Multi Agent RAG with Interleaved Retrieval and Reasoning for Long Docs

 Pathway Live Data Framework Community
Pathway Live Data Framework CommunityIntroduction
In the ever-evolving landscape of artificial intelligence, the intersection of AI and enterprise applications has seen significant advancements. However, deploying AI systems that are not only intelligent but also adaptive remains a challenge, especially in sectors like finance and law where precision and up-to-date insights are paramount. Traditional generative LLM often fall short in these environments due to their static nature, outdated knowledge, and lack of real-time decision-making capabilities.
Here is where Retrieval-Augmented Generation (RAG) systems come into play. These systems have emerged as a promising solution, but they too have their limitations. In this blog, we’ll explore how we’ve developed a Dynamic Agentic RAG System specifically designed for long, intricate legal and financial documents. This system not only addresses the shortcomings of traditional RAG systems but also introduces novel approaches to retrieval, reasoning, and memory management.
Why RAG? The Need for Dynamic Retrieval and Reasoning
The Limitations of Traditional LLM
Imagine asking ChatGPT about a niche financial law that was recently passed. The LLM wouldn’t know about it because it was trained before the law existed. Pretraining or finetuning the LLM is an expensive option. This is where RAG comes into play. Instead of relying solely on pre-trained data, RAG systems retrieve relevant information from external databases or documents and use Large Language Models (LLMs) to generate contextually accurate responses.
Why RAG is Essential
- LLM Can’t Store Everything: The sheer volume of data in legal and financial domains makes it impossible for LLM to store all relevant information in their memory
- Constant Data Creation: New data is continuously being generated, and RAG ensures that the AI can access the most up-to-date information
- Factual and Grounded Responses: By retrieving information from external sources, RAG systems provide responses that are more factual and grounded in reality
The Problem with Traditional RAG Systems
Traditional RAG systems often retrieve information indiscriminately, failing to adapt dynamically based on query complexity. This inefficiency is particularly problematic in financial and legal contexts, where data relevancy is critical. Moreover, these systems treat retrieval and reasoning as separate entities, first performing context retrieval and then providing the context as a prompt to the LLM for reasoning. This approach falls short when dealing with complex multi-hop queries that require interleaved retrieval and reasoning.
Introducing the Dynamic Agentic RAG System
A Multi-Agent Approach
To address these challenges, we adopted a multi-agent approach. In this system, different AI agents specialize in distinct tasks, working together to achieve a common goal. This approach introduces specialization, allowing each agent to focus on a specific aspect of the retrieval and reasoning process. Check out the demonstration below for a description of the entire agentic workflow, and the implementation of the same:
Overview Video: Multi-Agent RAG in Action

Code Repository: Setup & Usage Guide
What Are Agents?
Agents are autonomous systems that analyze and act based on their environment to achieve specific goals. They can retrieve, process, and synthesize information, making decisions dynamically rather than following rigid rules. In our system, we have multiple agents, each specializing in tasks like retrieval, reasoning, and tool handling.
The Role of Tools
In addition to retrieval and reasoning, our system incorporates tools—modular add-ons that enhance the system’s capabilities. Tools can include calculators, web search modules, chart generators, and more. These tools not only increase the accuracy of responses but also reduce human intervention, allowing the AI to surpass its inherent limitations.
The Pathway Live Data Framework: The Backbone of Our System
For such an intelligent system to operate at scale, it requires an underlying infrastructure capable of handling massive data flows and real-time computations. The Pathway Live Data Framework serves as the backbone of our system, offering:
- High-speed data processing to ensure minimal latency
- Real-time retrieval for dynamic knowledge updates
- Multi-modal data handling to process various types of data
- Simplified deployment with Docker and Kubernetes
With the Pathway Live Data Framework, our Dynamic RAG system can operate seamlessly across vast datasets, continuously learning and adapting to new information without compromising speed or accuracy.
System Architecture and Workflow
Overview of the Workflow
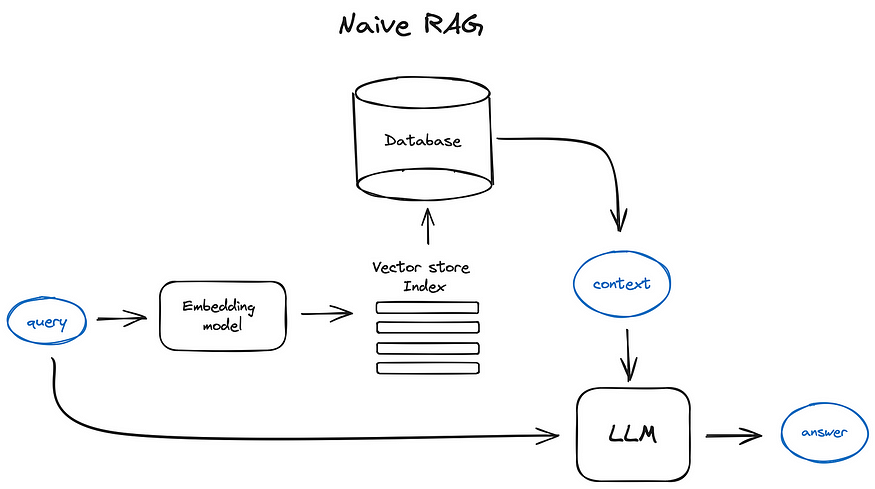
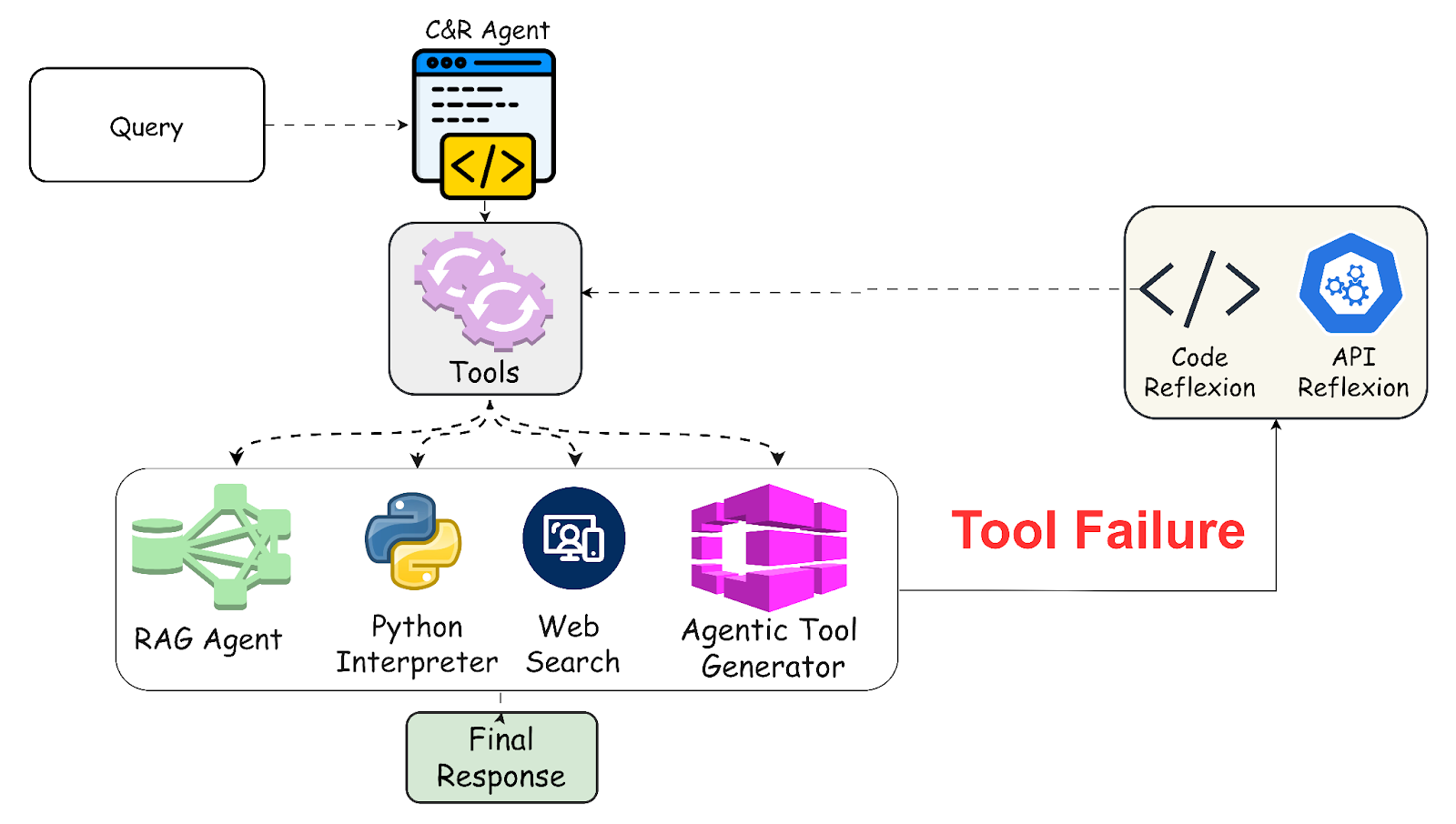
The workflow of our Dynamic Agentic RAG System begins with the user providing a query (Q), a set of documents (D), and a set of tools (T). The system then follows these steps:
- Supervisor Agent Activation: The Supervisor Agent activates the Code & Reasoning (C&R) Agent, which can interact with tools and the RAG Agent
- Document Indexing: The RAG Agent builds a document index for D using the framework’s VectorStore Server
- Page-Level Retrieval: The system uses Jina Embeddings to perform page-level retrieval, extracting the top-k most relevant pages for Q
- Hierarchical Indexing: The retrieved pages are chunked and indexed using RAPTOR, forming a hierarchical structure over the summary of the chunks
- Interleaved Retrieval and Reasoning: The RAG Agent uses an interleaving approach to iterate between reasoning and retrieval, performing multi-hop contextual reasoning
- Tool-Specific Tasks: The C&R Agent utilizes tools for any tool-specific tasks based on the RAG Agent’s response and user query
- Response Consolidation: The Supervisor Agent consolidates the outputs and returns the final response to the user
RAG Agent
Two-Stage Retrieval Pipeline
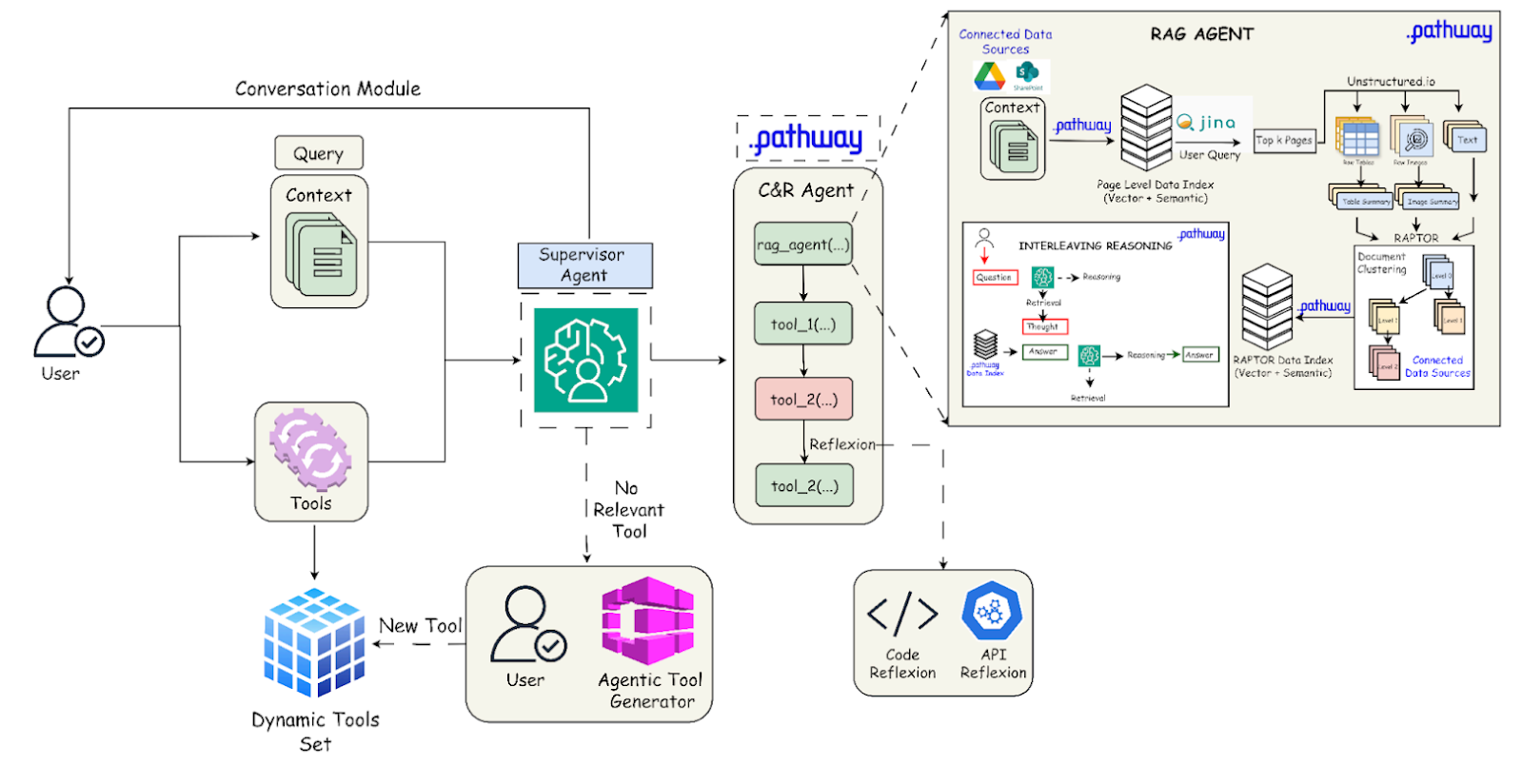
Retrieving information from large documents, such as financial and legal reports, is challenging due to their inherent hierarchies and diverse entities like tables, charts, and images. To address this, we designed a custom two-stage retrieval pipeline:
1. Page-Level Retrieval using Jina Embeddings
We use Jina Embeddings-v3, which is specifically trained for embedding generation in long-context document retrieval. These embeddings are optimized for semantic similarity in multi-page document searches, making them well-suited for page-level retrieval. Given a query ( Q ) and a document ( D ) with ( N ) pages, we generate query embeddings and page-level embeddings, indexing them in FAISS for efficient retrieval of the most relevant pages.
- Task-Specific LoRA: Jina employs a Mixture of Experts approach with five LoRA adapters
—retrieval.query,retrieval.passage,separation,classification, andtext-matching. Each adapter is optimized for different subtasks like query embedding, passage retrieval, and semantic similarity, ensuring high-quality embeddings - Alibi for Context Scaling: Alibi (Attention with Linear Biases) helps extend retrieval capabilities by enabling LLMs trained on short contexts to generalize effectively to longer documents
- Integration with the Pathway Live Data Framework: We have extended the
BaseEmbeddedclass to incorporate Jina Embeddings using API calls
2. Page-Level Preprocessing using Unstructured
Documents often contain tables and images that hold critical information. To capture this data, we use the Unstructured library to parse the retrieved pages into images, plain text, and tables, each with associated metadata (page number). The extracted data is then summarized by an LLM, recombined page-wise, and indexed.
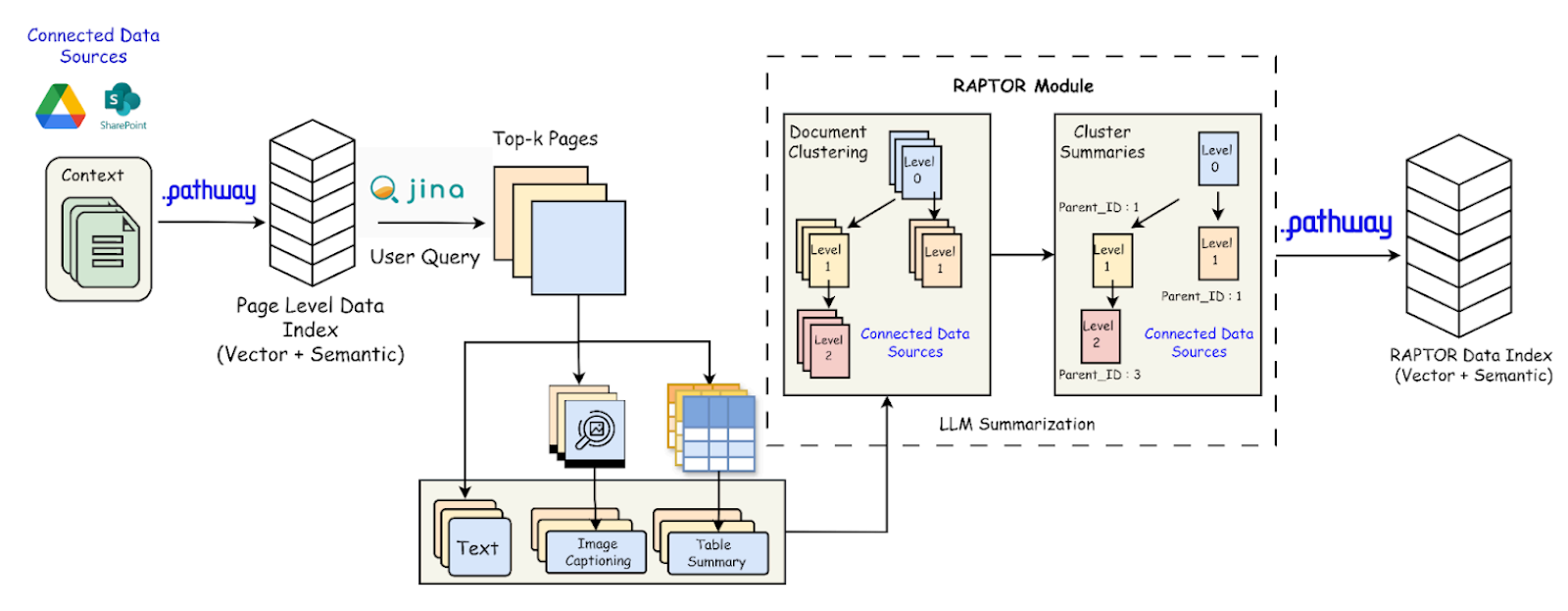
3. RAPTOR Index for Context Retrieval
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) is a bottom-up indexing approach that segments a document into text chunks, embeds them, clusters the embeddings, and summarizes each cluster using an LLM, forming a hierarchical tree structure. This method significantly reduces indexing time and enables structured retrieval at multiple levels.
Unlike traditional chunking methods, which divide text into fixed, independent segments without capturing semantic links, RAPTOR ensures that related chunks are meaningfully connected. Since information in documents is inherently interconnected, treating chunks as isolated units can lead to inefficient retrieval. RAPTOR addresses this by clustering semantically related chunks and structuring them hierarchically, allowing for context-aware retrieval.
- Integration with the Pathway Live Data Framework: Integration with the Pathway Live Data Framework requires metadata-level filtering to enable structured retrieval across hierarchical clusters
Fine-Tuning LLMs for Domain-Specific Tasks
During our experiments, we observed that a significant amount of API compute was being consumed in generating summaries for the RAPTOR module. This made the retrieval process costly and dependent on external APIs, creating scalability issues. To address this, we explored fine-tuning a Small Language Models to perform high-quality summarization locally.
While LLM like LLaMA 2-70B or 405B are powerful, they are often resource-intensive and impractical for cost-efficient inference. Instead, we fine-tuned LLaMA-7B using Parameter Efficient Fine-Tuning (PEFT) with LoRA adapters on an Nvidia A100. The objective was to generate high-quality summaries tailored to the CUAD dataset (Contract Understanding Dataset), which focuses on legal document understanding.
By fine-tuning a small Language Models, we achieved on-par performance with LLM while significantly reducing inference costs. In some cases, our locally deployed summarizer even outperformed API-based solutions, making it a more scalable and efficient alternative.
Interleaved Reasoning: Finding the Balance Between Retrieval and Synthesis
The Need for Interleaved Retrieval and Reasoning
Why do we need specialized reasoning techniques when RAG already exists? The answer lies in its limitations—traditional RAG lacks deduction and synthesis capabilities, which are crucial for handling complex legal and financial queries.
Multi-hop queries require multi-step retrieval and reasoning over intermediate retrieval steps—a challenge that basic retrieval-augmented generation (RAG) struggles to handle. Several reasoning paradigms have attempted to bridge this gap:
- Chain of Thought (CoT): Encourages step-by-step reasoning by breaking problems into logical steps. However, it follows a linear path, making it inefficient for multi-hop queries that require branching logic
- Tree of Thought (ToT): Extends CoT by exploring multiple reasoning paths, similar to a decision tree. While more flexible, ToT introduces redundancy by retrieving unnecessary information and increases token usage, especially when a reasoning path leads to a dead end
- Graph-Based Reasoning: We also explored graph-based reasoning with ROG (Reasoning on Graphs). While effective for structured knowledge graphs (KGs), it struggled with sparsity issues. Many LLM-driven KG generation techniques fail to capture implicit logical dependencies in financial and legal documents, limiting their reliability
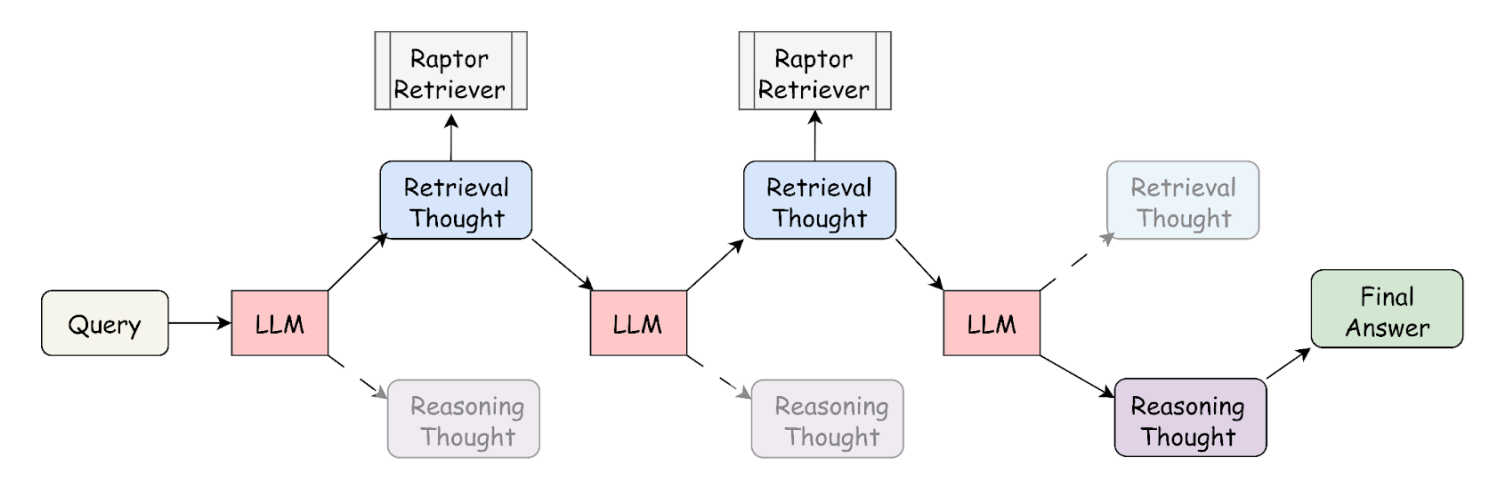
Interleaving RAG Reasoning
Traditional RAG systems separate retrieval and reasoning into distinct steps, leading to inefficiencies in complex multi-hop queries. Our system introduces a novel interleaving RAG reasoning approach, allowing LLMs to dynamically decide when to retrieve and when to reason. By integrating retrieval within the reasoning process, our approach eliminates redundant lookups, efficiently resolving multi-hop contextual queries.
How Interleaving Works
- Query Input: The process starts with a user query
- LLM Generates a Thought: The LLM produces an initial reasoning step
- Retrieval Step: The LLM retrieves relevant documents from an index based on the reasoning step
- LLM Refines the Thought: The retrieved information is processed, and the LLM generates further reasoning
- Interleaving Process: This cycle of retrieval and reasoning continues iteratively, refining the knowledge step by step
- Final Answer: After sufficient iterations, the LLM produces a final, well-informed answer
- Human in the Loop: Once the final answer is received, we ask the user for feedback; if the user is not satisfied, the entire procedure is repeated again
Why Interleaving is Useful
- Dynamic Refinement: It allows the LLM to dynamically refine its reasoning based on retrieved information
- Reduced Hallucination: By grounding responses in real-time knowledge retrieval, interleaving reduces the likelihood of the LLM generating incorrect or hallucinated responses
- Improved Performance: Interleaving significantly improves performance in multi-step reasoning tasks, especially for complex queries
Integration with the Pathway Live Data Framework
We extended the BaseRAGQuestionAnswerer class and integrated the interleaved retrieval and reasoning to develop the InterleavedRAGQuestionAnswerer class. This class can make use of any framework VectorStore client to perform retrieval. We also took the liberty of extending the current LLM services to include GroqChat Models by developing the GroqLLM Class.
Benchmarking and Results
To validate our approach, we benchmarked different retrieval techniques:
- Vanilla RAG and its variants performed poorly in both Mean Reciprocal Rank (MRR) and time
- RAPTOR + Jina Embeddings drastically outperformed traditional chunking, delivering high-precision retrieval without compromising speed
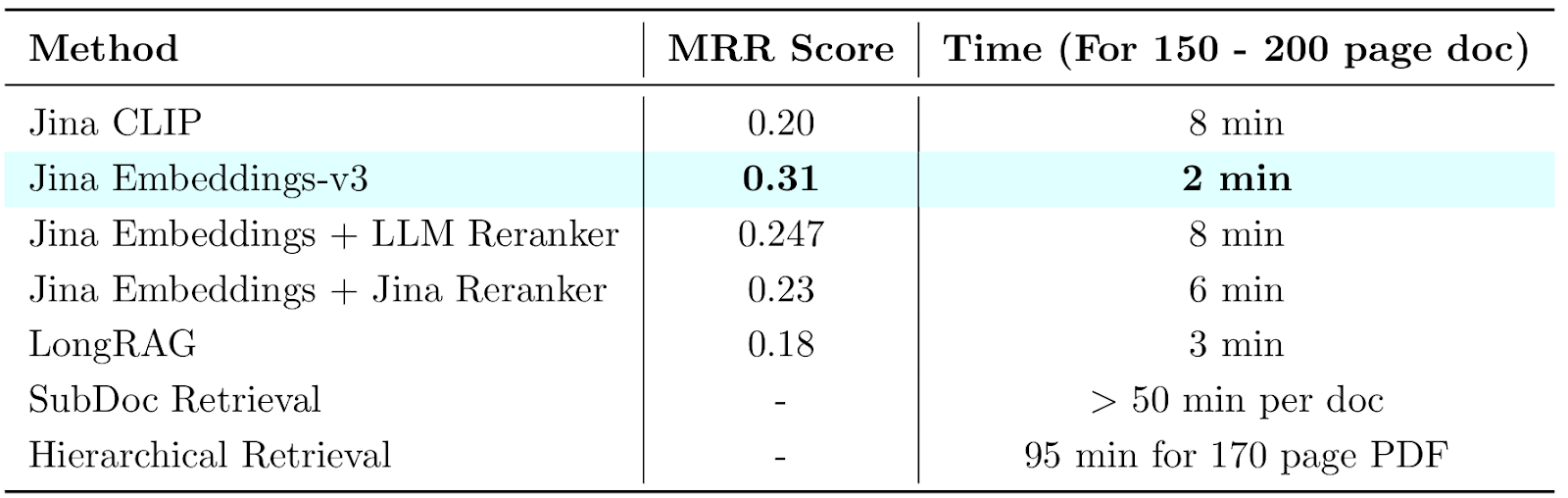
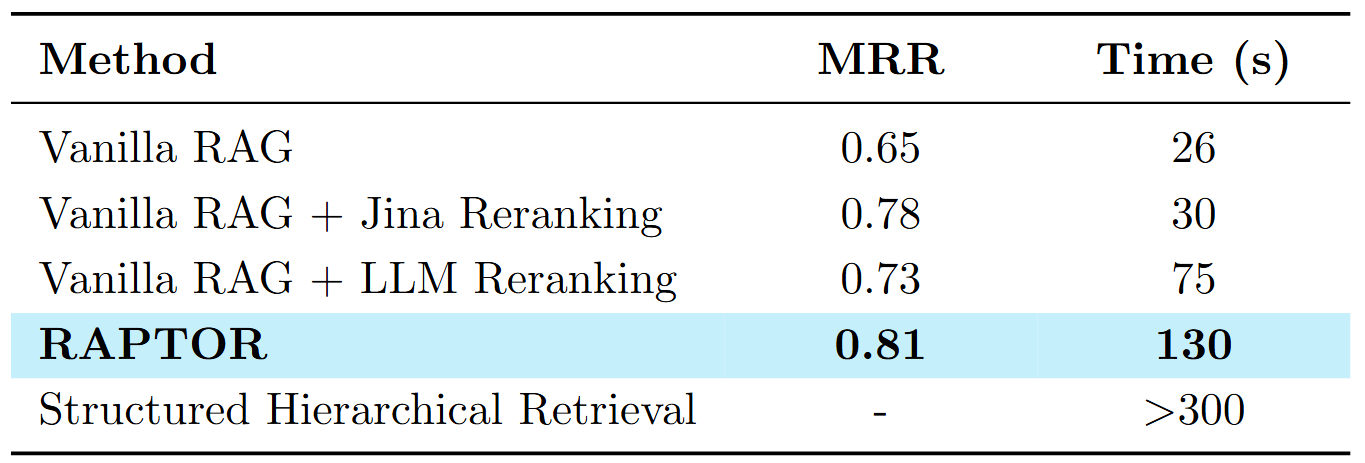
We also experimented with various reasoning methods:
- Knowledge Graphs (KGs): While effective when fully structured, KGs struggle with sparse data scenarios
- Interleaving RAG: This approach bridges the gap by dynamically balancing retrieval and reasoning, outperforming traditional methods like Chain of Thought (CoT) and Tree of Thought (ToT)

Scaling Retrieval Efficiency with HNSW
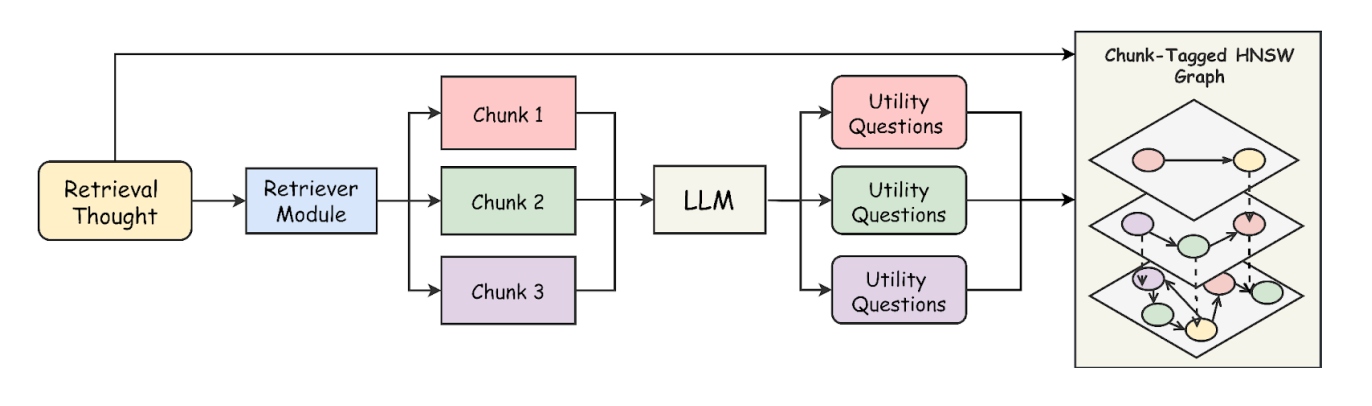
Dynamic Memory Cache Module
To enhance retrieval efficiency in long-document RAG, we built a Dynamic Memory Cache Module using HNSW (Hierarchical Navigable Small World) for fast approximate nearest neighbor search.
For each retrieval query, we extract the top-k most relevant chunks and generate utility queries based on their content. These queries are cross-referenced with the existing query bank to eliminate redundancy. We then construct a dynamic memory cache using nmslib, building an HNSW graph over the utility queries.
This enables efficient retrieval by checking the query bank for similar queries and directly accessing relevant chunks if a match is found. HNSW’s multi-layered graph structure supports real-time updates, making it well-suited for dynamic RAG.
Why HNSW?
- Efficiency in High Dimensions: Unlike tree-based methods that suffer in high dimensions, HNSW maintains efficiency
- Real-Time Indexing: HNSW supports real-time creation and modification of graph indexes, ideal for dynamic systems
- Memory Efficiency: It avoids brute-force comparisons and stores embeddings in a compressed form, reducing storage overhead
How We Use HNSW in Dynamic Memory
- Metadata Tagging: QA pairs, related queries, and retrieved chunks enrich the knowledge base
- User-Adaptive Learning: The system adapts to query history over time
- Lightning-Fast Follow-Ups: Stored query embeddings speed up contextualized retrieval

By combining HNSW with interleaving RAG, we achieve ultra-fast, context-aware retrieval in follow-up queries, pushing long-document retrieval into the future.
Code & Reasoning Agent
Given a set of tools and a problem statement, the primary task of the LLM is to determine the optimal order in which the tools should be executed to solve the given problem. Several algorithms exist for determining tool execution order. React and Code-Driven reasoning methods are the famous one and widely used to determine the order of tools execution.
React is fairly popular; given the list of tools, the task at hand and past observation, it generates a thought, after which it performs the next action in the form of the next tool call and then execute it, after which the LLM is asked to perform an observation keeping mind the tool output returned. This process is repeated until the final answer is reached. Such a methodology allows for improved resistance towards tool failures, however, demands high token counts.
Code Driven reasoning determines the exact tools, in the correct order along with appropriate inputs at once in the form of python function calls, given the task to be performed. This allows for faster inference and token efficiency, but this method suffers from its staticity; any syntax error or tool failure renders the entire code block useless.
Chain of Function Call
It is critical therefore, to achieve the best of both ReAct and Code-Driven Reasoning. More specifically, we need to combine both System 1 thinking and System 2 thinking:
- System 1 reasoning: Spontaneous, stochastic, pattern based
- System 2 reasoning: Slow, Sequence-based, logical reasoning
Analyzing the strengths and weaknesses of ReAct and Code-Driven approaches, we developed the Chain of Function Call (CoFC) method, combining the best aspects of both. The Code & Reasoning Agent is based on a Chain of Function Call tool reasoning paradigm, where at each step, a single python function call is performed, based on the provided list of tools and their description , problem statement , previous history of python function calls and responses. Each tool call is executed using an interpreter to generate the function tool response.
Error Handling and Reflexion in Code & Reasoning Agent
In real-world scenarios, tool failures may occur for a variety of reasons. To ensure system robustness, we have developed mechanisms to handle all kinds of tool failures effectively. These errors are broadly classified into two types:
1. “Loud” Tool Failures
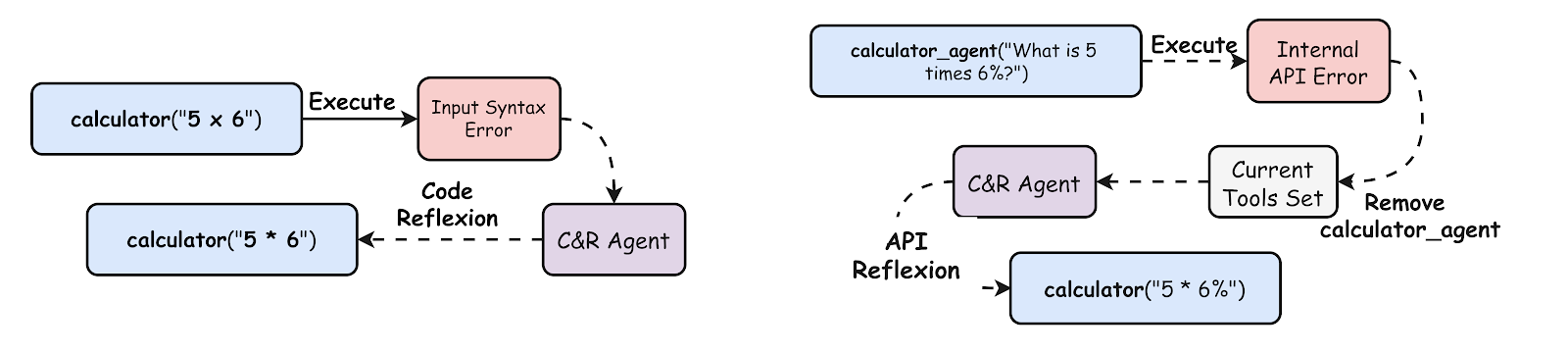
A Loud Tool Failure occurs when executing a tool call generates a Python error or exception. Essentially these errors are immediately visible in the form of execution failures (or loud, so to say), which makes them easier to detect. Loud tool failures can occur owing to the following causes:
1.1. Incorrect Python Syntax
When the LLM generates a function call, it might incorrectly assign argument types, leading to a syntax error. The generated tool call could also be incomplete, which is also a syntax error.
- Resolving such tool failures needs python code correction (LLM reflexion upon the generated code)
1.2. Internal Tool Failure
This refers to the scenario where there is some internal failure in the tool due to issues such as server failures, wrong api keys, etc.
- In case of internal error, we simply remove these faulty tools
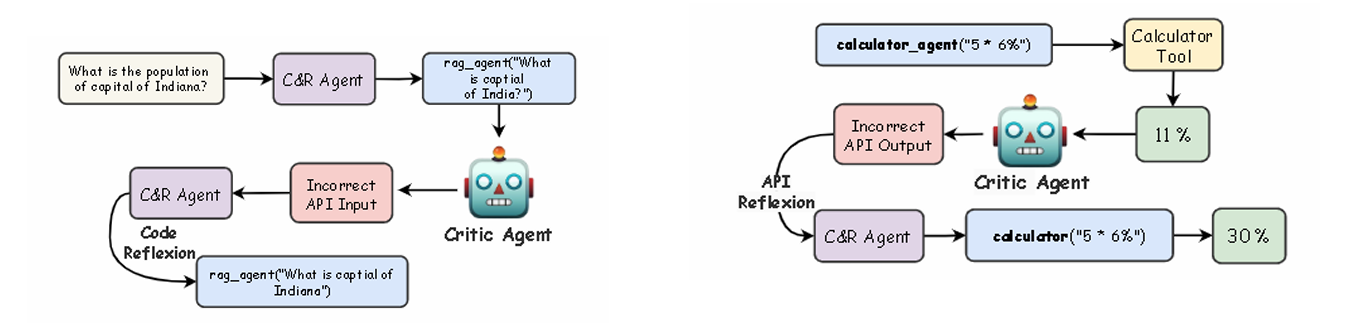
2. Silent Tool Failures:
Silent Tool Failures refer to those tool failures where the tool upon execution does not raise an exception, however, there exist logical inconsistencies that can lead to the failure of the entire tool reasoning procedure that follows ahead. We elaborate on the same below:
2.1. Incorrect Input Argument
This refers to the scenario when the LLM performs the tool call with the correct argument types, but the exact values of the arguments may be logically inconsistent with the reasoning process up till the current point.
- To handle such errors, we have devised a robust mechanism that checks the exact argument values specified by the LLM and checks for any logical inconsistencies
2.2. Incorrect Function Tool Response
This refers to the case where the LLM passes both the correct argument types and values to the tool, but the tool itself has gone rogue, that is, the returned output has no logical consistency with the reasoning procedure up till the current point.
- Again, to handle such errors, the critic agent checks the tool response and its consistency with the reasoning procedure up till the current point
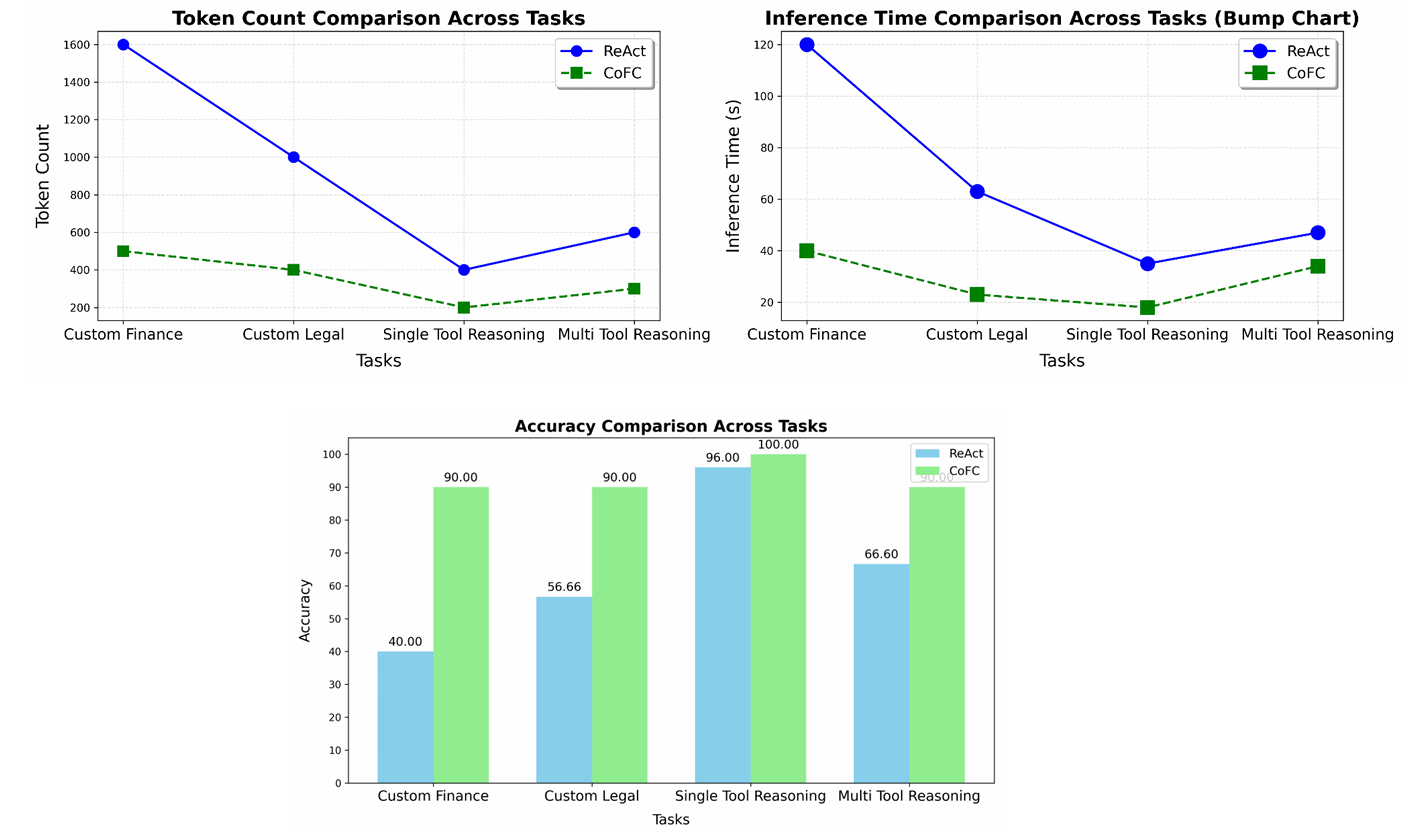
We evaluated custom multi-hop queries on tool reasoning in the Legal and Finance domains using curated datasets: CUAD for legal texts and Finance-10k for financial reports. MetaTool (ICLR 2024), a benchmark for tool usage and selection, was used to test tasks 1 (single-tool reasoning) and 4 (multi-tool reasoning). As a baseline we considered ReAct. Clearly, CoFC is considerably more efficient and also highly accurate. The results are illustrated in the following figures
Dynamic Tool Set Enhancement
While the proposed reflexion policies effectively manage tool failures, there are scenarios where the available toolset may not contain the necessary tools for answering a user’s query, or where all relevant tools are corrupt. We propose two methods to handle such cases:
- Human-In-The-Loop: The supervisor can prompt the user to provide function tools along with proper descriptions in order to address the query
- Dynamic Tool Generator Agent: If no relevant tool is available and the user does not provide one, the supervisor employs a dynamic tool generator to create real-time agentic tools tailored to the user’s needs. It uses a use case driven prompt-refinement algorithm to dynamically generate the appropriate agent to mimic tool response
Conversational Module
In the real world, it can be expected that the user would have multiple queries related to a given document. It is important to develop a component that supports conversations with the user and maintains track of the history of interactions with the user. We have developed the following modules to support conversations:
- Conversational Module: This is a module that supports human-in-the-loop in order to answer any follow-up queries that the user may have. The follow up query is requested from the user and we incorporate the most relevant answers that have already been generated by the Supervisor with the help of the Supervisor Memory Module in the follow-up query
- Supervisor Memory Module: This memory module is implemented as a vector index over the previous history of generated supervisor answers. Once a follow up query is received, we perform retrieval over the memory module and provide the top-k most similar answers along with the follow-up query to aid in rapid-answering of the same
Integration with the Pathway Live Data Framework
We developed a new CodeAndReasoningAgent within the framework’s question_answering module for tool reasoning, that implements the features of the C&R agent described earlier; Chain of Function Call, handling of silent API errors and python syntax errors, and dynamic tool generation.
Conclusion
In this work we present a Multi-Agent Dynamic RAG framework designed for accurate handling of long legal and financial documents. It includes a RAG agent with a retrieval pipeline based on Jina Embeddings, RAPTOR indexing, and the framework's VectorStore, alongside an interleaved reasoning strategy for dynamic retrieval and reasoning decisions. A dynamic memory cache index enables fast retrieval of previously queried information. To manage complex multi-hop queries, we developed a Code & Reasoning Agent that uses the RAG agent and other tools within a dynamic toolset, employing the Chain of Function Call paradigm. Robust tool failure handling, dynamic tool generation, and guardrails ensure effective query resolution while filtering offensive content
If you are interested in diving deeper into the topic, here are some good references to get started with Pathway:
- Pathway Live Data Framework Developer Documentation
- Pathway Live Data Framework App Templates
- Discord Community of Pathway
- Power and Deploy RAG Agent Tools with Pathway
- End-to-end realtime RAG pipeline with Pathway
Authors

Pathway Live Data Framework Community
Multiple authors




