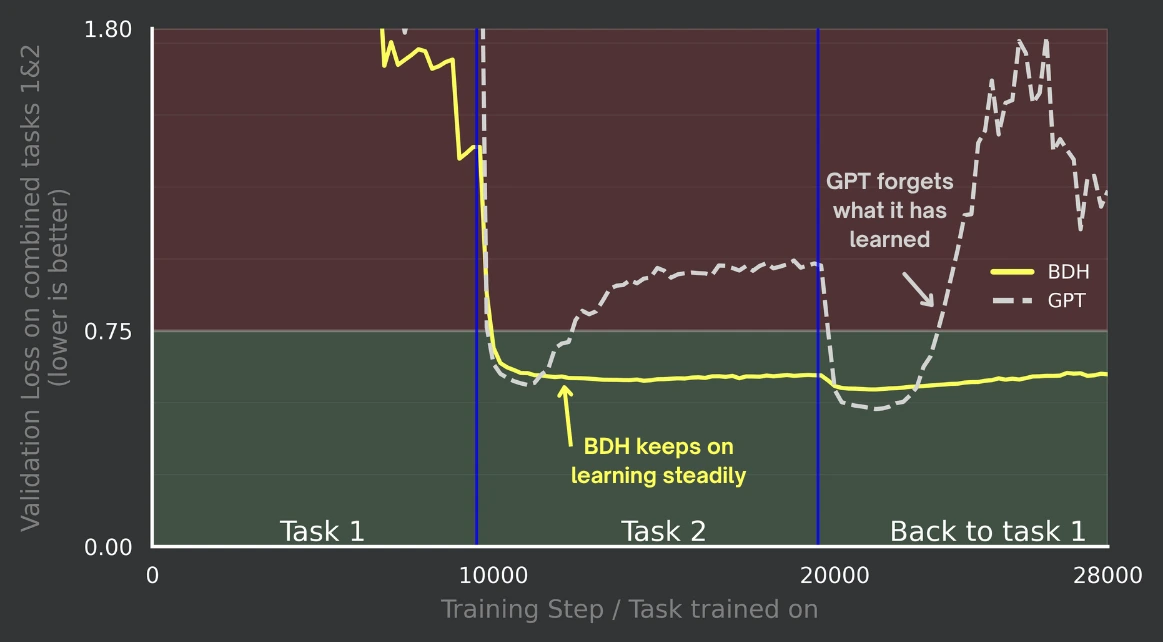
BDH shows no catastrophic forgetting during sequential task training on a 100M parameters scale, maintaining a low and stable combined loss across task switches. In contrast, GPT (Transformer) degrades after each switch - its loss rises after moving to Task 2 and spikes when returning to Task 1 - indicating disrupted retention and catastrophic forgetting.