produce contextually relevant and accurate responses. This synergy leverages the language model's extensive training on diverse data to enhance the retrieval and generation capabilities of RAG.
- Is there a resource for learning more about Retrieval Augmented Generation and Large Language Models? You can explore a free beginner-level coursework on these topics at IIT Bombay’s AI Community website. Just visit either of the two links below:






