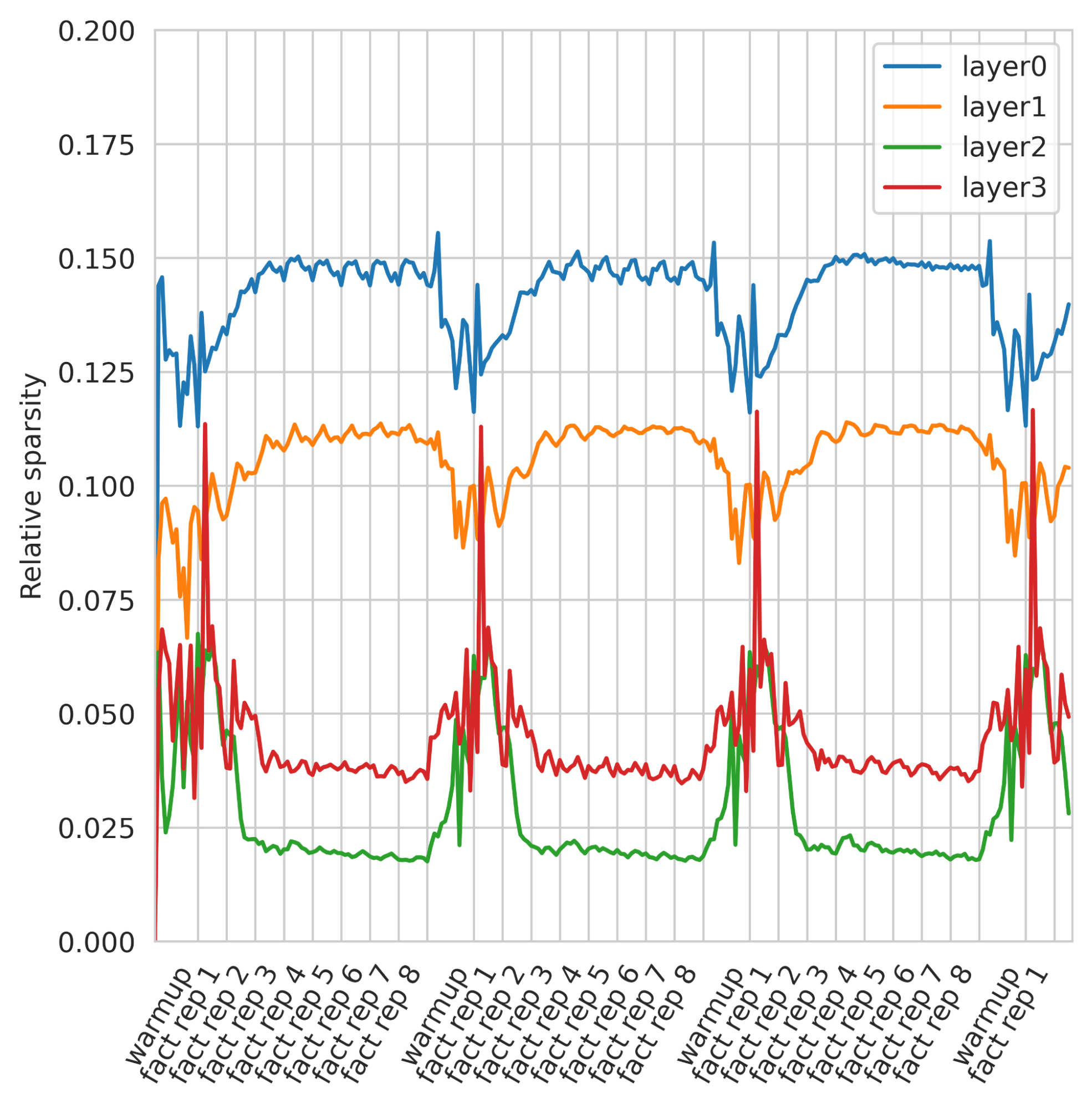
BDH’s context is infinitely long, and efficiently compresses all that was seen, we can measure its size in information content and not in (perhaps repetitive) token count. Neurons in BDH-GPU are less active (signal is sparser) when the input is predictable. The figure shows that BDH holds the past longer, extracting the important bits. When the incoming data is repetitive or low-signal, the model keeps its internal state largely stable rather than “churning” unnecessarily. This means a more efficient use of context.